⚠️ Important information
All models already include the Lightning LoRAs, except the SVI models, where Lightning is not included.
Do not use additional Lightning LoRAs on models that already have Lightning integrated, or the quality will be degraded.
For SVI models, you can use Lightning LoRAs if you want faster video generation.
2or3 ksampler (for svi) https://civarchive.com/models/2079192?modelVersionId=2668801
v2.1 (for nsfw v2) https://civarchive.com/models/2079192?modelVersionId=2562360
v2.1 with MMAUDIO (for nsfw v2) by @huchukato https://civarchive.com/models/2320999?modelVersionId=2613591
Another wf triple KSampler KSampler https://civarchive.com/models/1866565/wan22-continuous-generation-svi2-pro-or-gguf-or-32-phase-or-upscaleinterpolate-w-subgraphs-and-bus?modelVersionId=2559451
triple KSampler wf setup allows for more motion and helps prevent slow-motion issues. In exchange, your videos will take longer to generate.
For those having issues with my SVI workflow , you can try Kijai's wf here: https://github.com/user-attachments/files/24364598/Wan.-.2.2.SVI.Pro.-.Loop.native.json. Alternatively, you can try fmlf wf https://github.com/wallen0322/ComfyUI-Wan22FMLF/tree/main/example_workflows they will be simpler. There are others on Civitai that work very well too.
Qwen-VL workflow as an alternative to Grok for creating your dynamic NSFW prompts. Thanks @huchukato for his work: https://civarchive.com/models/2320999?modelVersionId=2611094
🟣 SVI Update – NSFW
⚡ Model Presentation (SVI-compatible version)
This update was made because the NSFW V2 models were not fully compatible with SVI LoRAs.
This version was created to work smoothly with SVI, while still functioning without them (though the workflow must be adapted).
Be careful, SVI LoRAs will only work with a workflow specifically designed for them, otherwise, it won't work.
There are two models available for SVI:
✔ Fast Move (FM) – Sexual scenes may differ from the Consistent Face model and will generally be faster.
✔ Consistent Face (CF) – Slightly better image quality, which may be preferable for anime-style videos; sexual scenes differ from Fast Move, but the difference is minimal.
You can also mix models between High and Low LoRAs:
FM (Fast Move) as High + CF (Consistent Face) as Low
CF (Consistent Face) as High + FM (Fast Move) as Low
Both combinations work and give slightly different results, offering more flexibility for your videos.
For this version, the main improvements include:
✔ Fully adapted for SVI LoRAs
✔ Greater flexibility: Lightning and SVI LoRAs must be loaded manually for custom workflows
🟣 SVI LoRAs – Strengths & Weaknesses
⚡ Overview
✅ Strengths
Best solution for making long videos
Excellent transitions between video segments
Reduced degradation compared to other solutions
Strong character coherence: the model retains information from the previous video, helping maintain consistency
⚠️ Weaknesses
Weaker prompt understanding
Weaker camera understanding
Videos are less dynamic
Sometimes slow-motion effect
(can be improved with proper Lightning LoRAs, dynamic prompts or triple ksampler)
🟣 SVI LoRAs – Download Links
⚡ Download
Note: Both LoRAs must be loaded manually in your workflow.
🟣 Suggested Lightning LoRA Combos (Optional)
⚡ Overview
You don’t have to use these Lightning LoRA combos. They are optional and allow you to fine-tune motion and degradation.
You can also use other Lightning LoRAs or assign different combos per video for more control.
🔥 Combo 1 – More Motion (Rapid Video Degradation)
High LoRA →
https://huggingface.co/Kijai/WanVideo_comfy/blob/709844db75d2e15582cf204e9a0b5e12b23a35dd/Lightx2v/lightx2v_I2V_14B_480p_cfg_step_distill_rank128_bf16.safetensors
Weight: 4
or
💜 Combo 2 – Less Image Degradation
or
or
🟢 Combo 3 – Balanced Motion / Moderate Degradation
High LoRA →
https://huggingface.co/Kijai/WanVideo_comfy/blob/709844db75d2e15582cf204e9a0b5e12b23a35dd/Lightx2v/lightx2v_I2V_14B_480p_cfg_step_distill_rank128_bf16.safetensors
Weight: 3
Low LoRA →
https://huggingface.co/Kijai/WanVideo_comfy/blob/709844db75d2e15582cf204e9a0b5e12b23a35dd/Lightx2v/lightx2v_I2V_14B_480p_cfg_step_distill_rank128_bf16.safetensors
Weight: 1.5
🧠 Advanced Usage Tip
You can disable global Lightning LoRAs (in my wf) and assign different combos per video:
Combo 1 for Video 1, Combo 3 for Video 2, Combo 2 for Video 3.
Each combo produces different motion and degradation behavior.
If you want to create several-minute-long videos while maintaining high quality, it is possible, but it will take a very long time. You just need to avoid using Lightning LoRAs and use the full model instead.
🧠 Dynamic Prompts – Better Control & More Motion
You can use dynamic prompts to have better control and this helps to make the video more dynamic.
You just need to give this example prompt to an LLM like ChatGPT. It will be enough for it to describe the image you have and what you want as a video while keeping the same structure of the prompt in the following example.
⚠️ This will be a NSFW prompt; ChatGPT will not accept it.
You can use GROK https://grok.com, which can make NSFW prompt modifications.
For more examples of prompts with different poses, check:
Enhanced FP8 Model.
Give these prompts to GLM with the dynamic prompt structure if you want.
Example 1
(At 0 seconds: Wide shot showing a slightly overweight man casually walking down a city street, camera fixed in front, urban environment with buildings and cars.)
(At 1 second: Suddenly, a massive shark bursts from the pavement ahead, looking terrifying at first, pavement cracking, dust and debris flying, camera from side angle.)
(At 2 seconds: Medium shot from the side, the man stumbles backward in shock, while the shark dramatically slows down and strikes a comically exaggerated sexy pose, revealing large, exaggerated shark breasts, covered by a colorful bikini.)
(At 3 seconds: Close-up on the man’s face, eyes wide in disbelief, as he turns to look at the shark, small cartoon-style hearts floating above his head to emphasize his amazement, camera slightly low-angle.)
(At 4 seconds: Dynamic travelling shot showing the man frozen in the street, the shark maintaining its sexy pose, water splashes and debris still moving realistically, urban chaos around.)
(At 5 seconds: Wide cinematic shot pulling back, showing the man standing in the street, staring at the bikini-wearing shark with hearts above his head, epic perspective highlighting absurdity and humor.)
Example 2 – Anime NSFW
(At 0 seconds: The couple in a cozy bedroom, anime style, soft lighting highlighting their intimate embrace, her back arched slightly as he positions himself.)
(At 1 second: The man’s hips moving rhythmically, the head of his penis sliding effortlessly into her vagina, her body responding with a gentle, fluid motion, anime-style motion lines emphasizing the smooth penetration.)
(At 2 seconds: Her back arching deeply against him to intensify the pleasure, hips swaying with each thrust, breasts bouncing subtly, small hearts floating around them to capture the erotic energy.)
(At 3 seconds: Her face, eyes closed in bliss, a soft moan escaping, hands resting behind her head, anime-style blush on her cheeks, the air filled with a seductive aura.)
(At 4 seconds: The man penetrating her deeply, her body moving in sync with his, the bed sheets slightly rumpled, the room’s warm lighting enhancing the intimate, lustful atmosphere.)
