⚠️ Important information
All models already include the Lightning LoRAs, except the SVI models, where Lightning is not included.
Do not use additional Lightning LoRAs on models that already have Lightning integrated, or the quality will be degraded.
For SVI models, you can use Lightning LoRAs if you want faster video generation.
2or3 ksampler (for svi) https://civarchive.com/models/2079192?modelVersionId=2668801
v2.1 (for nsfw v2) https://civarchive.com/models/2079192?modelVersionId=2562360
v2.1 with MMAUDIO (for nsfw v2) by @huchukato https://civarchive.com/models/2320999?modelVersionId=2613591
Another wf triple KSampler KSampler https://civarchive.com/models/1866565/wan22-continuous-generation-svi2-pro-or-gguf-or-32-phase-or-upscaleinterpolate-w-subgraphs-and-bus?modelVersionId=2559451
triple KSampler wf setup allows for more motion and helps prevent slow-motion issues. In exchange, your videos will take longer to generate.
For those having issues with my SVI workflow , you can try Kijai's wf here: https://github.com/user-attachments/files/24364598/Wan.-.2.2.SVI.Pro.-.Loop.native.json. Alternatively, you can try fmlf wf https://github.com/wallen0322/ComfyUI-Wan22FMLF/tree/main/example_workflows they will be simpler. There are others on Civitai that work very well too.
Qwen-VL workflow as an alternative to Grok for creating your dynamic NSFW prompts. Thanks @huchukato for his work: https://civarchive.com/models/2320999?modelVersionId=2611094
🟣 SVI Update – NSFW
⚡ Model Presentation (SVI-compatible version)
This update was made because the NSFW V2 models were not fully compatible with SVI LoRAs.
This version was created to work smoothly with SVI, while still functioning without them (though the workflow must be adapted).
Be careful, SVI LoRAs will only work with a workflow specifically designed for them, otherwise, it won't work.
There are two models available for SVI:
✔ Fast Move (FM) – Sexual scenes may differ from the Consistent Face model and will generally be faster.
✔ Consistent Face (CF) – Slightly better image quality, which may be preferable for anime-style videos; sexual scenes differ from Fast Move, but the difference is minimal.
You can also mix models between High and Low LoRAs:
FM (Fast Move) as High + CF (Consistent Face) as Low
CF (Consistent Face) as High + FM (Fast Move) as Low
Both combinations work and give slightly different results, offering more flexibility for your videos.
For this version, the main improvements include:
✔ Fully adapted for SVI LoRAs
✔ Greater flexibility: Lightning and SVI LoRAs must be loaded manually for custom workflows
🟣 SVI LoRAs – Strengths & Weaknesses
⚡ Overview
✅ Strengths
Best solution for making long videos
Excellent transitions between video segments
Reduced degradation compared to other solutions
Strong character coherence: the model retains information from the previous video, helping maintain consistency
⚠️ Weaknesses
Weaker prompt understanding
Weaker camera understanding
Videos are less dynamic
Sometimes slow-motion effect
(can be improved with proper Lightning LoRAs, dynamic prompts or triple ksampler)
🟣 SVI LoRAs – Download Links
⚡ Download
Note: Both LoRAs must be loaded manually in your workflow.
🟣 Suggested Lightning LoRA Combos (Optional)
⚡ Overview
You don’t have to use these Lightning LoRA combos. They are optional and allow you to fine-tune motion and degradation.
You can also use other Lightning LoRAs or assign different combos per video for more control.
🔥 Combo 1 – More Motion (Rapid Video Degradation)
High LoRA →
https://huggingface.co/Kijai/WanVideo_comfy/blob/709844db75d2e15582cf204e9a0b5e12b23a35dd/Lightx2v/lightx2v_I2V_14B_480p_cfg_step_distill_rank128_bf16.safetensors
Weight: 4
or
💜 Combo 2 – Less Image Degradation
or
or
🟢 Combo 3 – Balanced Motion / Moderate Degradation
High LoRA →
https://huggingface.co/Kijai/WanVideo_comfy/blob/709844db75d2e15582cf204e9a0b5e12b23a35dd/Lightx2v/lightx2v_I2V_14B_480p_cfg_step_distill_rank128_bf16.safetensors
Weight: 3
Low LoRA →
https://huggingface.co/Kijai/WanVideo_comfy/blob/709844db75d2e15582cf204e9a0b5e12b23a35dd/Lightx2v/lightx2v_I2V_14B_480p_cfg_step_distill_rank128_bf16.safetensors
Weight: 1.5
🧠 Advanced Usage Tip
You can disable global Lightning LoRAs (in my wf) and assign different combos per video:
Combo 1 for Video 1, Combo 3 for Video 2, Combo 2 for Video 3.
Each combo produces different motion and degradation behavior.
If you want to create several-minute-long videos while maintaining high quality, it is possible, but it will take a very long time. You just need to avoid using Lightning LoRAs and use the full model instead.
🧠 Dynamic Prompts – Better Control & More Motion
You can use dynamic prompts to have better control and this helps to make the video more dynamic.