(At 5 seconds: The couple locked in a passionate embrace, the scene exuding vibrant, seductive energy, anime style with smooth lines and soft shadows.)
🟣 Lightning Edition – NSFW I2V V2
⚡ Model Presentation (2 new versions available)
I originally planned to release only one V2, but some people preferred the NSFW V1 over the Fast Move V1 version, so depending on what you’re looking for, one version may suit you better than the other.
For these V2 versions, I tried a new approach:
✔ I made sure that most sexual poses work, while the model is also good for SFW content
✔ More flexible for general use
🔥 NSFW Fast Move V2
Improvements included in this version:
Better prompt understanding
Better camera understanding
Reduced unnecessary back-and-forth movements outside sexual poses
(cannot be completely removed, but strongly reduced)Improved bounce effect on the buttocks
If a man appears, he will no longer automatically attempt to penetrate the woman when she is nude
This version is designed for those who want more dynamic scenes with more movement.
💜 NSFW V2
The difference between this version and NSFW Fast Move V2:
Less camera control
Less camera understanding
But body movements are less pronounced (breasts and buttocks)
Some preferred V1 NSFW to V1 NSFW Fast Move, and this version keeps that spirit
For varied sexual poses, check the previews — there are many.
You can use the shown prompts and adapt them to your images, but of course, other prompts will work as well.
Don’t hesitate to use other LoRAs for creating specific concepts.
🔧 Recommended Settings
Steps: 2+2
(Jellai recommends 2+3 for even better results, and I agree)Sampler: Euler simple
CFG: 1
This model already includes the Lightning LoRAs, don’t use them, or the quality will be degraded
You need to download both models: H for High and L for Low.
Here is an example made with the base workflow + the First/Last Frame workflow + upscaler (only on the starting images) + inpainting (cum).
https://civarchive.com/images/114733916
🔞 LoRA Examples (with links and recommended weights)
LoRA: Penis Insert WAN 2.2
LoRA weight: 1
Face → Doggy
https://civarchive.com/images/112864483Face → Missionary
https://civarchive.com/images/112864718
https://civarchive.com/images/112864835Face → Doggy (leg aside)
https://civarchive.com/images/112864885Another example
https://civarchive.com/images/112864972
Other examples with different LoRAs
Face → Reverse Cowgirl — LoRA weight: 0.7
https://civarchive.com/images/112865189Face → Cowgirl — LoRA weight: 0.5
Face → Missionary — LoRA weight: 0.3
https://civarchive.com/images/112865381Face → Missionary — LoRA weight: 0.5
Face → Doggy leg aside — LoRA weight: 0.6
https://civarchive.com/images/112865551Face → Doggy — LoRA weight: 0.7
https://civarchive.com/images/112865696Face → Spoon — LoRA weight: 0.7
https://civarchive.com/images/112868124
Recommended LoRA to obtain a very realistic vagina and anus:
https://civarchive.com/models/2217653?modelVersionId=2496754
💡 Tip for Anime Style:
If you’re working in an anime style, feel free to follow the advice of @g1263495582 thanks to him for this.
Try these LoRAs together or separately; they help maintain face consistency:
🔹 Note:
For these LoRAs, use only Low Noise.
For the examples mentioned above, use High and Low Noise as indicated.
LoRA weight: 0.3
Many things can be done with the model, but don’t hesitate to use other LoRAs for specific purposes. And don’t hesitate to lower the LoRA strength to preserve the face as much as possible.
📷 Dynamic prompt example with different camera angles:
(at 0 seconds: wide shot showing the woman standing in the snowy plain, a massive giant dragon emerging behind her, snow cracking and dust rising).
(at 1 second: the woman jumps backward onto the dragon’s back as it bursts fully from the sky, camera tracking the motion from a side angle, debris and snow flying).
(at 2 seconds: medium shot from the side, the woman balances heroically on the dragon’s back as it begins to run forward across the snowy plain, slow-motion on her posture).
(at 3 seconds: close-up on the woman’s determined face, camera slightly low-angle to emphasize her heroic stance, snow and debris flying around).
(at 4 seconds: dynamic travelling shot alongside the dragon, showing the snowy plain, scattered debris and ice fragments flying everywhere as it gains speed).
(at 5 seconds: wide cinematic shot pulling back, showing the dragon taking off with the woman riding on its back, soaring above the snowy plain, epic perspective with snow, wind, and scale emphasizing the drama).
For available camera angles, check further down in the “cam V2” model description.
🔞 Normal Clip vs NSFW Clip:
You can also use the NSFW version for your clip.
It can bring positive effects for sexual scenes, but it can also cause issues, as in this example:
NSFW Clip:
https://civarchive.com/images/112864204Normal Clip (same seed):
https://civarchive.com/images/112864295
Here are the links to NSFW clips (thanks to zoot_allure855 for correcting the BF16 version):
BF16 fixed version:
https://huggingface.co/zootkitty/nsfw_wan_umt5-xxl_bf16_fixed/tree/mainFP8 version:
https://huggingface.co/NSFW-API/NSFW-Wan-UMT5-XXL/tree/main?not-for-all-audiences=true
❓ If you have any questions, don’t hesitate to ask!
Many people ask me for help via private message. You can do that, no problem, but I would appreciate it if you could do it in the comment section, it could help other people. Thank you.
🟣 Lightning Edition – NSFW I2V camera prompt adherence
⚡ Model Presentation (2 versions available)
I decided to release 2 versions. Both can produce different results, as you can see in the previews (the seed was the same).
Fast Move Version: provides more movement, and the movements will be faster, with better prompt understanding and camera handling
(you can see it in the 4th preview "fast move high" where the man slaps the woman)Natural Motion Version: offers more natural breast movements depending on the situation and produces slower scenes.
👉 Check both and choose the one that works best for you.
This NSFW edition is, of course, focused on sexual poses.
You should achieve very good results.
To create specific concepts, feel free to use specific LoRAs — they work very well with this model.
🔧 Recommended Settings
Steps: 2+2
(Jellai recommends 2+3 for even better results, and I agree)Sampler: Euler simple
CFG: 1
This model already includes the Lightning LoRAs, don’t use them, or the quality will be degraded
You can also use this T5, which may improve understanding:
https://huggingface.co/NSFW-API/NSFW-Wan-UMT5-XXL/tree/main?not-for-all-audiences=true
📝 Usage Tips
Start with a clean, high-resolution image for better results.
The model will not change the face; if it does, increase the resolution.
Also adjust your prompt if you are not getting what you want.
Wan understands some terms well, but not all.
For prompts, check the video previews: adapt them to your image.
Other prompts will work too.
🎥 Training
I trained 2 LoRAs:
The first one using several videos and images of different sexual positions.
The second one to bring more dynamic motion.
Respect to everyone who creates this type of LoRA — it requires a lot of work.
🙏 Credits
This model wouldn’t exist without the incredible work of these creators:
alcaitiff : https://civarchive.com/models/1295758/nsfw-fluxorwan-22orqwen-mystic-xxx?modelVersionId=2300332
Sweet_Pixeline : https://civarchive.com/models/1844313/penis-play-wan-22
anonimoose : https://civarchive.com/models/2008663/slop-twerk-wan-22-i2v
dtwr434 https://civarchive.com/models/1331682?modelVersionId=2098405
A special thanks to Alcaitiff and CubeyAI, two very kind and humble people.
🔔 Important
Please don’t support my work with buzzes here, I don’t need it.
If you want to support someone, support the creators listed above — they truly deserve it.
💬 Feedback
Feel free to give me feedback, positive or negative, to help improve future updates.
Update WAN 2.2 V2 CAM I2V – NEW feature Camera & Prompt Improvements
This custom version of WAN 2.2 I2V has been updated to deliver better prompt comprehension and improved handling of camera angles and cinematic movements. It provides more accurate scene interpretation, smoother transitions, and enhanced control over dynamic.
Key Features:
Excellent understanding of prompts and scene composition.
Supports various camera angles and movements, including zoom, dolly, pan, tilt, orbit, tracking, and handheld shots.
Ideal for cinematic storytelling, animated sequences, and creative video-to-image projects.
Flexible multi-step prompts, standard 4 steps (2+2), can be increased for higher fidelity.
Recommended sampler: Euler simple.
You can, of course, use your usual prompts; this is just one example among many.
Example Prompt with Different Camera Angles
(at 0 seconds: wide frontal shot of a man standing in front of an open fridge, cinematic lighting, subtle ambient kitchen reflections, the fridge contents visible, camera static).
(at 1 second: medium shot from the front as he opens the fridge fully, reaches for a can, slight zoom-in to emphasize the action, cinematic framing).
(at 2 seconds: camera shifts to a side medium shot, tracking him as he lifts the can to his mouth, fluid movement, maintaining lighting and reflections).
(at 3 seconds: camera starts a smooth 360-degree orbit around the man, following him as he drinks from the can, motion fluid, background slightly blurred for cinematic effect).
(at 4 seconds: close-up on his face and upper body while drinking, orbit continues subtly, fridge reflections accentuating realism, cinematic polish).
(at 5 seconds: final wide shot as he lowers the can, camera completes orbit to original angle, showcasing the kitchen space, lighting, and dynamic movement).
Available Camera Movements
Zoom / Dolly
zoom in
zoom out
camera zooms in on subject
camera zooms out gradually
dolly in
dolly out
camera dollies in slowly
camera dollies out steadily
crash zoom
Pan
pan left
pan right
camera pans across the scene
gentle pan left
sweeping pan right
Tilt
tilt up
tilt down
camera tilts up to reveal…
camera tilts down from…
Orbital / Tracking / Arc / Rotation
orbit around subject
360° orbit
camera circles around
tracking shot
camera tracks alongside subject
arc shot
curved camera movement
Other Movements & Styles
static camera / static shot
handheld shot
camera roll
Note:
LoRAs work perfectly with this model, offering full compatibility and consistent results across styles and concepts.
# SUPPLEMENTARY ADVICE
You can use negative prompts, but be careful: this will double the generation time.
Only use them if you really want to prevent something from appearing in your video.
In that case, enable the corresponding node; otherwise, keep it disabled.
⚠️ Important
The model must be used with CFG set to 1, so negative prompts do not work by default.
However, there is a simple way to enable them.
How to enable negative prompts:
Open the Manager
Search for kjnode and install it
In your workflow, add the WAN Nag node
To use it correctly:
Connect this node after the LoRA Loader
Feed it with the negative prompt
Then connect it to the first kSampler (High)
👉 Only use this option when necessary, to avoid unnecessarily increasing generation time.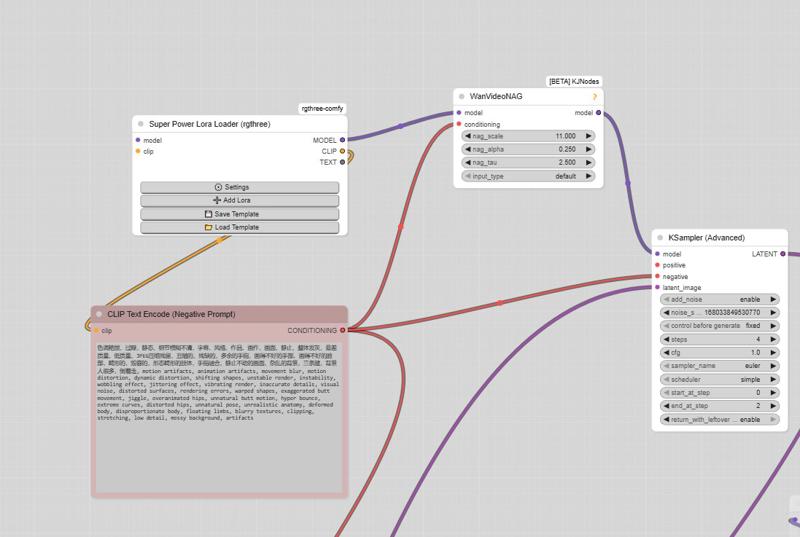
And here is the negative prompt for unwanted movements:motion artifacts, animation artifacts, movement blur, motion distortion, dynamic distortion, shifting shapes, unstable render, instability, wobbling effect, jittering effect, vibrating render, inaccurate details, visual noise, distorted surfaces, rendering errors, warped shapes, exaggerated butt movement, jiggle, overanimated hips, unnatural butt motion, hyper bounce, extreme curves, distorted hips, unnatural pose, unrealistic anatomy, deformed body, disproportionate body, floating limbs, blurry textures, clipping, stretching, low detail, messy background, artifacts, butt bounce, moving hips, swinging hips, shaking butt, wiggling butt, moving lower body, moving pelvis, jiggling buttocks, bouncing butt, unstable stance, unnatural hip motion, exaggerated hip movement, hip sway, hip rotation, bottom motion, pelvis motion, wobbling hips, fidgeting lower body, dancing hips, pelvic movement, motion blur, unnatural movement
And here is the negative prompt from the official ComfyUI workflow:色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走
Note: If you use the default workflow without the node, this negative prompt will not work.
UPTDATE: Lightning Edition – T2V
I’m not really experienced with T2V myself, but a colleague who works with it a lot tested this version and confirmed that it performs very well. From the few tests I managed to do on my side, I got the same impression, although I haven’t compared it directly with the base version yet.
The settings are the same as in the image-to-video version: 2+2 steps or more if you prefer, CFG at 1, and Euler simple (though other samplers also work great).
I don’t plan to make an NSFW version for the T2V release,
but for the I2V version, I’m already quite happy with the first results.
Update WAN 2.2 V1.1 I2V
Updated version of the original Lightning merge — same settings 2+2 steps or more, featuring more movement and smoother flow (depending on the prompt).
The model already works very well in NSFW. Just use the right LoRAs, and the movement will improve.
WAN 2.2 V1 I2V
This checkpoint is based on the original WAN 2.2, with the Lightning WAN 2.2 and Lightning WAN 2.1 LoRAs already integrated. This improves image quality, makes motion smoother and more dynamic, and removes the slow-motion effect that can occur with the Lightning models.
A common setup is to use 2 steps on the high model and 2 steps on the low model, though other settings may work as well. Do not apply the Lightning LoRAs manually — they’re already included in this checkpoint.
My workflow
https://civarchive.com/models/2079192/wan-22-i2v-native-enhanced-lightning-edition
Description
FAQ
Comments (193)
Man, you made a great and versatile model! The effects are real impressive. Keep up your work because you do an awesome thing.