You just need to give this example prompt to an LLM like ChatGPT. It will be enough for it to describe the image you have and what you want as a video while keeping the same structure of the prompt in the following example.
⚠️ This will be a NSFW prompt; ChatGPT will not accept it.
You can use GROK https://grok.com, which can make NSFW prompt modifications.
For more examples of prompts with different poses, check:
Enhanced FP8 Model.
Give these prompts to GLM with the dynamic prompt structure if you want.
Example 1
(At 0 seconds: Wide shot showing a slightly overweight man casually walking down a city street, camera fixed in front, urban environment with buildings and cars.)
(At 1 second: Suddenly, a massive shark bursts from the pavement ahead, looking terrifying at first, pavement cracking, dust and debris flying, camera from side angle.)
(At 2 seconds: Medium shot from the side, the man stumbles backward in shock, while the shark dramatically slows down and strikes a comically exaggerated sexy pose, revealing large, exaggerated shark breasts, covered by a colorful bikini.)
(At 3 seconds: Close-up on the man’s face, eyes wide in disbelief, as he turns to look at the shark, small cartoon-style hearts floating above his head to emphasize his amazement, camera slightly low-angle.)
(At 4 seconds: Dynamic travelling shot showing the man frozen in the street, the shark maintaining its sexy pose, water splashes and debris still moving realistically, urban chaos around.)
(At 5 seconds: Wide cinematic shot pulling back, showing the man standing in the street, staring at the bikini-wearing shark with hearts above his head, epic perspective highlighting absurdity and humor.)
Example 2 – Anime NSFW
(At 0 seconds: The couple in a cozy bedroom, anime style, soft lighting highlighting their intimate embrace, her back arched slightly as he positions himself.)
(At 1 second: The man’s hips moving rhythmically, the head of his penis sliding effortlessly into her vagina, her body responding with a gentle, fluid motion, anime-style motion lines emphasizing the smooth penetration.)
(At 2 seconds: Her back arching deeply against him to intensify the pleasure, hips swaying with each thrust, breasts bouncing subtly, small hearts floating around them to capture the erotic energy.)
(At 3 seconds: Her face, eyes closed in bliss, a soft moan escaping, hands resting behind her head, anime-style blush on her cheeks, the air filled with a seductive aura.)
(At 4 seconds: The man penetrating her deeply, her body moving in sync with his, the bed sheets slightly rumpled, the room’s warm lighting enhancing the intimate, lustful atmosphere.)
(At 5 seconds: The couple locked in a passionate embrace, the scene exuding vibrant, seductive energy, anime style with smooth lines and soft shadows.)
🟣 Lightning Edition – NSFW I2V V2
⚡ Model Presentation (2 new versions available)
I originally planned to release only one V2, but some people preferred the NSFW V1 over the Fast Move V1 version, so depending on what you’re looking for, one version may suit you better than the other.
For these V2 versions, I tried a new approach:
✔ I made sure that most sexual poses work, while the model is also good for SFW content
✔ More flexible for general use
🔥 NSFW Fast Move V2
Improvements included in this version:
Better prompt understanding
Better camera understanding
Reduced unnecessary back-and-forth movements outside sexual poses
(cannot be completely removed, but strongly reduced)Improved bounce effect on the buttocks
If a man appears, he will no longer automatically attempt to penetrate the woman when she is nude
This version is designed for those who want more dynamic scenes with more movement.
💜 NSFW V2
The difference between this version and NSFW Fast Move V2:
Less camera control
Less camera understanding
But body movements are less pronounced (breasts and buttocks)
Some preferred V1 NSFW to V1 NSFW Fast Move, and this version keeps that spirit
For varied sexual poses, check the previews — there are many.
You can use the shown prompts and adapt them to your images, but of course, other prompts will work as well.
Don’t hesitate to use other LoRAs for creating specific concepts.
🔧 Recommended Settings
Steps: 2+2
(Jellai recommends 2+3 for even better results, and I agree)Sampler: Euler simple
CFG: 1
This model already includes the Lightning LoRAs, don’t use them, or the quality will be degraded
You need to download both models: H for High and L for Low.
Here is an example made with the base workflow + the First/Last Frame workflow + upscaler (only on the starting images) + inpainting (cum).
https://civarchive.com/images/114733916
🔞 LoRA Examples (with links and recommended weights)
LoRA: Penis Insert WAN 2.2
LoRA weight: 1
Face → Doggy
https://civarchive.com/images/112864483Face → Missionary
https://civarchive.com/images/112864718
https://civarchive.com/images/112864835Face → Doggy (leg aside)
https://civarchive.com/images/112864885Another example
https://civarchive.com/images/112864972
Other examples with different LoRAs
Face → Reverse Cowgirl — LoRA weight: 0.7
https://civarchive.com/images/112865189Face → Cowgirl — LoRA weight: 0.5
Face → Missionary — LoRA weight: 0.3
https://civarchive.com/images/112865381Face → Missionary — LoRA weight: 0.5
Face → Doggy leg aside — LoRA weight: 0.6
https://civarchive.com/images/112865551Face → Doggy — LoRA weight: 0.7
https://civarchive.com/images/112865696Face → Spoon — LoRA weight: 0.7
https://civarchive.com/images/112868124
Recommended LoRA to obtain a very realistic vagina and anus:
https://civarchive.com/models/2217653?modelVersionId=2496754
💡 Tip for Anime Style:
If you’re working in an anime style, feel free to follow the advice of @g1263495582 thanks to him for this.