I'm guessing this nsfw version is only for sex acts? Because in my generations, 2 characters always try to perform thrusting sex motion on each other even though I don't prompt it in.
For example if I get 2 characters to kiss each other, they will automatically try and hump each other at the same time when that is not what I prompted or wanted to happen. This happens for all scenarios I try to generate.
Can i ask why is everyone laughing at my comment? Did i do something wrong that is simple? Thanks.
@grasshopper85116 Lol, people just have to imagine your video. Which clip are you using? The NSFW one?
If you put 'a man and a woman kissing' in your prompt, it doesn't work? I've already made a few videos with NSFW models where this happens and I didn't have any issues, but it might depend on the image.
@taek75799 i think I am using clip_vision_h have to double check when i get hom
Is is possible to train my own lora in AI Toolkit using this gguf as base model? If it is, could someone guide me a little what should I set in AI Toolkit?
No
Anime Gooner Here... v8 does a much better job keeping the original facial features of the subject so awesome job. I did notice when going from 5 to 10 sec video, when it transitions, for anime, it does change the face. Ill try VACE and see if that formula works after getting two 5 sec clips separately.
i went back and forth across a bunch of wan models (mostly base), and yours is honestly a standout.
what youre nailing
1. prompt adherence: 9.5/10
follows instructions better than most base wan models i tested
2. identity retention / character specifics: 9/10
face + details stay surprisingly consistent (way above average)
the big issue (and its consistent in my tests)
3. face burn / fast color degradation: 3/10
i can say with 100% certainty: this model burns the face very fast. it often starts within the first few frames.
if you zoom in early, you can already see more color degradation than other base models.
i know all wan models have some color shift from encode → decode, but this one has a specific “burn” effect thats way more aggressive and looks like something is amplifying the degradation.
why im still posting this (constructive)
4. overall potential: 10/10
because the adherence + identity retention are so good, i really think its worth doing a proper a b split test to find where the burn starts and what triggers it.
now that we have reliable extension workflows (wan 2.2 + svi pro), its finally easy to run a big sweep, even going back to earlier checkpoints and isolating or removing loras that might be causing the fast burn.
tldr
amazing adherence + identity retention, but face burn happens very fast. if you can reduce that, this could easily become a top tier wan model (sfw + nsfw).
also: i genuinely appreciate the work here, im pointing this out because i think its close to being insanely good.
Hello and thank you for your analysis. I appreciate every critique; it allows me to fix flaws in a possible future update.
I created a few scenes using Daz Studio. However, one thing ruins the clips: P.... becomes so unrealistically large that any woman would run away. P.... deviates significantly from the original and keeps getting bigger, often reaching a length of 50 cm.
I think it would be better to animate it yourself
where do i find the low noise model?
Hi
At the risk of sounding stupid, where in the workflow do I add a prompt?
Thanks
In the three green text boxes labeled "first prompt", "second prompt" , "third prompt". Each is for a separate prompt to make three different videos/scenes that get combined together at the end.
@xBLTx Thanks for replying. I'm not seeing any green text boxes. I'm using the "wan2.2_LIGHTNING-EDITION_long-video_FP8GGUF.json" workflow from the download link at the top of the page. Should I be using a different one?
@CloddleDon That is the same one I have. That is very strange that you cant see the text boxes, that has never happened to me so far. I'm sorry, I do not know the answer then. :(
@xBLTx Well, at least I now know I'm using the correct workflow. I'll keep trying to find out what's going on, thanks for the help, appreciate it :-)
@CloddleDon Hello, in the subgraphs, there is the text area.
@taek75799 Hi, in the New Subgraph area I see: model, model_1, model_2, model_3, clip, vae, start_image, width, height, motion_amplitude, correct_strength. Hidden underneath that panel I see: Get_model HIGH, Get_model Low, Get_CLIP, Get_LENGHT, Get_VAE, Get_LOAD IMAGE1, Set_MODEL SAMPLING L, Set_MODEL SAMPLING H, Get_COLOR PROTECT, Get_FIRST LORA LOW, Get_FIRST LORA HIGH, Get_HEIGHT, Get_WIDTH, Get_MOTION AMPLITUDE.
I'm not seeing anywhere for text. I downloaded the workflow again to be sure I hadn't changed anything.
The worklfow is working but I just can't see anywhere for a prompt.
@CloddleDon So I guess you don't see this: https://ibb.co/N2N0V1wY. Try right-clicking on the subgraph and choose 'edit subgraph'. Here, you can choose what you want to add to the subgraph areas: the top section is what will appear, and the bottom is what is hidden. Add the texts to the top. If that doesn't work, you can unpack the subgraph to see if the text encoders are actually inside.
@taek75799 Hi, thanks for the detailed reply. I had to unpack the subgraph to see a text prompt box, but only one was displayed. I downloaded the workflow again but this time from the NSFW V2 Q8 Low tab and this one has the three text prompt boxes all there. All working. Thanks for the help and the great work in making all this.
Can't seem to get the included workflow running, after loading in the V2Q8 high/low models and running I receive error:
ValueError: [GetNode] ✗ Variable 'model HIGH' not found!
Available: LOAD IMAGE1, CLIP, MODEL, MOTION FRAME, MOTION AMPTITUDE, COLOR PROTECT, LENGHT, VAE, HEIGHT, WIDTH
Tip: Make sure SetNode runs BEFORE GetNode in the graph.
Any help would be appreciated
Nsfw v2. I have discovered a weird behaviour. If some touching body parts, no matter what they are, and they are seperating in the video, it generates schlongs.
For example In prone bone position, if woman'a leg touches man's butt and if a gap forms between them as they move, it generates a mangled schlong.
Is it possible to do one without lighting baked in? I ask because my understanding is lighting kills the ability to use negative prompts. Unless yours works with them because its baked in and not in a lora?
Hello, check the description to see how to enable the negative
Thanks. How well does this work with SVI?
I have never tried it with SVI, SVI it doesn't understand positive prompts as well, so I imagine it must be the same for the negative ones.
Hello! Your work is great! But i got question. I'm creating video turning on "10 seconds" parameter. What promt i must use, to hold action in the end video, second promt in "Video 2 10 sec"? Scene acting, but don't stop in the end.
For example - blowjob scene. Action starting, in the end man holding his penis full in mouth.
Help please!
Hi, and thanks for your feedback. To be honest, I don't know—I haven't tried everything yet. If it doesn't work, try using different words; Wan understands certain specific words well, but struggles with others.
@taek75799 i just want to do video like that. https://civitai.com/images/117009814
Author send me promt, and i do everything like he told. "Video 10SEC" - on"Video 15SEC" - on, and "lenght" - 81.
Maybe other my settings is wrong? "Motion amplitude - 1.3", "motion frames - 5", "frame_rate - 16", "UPSCALE 16FPS" - on. And i need set "seed" on -1 for random? Can you help for base setting please?
P. S. Your work is great! I just want to lern how doing projects with your checkpoint :)
@dementymail195 Try this prompt1:
she engages in a deep throat blowjob, , she engages in a deep throat blowjob, she swallows the penis all the way. Her lips touches the man's groin. Her nose smashes against the man's hips.
prompt 2:
(At 0 seconds: Wide shot showing a woman calmly licking a man's glans; soft atmosphere, static camera, subtle lighting).
(At 1 second: The woman licks the man's penis, beginning a slow, controlled movement. The camera begins a slow rotation to the left.)
(At 2 seconds: She takes the penis in her mouth and performs fellatio, slightly adjusting her posture. The camera continues its smooth rotation.)
(At 3 seconds: The man withdraws his penis from the woman's mouth, the glans is visible, and ejaculates on her face. Expressive yet gentle, she glances discreetly at the camera. The camera continues its steady movement.)
(At 4 seconds: The atmosphere intensifies without being explicit; precise movements, cinematic framing, still a slow rotation.)
(At 5 seconds: The final shot shows the woman, her face dripping with semen, in an expressive pose, immersive atmosphere, the camera completes its rotation, ultra-detailed and cinematic rendering.)
@taek75799 If in not so hard to you, can you help with "promt 3" ?
1 promt is grate, but how i need split 2 on two parts, to part 3 in the end?
In promt 3: "man need to fully stop, penis all the way in her mouth, and little saliva dripping from her mouth."
And, how you create promt 2? With Grok or ChatGPT, or by yourself?
I need a 15-second video.
P.S. Thank you for helping with promt, and sorry if i bothering you. Just want to learn how doing this promt :)
@dementymail195 Try this prompt. I'm not sure if I fully understood, but let's say that with this prompt, depending on the seed, the woman might take the entire penis in her mouth and stop moving for the rest of it. Try to adapt the prompt to whatever you're looking for: https://civitai.com/images/110324436
When you make v3, don't add slop twerk, instead add slop bounce. Gives much better butt motion/jiggle physics...
Thanks a lot for this, best I2V ckpt I used till now, I stopped to fill my pod with Loras coz almost everything just works with a good prompting, 2+3 steps as you suggested, the only thing that take tons of time is upscaling, I generate ad 480x720 and I'm testing various upscale models but often I go OOM also on a 4090, which model you suggest for upscaling?
Hi, I have 16GB of VRAM and 64GB of RAM, and I always use Q8 because it offers the best quality. I can go up to 1024x1024 for square videos; you shouldn't have any trouble doing the same. For upscaling, I think I've tried 1024x2, which is 2048. Try checking your Windows paging file settings for virtual memory—it helps a lot.
I got you here brother, you search TensorRT upscaler in comfyui custom nodes, let it install tensorrt and polygraphy takes a little time. Then when its installed u insert the node and the model selector and you pick fp16 and clear reality(SPAN architecture). It will then automatically create the engine and will re-use after first time, will not take too long since SPAN is incredibly lightweight but still does amazing upscaling for really low compute requirements. Believe its like 250mb for x4 upscaling from 512x512. GL!
Thanks a lot, I just tryed RealESRGAN_x2plus (found searching around) and it seems working good coz you do not have to link it to the Upscale Image By node to set 0.50 as when you use a 4x upscale model, now for a 5s vid including upscale and interpolation it takes just 3 mins, I try a 20s one later, btw I really love the ckpt dude <3 amazing job
Get this error: All available backends failed to load the model '/root/SwarmUI/Models/diffusion_models/wan22-model-2367780.gguf'.
Possible reason: Model loader for wan22-model-2367780.gguf didn't work - architecture ID is missing. Please click Edit Metadata on the model and apply a valid architecture ID.
This is after editing the metadata, adding the civitai link, loading, etc. On both high and low. Doesn't work. Shame. I'm using SwarmUI bc comfy is giga aids. If you have a solution would love to hear it. If you have a user guide for ppl without 100 hours to invest into learning comfy even better, happy to pay.
Hi, sorry, I don't use SwarmUI at all. I hope someone else can help you. What I can suggest is trying another model like Q6_K_M, Q8, or FP8 to see if this error occurs with all models.
The recommended Lora for genitals is no longer
One question. How do you prompt a proper creampie with this model, ejaculation. As much as i tried it ended up shooting load from the mouth, or dude in video bends over and spits a load from his mouth....
Alguém consegue me ajudar? Estou tendo resultados muito ruins, parece que o input da imagem fica com uma resolução muito ruim, consequentemente a geração fica pior.
Exemplo de como a imagem input fica (primeiro frame do video, depois piora)
https://prnt.sc/f-qjRyTyv4Kf
Mesmo eu colocando imagens com resolução alta.
Ja tentei de varias maneiras, com o workflow que esta anexado nessa pagina, testei em outros, a wan22 padrao fica sem nenhum problema, e ja testei duas versoes do wan22 NSFW (wan22EnhancedNSFWCameraPrompt_nsfwFASTMOVEV2Q8H.gguf e wan22EnhancedNSFWCameraPrompt_nsfwFASTMOVEV2FP8H.safetensors) e continua do mesmo jeito...
Eu tenho um hadrware bom para isso (RTX 4070 TI SUPER e I9 14400K), creio que seja algum detalhe, fazendo varios testes junto ao Grok para entender o problema e nada, inclusive testei com e sem os loras, com e sem loras light, etc...
Can anyone help me? I'm getting very bad results; it seems the image input has a very poor resolution, consequently making the generation worse.
Example of how the input image looks (first frame of the video, then it gets worse)
Even when I use high-resolution images.
I've tried several ways, with the workflow attached to this page, I've tested others, the standard wan22 works without any problems, and I've already tested two versions of wan22 NSFW (wan22EnhancedNSFWCameraPrompt_nsfwFASTMOVEV2Q8H.gguf and wan22EnhancedNSFWCameraPrompt_nsfwFASTMOVEV2FP8H.safetensors) and it's still the same...
I have good hardware for this (RTX 4070 TI SUPER and I9 14400K), I believe it's some detail, doing several tests with Grok to understand the problem and nothing, including testing with and without Loras, with and without Loras Light, etc...
Hi, you need to download both the 'High' (H) and 'Low' (L) models.
@taek75799 I realized this 2 minutes ago and came to comment saying I'm an idiot, anyway, thank you very much for the answer and good work!
V2Q4KM is broken. it still uses Q6 by 20% which slows down or even breaks
Absolutely great model and I want to say "well done!".
And no, I have no question :-) Everything runs smoothly and really fast on my 3060 (12 GB) + 64 GB RAM.
I recommend not to use any loras if you can avoid it (speed). The models are that good, that a lot of stuff works perfectly just by using good prompts.
It's been a while since i've used ComfyUI and first time with video - is it normal for if re-writing description / random seed that the model would unload? Most of my "downtime" is models loading etc. I think everything works end-to-end with your provided workflow, but i feel i am missing something WRT processing and speed
I've 32gb ram and a 4090 card with 24gb vram... which i think is sufficient?
I'm using the V2q8High GGUF
or rather i'll reframe my question:
After model load once, and then i change the prompt in same group it runs in (i.e. first 5secs) - a new generation takes about 10mins to process. Is that a "normal" amount of time given specs above and i just need to manage my expectations?
@Biscuit10 Hi, that's not normal. Once the model is loaded, everything should go much faster. I've had this problem before where ComfyUI took a very long time on the Text Encoder. Is your ComfyUI up to date?
@taek75799 i was using an older version (with cuda128) as i couldnt get the latest one working some reason, i will try update to latest and move all models / workload over and see how i get on.
thanks for letting me know and i'll loop back to this after some more testing.
@Biscuit10 If I may give you some advice: keep your current version and install a new one alongside it to see [how it performs]
@taek75799 okay, so updated drivers / cuda version etc and it works, but speeds are still comparible to before (just shy of 500 seconds) - then if i do not touch the prompt but randomise seed, it reruns it from ~50% area with "Requested to load WAN21..." again, so yeah does that suggest something is still weird?
@Biscuit10 The speed of the second section shouldn't be any different; it's only loading a different image
@taek75799 yeah its still trying to reopen those again after first run / hitting random seed.
If i regen with same seed, its almost instant it makes it, but yeah if i adjust that it tries to reload the models / vae in the prompt subgraph area.
This is coming up at end of run after prompt complete though, is this something "resetting" it?
Exception in callback ProactorBasePipeTransport.call_connection_lost()
handle: <Handle ProactorBasePipeTransport.call_connection_lost()>
Traceback (most recent call last):
File "asyncio\events.py", line 89, in _run
File "asyncio\proactor_events.py", line 165, in callconnection_lost
ConnectionResetError: [WinError 10054] An existing connection was forcibly closed by the remote host
Exception in callback ProactorBasePipeTransport.call_connection_lost()
handle: <Handle ProactorBasePipeTransport.call_connection_lost()>
Traceback (most recent call last):
File "asyncio\events.py", line 89, in _run
File "asyncio\proactor_events.py", line 165, in callconnection_lost
ConnectionResetError: [WinError 10054] An existing connection was forcibly closed by the remote host
@taek75799 so just to confirm, when i do run from new seed it does start straight at the section 1 bit and progress starts at around the 65% mark, but yeah it is trying to reload the HIGH / LOW models again for sure, as well as teh vae decode (around 74% mark - this takes bloody ages).
Neither the WAN21 or WANVAE seem to be loading fully, only partially - if that makes a difference.
it feels like the 2nd run, having already done the first but randomizing the seed, is actually taking a lot longer? have tested both the FASTMOVE and regular V2.2 models now as well.
Given i'm using the GGUF file too, can i make the "Load Difficusion model HIGH" and "LOW" cells purple to bypass? i think the Unet Loader vs Load Diffusion is you only pick one of the, presumably.
If I dont have to worry about the model reloading element in the first box, everything else runs fast i.e. upscale / FPS thing, so its just sussing that bit out then i think i'm sorted
@taek75799 sorry for the constant replies / updates etc - i've been testing more today, and if i take a prompt / reseed it the time has come down to around 300seconds or so for a 5second video - need to test padding on 2nd video with a "saved" seed so it doesnt regen etc.
Using the latest version on github for comfyUI so cuda130 etc.
Example of a re-run with same things, diff seed:
got prompt
Requested to load WAN21
loaded partially; 14179.30 MB usable, 14081.45 MB loaded, 744.02 MB offloaded, 79.72 MB buffer reserved, lowvram patches: 0
100%|████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:40<00:00, 20.12s/it]
Requested to load WAN21
loaded partially; 14179.30 MB usable, 14081.45 MB loaded, 744.02 MB offloaded, 79.72 MB buffer reserved, lowvram patches: 0
100%|████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:43<00:00, 21.64s/it]
Requested to load WanVAE
Unloaded partially: 220.89 MB freed, 13860.56 MB remains loaded, 79.72 MB buffer reserved, lowvram patches: 0
loaded completely; 1390.38 MB usable, 242.03 MB loaded, full load: True
Prompt executed in 312.47 seconds
Is that more within the timeline expectations?
The Request to load the WAN21 (which i imagine is the high / low?) is the thing taking the time - the iterations post that are okay i think - but would you still expect it to be faster, and is the unload / reload of things the bottleneck?
@Biscuit10 No problem. Yes, your s/it are normal here, and your generation times are too.
@taek75799 okay cool - thank you for confirming with me that things have normalised a bit!
Then presumably if i want to squeeze out that extra speed, an nvme SSD to upgrade from regular SSD, as the model load / reload would in theory be quicker presumably? (alternatively more ram... but that shit is expensive as hell right now lol)
Kind regards!
Testing was successfull, godd and great result, with both High and low Q4 version working fine in my 3060TI 8gb GPU... Thank you so much.. Now i need to find a workflow to use this checkpoint to extend and create a 15 sec video..
I’m using it with SVI lora and I can do more than 25s without loosing quality. The best workflow I found is in YT by @AIninja94 (stable video infinity V2)
@Fossil91 Thank you, so much, have a great time
@Fossil91 Hi, I'll be releasing an SVI version this Saturday along with an SVI workflow.
Hey bro, Tell me how long it takes to record a 5-second video at 480p resolution On a RTX 3060TI?
@hakfull95539 Hi for me it took 412 sec or less to generate 5 sec video in 480p
Sampler : UNI PC BH 2
Scheduler : Normal
Is the best solution for this model. Great Job!
What makes you say that? I just tried it and the image quality is actually sharper for me with just euler+simple and the gen time is also faster.
I don't know what about the fact that a man doesn't try to poke his penis at a woman, but he shows up anyway and pokes his penis automatically. Some kind of maniac! is there any way to fix this?
Can i see your prompt?
Hi, are you using the NSFW CLIP? Check the description, I've posted a comparison there.
my first time using wan , and comfy . I downloaded the model , but the workflow is CRAZY . i have no idea how to make it work . if anyone can please help me .
Hi i got the workflow from this video description all credits goes to him, i only downloaded this "WAN 2.2 Enhanced NSFW" q4 gguf high and low, used it in the workflow and did not downloaded the lightx lora. because creator of this gguf included it.
It it just me or does this model have a strong aversion to buttholes when doing i2v? Typically you just end up with an extra long vagina.
Did you mean 'ugly vagina'? Did I get that right? I think this can help: [https://civarchive.com/models/2217653?modelVersionId=2496721] and [https://civarchive.com/models/2217653?modelVersionId=2496754]
This is an awesome model! But I'd really love to know how to write prompts that prevent the characters from doing that repetitive swaying back and forth
Which model did you use, 'NSFW Normal' or 'NSFW Fast'? If you used the Fast version, you should try the one without 'Fast' in the name.
@g1263495582 I've tried both models, and both seem to have this same issue. Sometimes the fastmove version actually performs better than the normal version? I'm not sure if it's because the fastmove version has better comprehension of action prompts—when I use the normal version, it almost always produces that repetitive back-and-forth hip thrusting...
@nishigou Tomorrow, I'm releasing the SVI version. It will also be compatible without the SVI LoRA. I believe these issues won't be present anymore.
Recommended LoRA to obtain a very realistic vagina and anus:
https://civitai.com/models/2217653?modelVersionId=2496754
Above link no longer works, do you have a link to a new model or anywhere you can share? Thanks
Hi, I'm new here. Which model should I choose if I have an RTX 5080?
Hi Q8
Man what a GIANT load of information you add along with your model. This is simply amazing. Thank you for this.
Do you have huggingface page as well to deal with a list rather then one line with arrows on both sides? Civitai interface is a chore when managing multipost like this >_<
(Would also be good idea to have multiplatform uploads, seeing how NSFW loras/models simply disappear from Civit)
Hi, and thanks for your feedback. I think I'll post on Hugging Face later. My models are also on the Civitai archive.
@taek75799 there they only link to original sites, so if they deleted here links are also dead there. Many loras are lost forever this way, unless someone uploads them to huggingface.
hey awesome job on those !!
i do have an issue with the fast move fp8 model though - the video quality is much worse that the first i2v cam model - i am using your workflow, just changing the models - any idea why? although the promt adherence is better
Any advice to have one character in a scene be very still and non-moving while the other performs a sexual act on them? I always find it impossible to achieve. Specially with men characters who keep moving and thrusting their hips uncontrollably. I'm using the non-fastmovement checkpoint and the non-nsfw clip.
This is very difficult. I'll be releasing the SVI version this Saturday the issue should be partially resolved
how to stop vomiting semen from mouth and other orifices that are not involved?
You can comission or support a NSFW artist on Patreon for that, otherwise enjoy the slop and don't complain
Hi, this is a common issue, even with 'cum' LoRAs which tend to do that. I manage to fix the problem by changing the seed or tweaking the prompt
Hey everyone, I have a question, what do you think about using FAST MOVE V2 Q6K In Colab? Has anyone tried one of the models there Is there an easy-to-use notebook with workflow comfyui Because it is extremely difficult for a beginner.
This so far has been the most effective and easiest to use workflow I have found. My only issue it it has a habit of constantly changing the eye colors. Any idea on how to stop that? no prompting seems to work.
Hi, thanks for your feedback. The most effective advice I can give you is to generate the first video. Once it's done, check at the very end of the video if the person's eyes are visible; the color will stay the same in the next video. This Saturday, I'll release a workflow built the same way but with SVI. You won't have to worry about those kinds of details anymore.
@taek75799 Thanks for the answer. I actually have a video where a woman has green eyes, at about 2 seconds she closes her eyes and opens them and they are brown and its before the first clip finishes. but that sounds amazing thanks.
hi again. Quick Question:
What workflow do you use and is it available for download?
Hi, the workflow I'm using is the 2.1 version posted here https://civitai.com/models/2079192?modelVersionId=2562360 for 5-second videos. As for longer videos, I use a different SVI workflow which I will post tomorrow.
@taek75799 ah ok, thank you very much
@taek75799 Hello, which Loras are merged on the model? I liked a lot of the cum effect when using close-up pic of the penis. I wanted to know the Lora to test more using the base model.
Hi, I think it's this one. https://civitai.com/models/1307155/wan-22-experimental-wan-general-nsfw-model?modelVersionId=2073605
@taek75799 Hello, thanks for answer but there is no cumshot on this Lora :(. Idk which Lora you merged but this model has the most realistic cumshot Ive seen, all of the other models is too much. dripping like a fountain lol
I’m torn...
WAN 2.2 Enhanced NSFW model is excellent at sexual fluids, vaginal penetration (tried anal but no success bad results), and blowjobs. BUT the problem is: the characters in the scene are always thrusting. Even in a blowjob scene, they keep moving their body or trembling… they keep thrusting into the air even when it’s not prompted. If the character has their legs open close to the camera, a distorted body appears at the bottom of the video, trying to penetrate with a invisible penis and merging with the character from the image.
Smooth Mix WAN 2.2 model is great with movement (can do anal and knows how to adapt the "shape when penetrating the vagina and anus. All the character stays still the model not make them thrust the air, body not trembling. During a blowjob, the character stays still, just as you expect to see in any porn video, unless you explicitly prompt the movement. The characters never merge in any of my tests. BUT the problem is: it’s very bad at generating sexual fluids, has difficulty with some prompts, some times it even remove the penis and try to recreate a vagina and requires wasting a lot of time generating multiple times with different seed to get what you want. Using realistic images, the model tends to produce a semi-realistic or 3D style when prompting for something that is not on the frame like prompting for a character to appears naked.
Hi, thanks for your feedback. I'm not familiar with SmoothMix. Tomorrow, I'll release a new SVI model, and I hope I've fixed the issues you mentioned, lol.
Hi, great job, thank you. My only question is that I trained a LoRa character on WAN 2.2 and I'd like to use it with your model, but the result isn't satisfactory. Do you know how I could train a LoRa directly on your model, or how I could adapt my LoRa?
Thanks
Hi, I'm not sure if that's possible. I'm using Musubi Tuner and AI-Toolkit, and you can't do it that way.
Thank you for your answer but did you use Character Lora on your workflow or do you have a advice about my character Lora?
@boblemarrant54400745 I've never tried a character LoRA with my model. Tomorrow, I'll release a lighter version made for SVI; it won't include the Lightning LoRAs. I think it will be better suited for that.
@taek75799 i already tried svi pro, really good, think it will be a good combo with ur model, i'll check this tomorrow. Thanks
Hi, I have a feed for new models. (this one pop-up) But can not find new update here. What update was released today?
I received a message from Civitai saying that one of my models was no longer there (version 1.1). So I re-added it, it was probably just a bug.
maybe label the model so we know which is t2v vs i2v?
Hi, I can't include it every time because there is a character limit. Look to the right of the previews, below the date; it's shown there
@taek75799 it is just there so much and it hard to find the right one . it just clicking each one just to make sure what it is make it alot more work then just being able to click the one you want right away. thank for responding.
This model is awesome. However it doesn't seem to fit in my 12GB VRAM (RTX 4070) and 16GB RAM setup. I’m currently using RunPod to test it.What's the minimum hardware needed? Any tips on how I can get this working on my machine? or i just need to upgrade higher ram?
check your workflow, I'm running it on a 6gb card lol
are you using HDD / SSD or nvme? I had to sort out what was running from what device as most of the downtime was around model loading / unloading as RAM was capping out. Running from HDD with large models is horrifically bad time-wise.
Also if you're using ComfyUI portable, when i copied over to nvme it was still "phantom" referencing the old disk it copied from due to some settings i didnt change etc. That sped it up a lot (VRAM speed not factored in)
Hi, and thanks for your feedback. Try the Q4_K_M version; it's the one that requires the fewest resources.
@aponeo @Biscuit10
Comfyui and all the heavy models like Wan 2.2 and others like Text encoders are stored on the NVME, small models like illustrious/SDXL on HDD. Also do not set page file on HDD that's one of the worse choices.. store it on the NVME too if you have, way better than SATA SSD
Truly one of the best available. Excellent work my friend.
Hope you don't mind a dumb question from the inexperience but I'm new and just trying to learn all this. I've managed to make some videos using WAN 2.2 T2V 14B in ComfyUI, but I'm not sure where to put your GGUF files to use them. Any advice to point me in the right direction would be greatly appreciated! Thank you.
Hi models/unet, you also need to install ComfyUI-GGUF using the Manager. Then, replace the Load Diffusion Model node with the Unet Loader (GGUF) node in your models/unet folder.
@taek75799 Thanks! Got it working. Now if I can figure out why its so blurry lol
@madeweerd Are you sure you're using both the 'High' and 'Low' models
One of the best there is! Just curious - are there any workflows/checkpoints that let you take a created video and have it generate custom sounds based off what it interprets in the video?
Hi, and thanks for your feedback. MMAudio and Hunyuan Foley, but I don't think you can generate NSFW content with them. There is also LTX Video v2, which supports video-to-video and doesn't seem to be heavily censored. You can also add your own voices, but I haven't tested all of that yet.
this model has been absolutely amazing, thank you sm!
would you reccomend q8 or fp8? im not sure the difference considering they are the same size.
Hi, and thank you. The Q8 version will be better.
Solved: Going to leave this just in case anyone else runs into a similar issue. It was solved by abandoning my old wan 2.2 workflow and reworking it from scratch with new up to date nodes.
Old Issue: Im getting off perspective warping on faces in anime style attempts. Lips, chins and eyelashes especially get weirdly distorted. Anyone else experience this and have a work around?
Hi, this look amazing, just to be sure, i've downloaded the Q8 H and L
is this ok like these to use that?
https://snipboard.io/FGX5ow.jpg
i suppose that if the output video is blurred that i must Increase the steps
{kind=link}
but dont find where i can increase the step
Thank man
Hi, yes, what you did is correct. The steps are located inside the 'subgraph' nodes. There is a small icon in the top-right corner of the node; you need to click on it.
@taek75799 Thank i will check next try ! :o
Love it. HOWEVER even with an image of a fit couple having fast sex, it sometimes adds a ballsack to the female as well. It's like as if she takes over half of the guy's penis and fucks back! It becomes a disturbingly collaborative two-ball-sacked penis! Any ideas or fixes?
EDIT: Even adding more info on genitals and more clearly defining who's the female and male, plus adding negative prompts like shemale and futa etc. only helps a bit. :/
Hi! Lol, yeah, these kinds of issues can still happen. It's very hard to fix with just a prompt. I think this bug will show up on certain images. What you could do, though it's a bit tedious, is use Inpainting to make sure the penis is further away from the vagina. That might work, but I'm not entirely sure.
@taek75799 ahh lol I always inpainted to make it inserted actually haha :)
So it actually needs to be OUTSIDE in the start image for the sex video. Interesting. Will try that, thanks.
When I generate the video in SVI, it looks blurry.
Did you add the Lightning LoRAs?
@taek75799 https://files.fm/u/f8uvacdfbf
@lolbleach001584 Thanks for the screenshot, everything looks good. When you put the Lightning LoRAs in the 'Global Lora' [nodes], do you have the same issue? Could you send me the JSON file after getting a blurry video so I can test it myself?
@taek75799 https://uploadnow.io/files/nxh1wB5
@lolbleach001584 I can't access the link. Could you please send it to me here? https://www.swisstransfer.com/fr-fr
@lolbleach001584 Everything seems to be correct. Forgive me for asking, but did you actually download the Lightning LoRAs? And did you select them from the LoRA list? You need to do this manually, as sometimes they aren't loaded by default
@taek75799 Hi, I downloaded the light lores and now I've managed to get it working, but when I generate the animation it's distorted. I've attached a screenshot. https://es.files.fm/u/rx5xgs4z73
@lolbleach001584 The link for 'Combo 2' for Lightning HIGH
was incorrect. I have updated the links.
@taek75799 Yes! Thank you so much for taking the time to help me.
@lolbleach001584 No problem. Let me know whenever you can if everything is working fine, if you'd like.
Hi @taek75799
First of all thanks a lot for your amazing work.
im using your workflow (before SVI update) but it seems like on the GGUF version i always get completely fading/blurry results. Not just a little unsharp, its like the subject is smearing out all over the video. Any idea?
ive used the fp8 model but got a lot of face drift even on the first 5s so read your comments about q8 is the one you think is best.
any ideas? much appriciated
Hello and thank you for your feedback. Could you please send me the workflow saved right after the poor video result so I can check it? https://www.swisstransfer.com/fr-fr"
quick reply!
yes here it is. i havent change anything from your workflow. https://www.swisstransfer.com/d/25f88356-50f2-4165-b55e-720adab0bcc1
@bekejej6031201 Hi, you aren't using my models in your workflow; those are the base models. Therefore, they don't have the Lightning LoRAs included.
@taek75799 Lol, what a rookie misstake. thanks for you great support.
All of them are fp8 except for svi right? Will you make an fp16 version?
Hi! All models are available in FP8, Q4_K_M, Q6_K, and Q8, except for the SVI ones which were added two hours ago. The Q8 version is very close to the FP16 version.
For the Combo #2, the link to the high lora looks like it's going to a checkpoint, not a lora.
Thank you very much for that. I fixed it: I can't find the Lightning 1030 links on Hugging Face anymore, so I replaced them with a Civitai link. Thanks a lot!
does all of the models not require lightning lora?
Hi! For the models at the top labeled SVI, yes, you need the Lightning LoRAs. For all the others, they are already included in the model.
I just saw GLM in the description. I recommend switching to Grok; it's better for NSFW.
Hi and thanks! I've never used Grok. I just checked; I thought it was only available on Twitter, lol. Thanks, I'm going to change that then.
@taek75799 You can send images to Grok, even NSFW ones. If it tries to generate an image, just hit stop. Then, ask for the prompt or tell it to analyze what you just sent.
@g1263495582 Lol, nice tip!
@taek75799 Also if using Comfy, it's also worth checking out Adaptive Prompts (an alternative to Dynamic Prompts). It fixes a lot of issues and introduces new features.
@AiliotAlderson Hello and thanks for the advice! I'm not familiar with it; I checked a bit: is it a custom node?
@taek75799 Yeah groks the best of the LLM at this point for NSFW stuff at least imo.
@taek75799 yeah it's a comfy custom node. Instead of having to do rare prompts like {selection|||||||||||}, you can assign weights to prompt selections like {common%5|uncommon|rare%0.1}
One other thing I like about it is that you can also do wildcard variable assignments. So on one node you can do something like {frank|rachel|john|abby}^name, and then connect it to other nodes. You can then recall that value with __^name__. Lots of other nice additions too.
@AiliotAlderson That looks interesting, I'll have to look into it, but I have a lot of other things to do right now. Thank you very much!
@taek75799 After the new policy update, it's getting harder to get NSFW out of Grok.
@g1263495582 Darn, I'll give it a try if it causes issues with the prompting. Thanks for your feedback!
'Greater flexibility: Lightning and SVI LoRAs must be loaded manually for custom workflows' - noice! I'll give them a try, even though i mostly play around with ltx2 recently. Thanks!
How about futa/trap content, is it possible to generate with this model?
Hello! I don't know, but I don't think so. I haven't tried or trained for that, but you can try adding a LoRA for it at a low strength: https://civitai.com/models/2040641?modelVersionId=2476982
Use it with SmoothMix Futanari LoRAs, the combo works really well !
Such a shame you only provide fp8 and quantized versions... and not a single fp16 one. The difference in quality is just too obvious.
I tried the official WAN 2.2 FP16 with NSFW LoRAs (https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/blob/main/split_files/diffusion_models/wan2.2_i2v_high_noise_14B_fp16.safetensors) vs this NSFW WAN model you posted (FP8) and the official WAN 2.2 FP16 with NSFW LoRAs win big time. The difference in quality is so high.
Edit: got it working now. Not even sure what the cause was, but I ended up using a different workflow as recommended in a reply and then rebuilt it using my preferred layout.
I'm getting a completely empty latent out of the IAMCCS WanImageMotion node, and hence completely black videos. Any ideas?
Hello! Go to iamccs's GitHub and get the workflow, it's simpler. Try it and see if you get the same result.
@taek75799 Hmm, reading it, makes sense that I'm getting an empty latent, since that's what it's supposed to output. The real question, then, is why my sampling isn't working. Thanks for pointing me to the github - that's one less thing to troubleshoot.
any image that i create, SFW or NSFW, will result in the person bouncing up and down. ive tried all negative tags suggested. any advice?