Try these LoRAs together or separately; they help maintain face consistency:
🔹 Note:
For these LoRAs, use only Low Noise.
For the examples mentioned above, use High and Low Noise as indicated.
LoRA weight: 0.3
Many things can be done with the model, but don’t hesitate to use other LoRAs for specific purposes. And don’t hesitate to lower the LoRA strength to preserve the face as much as possible.
📷 Dynamic prompt example with different camera angles:
(at 0 seconds: wide shot showing the woman standing in the snowy plain, a massive giant dragon emerging behind her, snow cracking and dust rising).
(at 1 second: the woman jumps backward onto the dragon’s back as it bursts fully from the sky, camera tracking the motion from a side angle, debris and snow flying).
(at 2 seconds: medium shot from the side, the woman balances heroically on the dragon’s back as it begins to run forward across the snowy plain, slow-motion on her posture).
(at 3 seconds: close-up on the woman’s determined face, camera slightly low-angle to emphasize her heroic stance, snow and debris flying around).
(at 4 seconds: dynamic travelling shot alongside the dragon, showing the snowy plain, scattered debris and ice fragments flying everywhere as it gains speed).
(at 5 seconds: wide cinematic shot pulling back, showing the dragon taking off with the woman riding on its back, soaring above the snowy plain, epic perspective with snow, wind, and scale emphasizing the drama).
For available camera angles, check further down in the “cam V2” model description.
🔞 Normal Clip vs NSFW Clip:
You can also use the NSFW version for your clip.
It can bring positive effects for sexual scenes, but it can also cause issues, as in this example:
NSFW Clip:
https://civarchive.com/images/112864204Normal Clip (same seed):
https://civarchive.com/images/112864295
Here are the links to NSFW clips (thanks to zoot_allure855 for correcting the BF16 version):
BF16 fixed version:
https://huggingface.co/zootkitty/nsfw_wan_umt5-xxl_bf16_fixed/tree/mainFP8 version:
https://huggingface.co/NSFW-API/NSFW-Wan-UMT5-XXL/tree/main?not-for-all-audiences=true
❓ If you have any questions, don’t hesitate to ask!
Many people ask me for help via private message. You can do that, no problem, but I would appreciate it if you could do it in the comment section, it could help other people. Thank you.
🟣 Lightning Edition – NSFW I2V camera prompt adherence
⚡ Model Presentation (2 versions available)
I decided to release 2 versions. Both can produce different results, as you can see in the previews (the seed was the same).
Fast Move Version: provides more movement, and the movements will be faster, with better prompt understanding and camera handling
(you can see it in the 4th preview "fast move high" where the man slaps the woman)Natural Motion Version: offers more natural breast movements depending on the situation and produces slower scenes.
👉 Check both and choose the one that works best for you.
This NSFW edition is, of course, focused on sexual poses.
You should achieve very good results.
To create specific concepts, feel free to use specific LoRAs — they work very well with this model.
🔧 Recommended Settings
Steps: 2+2
(Jellai recommends 2+3 for even better results, and I agree)Sampler: Euler simple
CFG: 1
This model already includes the Lightning LoRAs, don’t use them, or the quality will be degraded
You can also use this T5, which may improve understanding:
https://huggingface.co/NSFW-API/NSFW-Wan-UMT5-XXL/tree/main?not-for-all-audiences=true
📝 Usage Tips
Start with a clean, high-resolution image for better results.
The model will not change the face; if it does, increase the resolution.
Also adjust your prompt if you are not getting what you want.
Wan understands some terms well, but not all.
For prompts, check the video previews: adapt them to your image.
Other prompts will work too.
🎥 Training
I trained 2 LoRAs:
The first one using several videos and images of different sexual positions.
The second one to bring more dynamic motion.
Respect to everyone who creates this type of LoRA — it requires a lot of work.
🙏 Credits
This model wouldn’t exist without the incredible work of these creators:
alcaitiff : https://civarchive.com/models/1295758/nsfw-fluxorwan-22orqwen-mystic-xxx?modelVersionId=2300332
Sweet_Pixeline : https://civarchive.com/models/1844313/penis-play-wan-22
anonimoose : https://civarchive.com/models/2008663/slop-twerk-wan-22-i2v
dtwr434 https://civarchive.com/models/1331682?modelVersionId=2098405
A special thanks to Alcaitiff and CubeyAI, two very kind and humble people.
🔔 Important
Please don’t support my work with buzzes here, I don’t need it.
If you want to support someone, support the creators listed above — they truly deserve it.
💬 Feedback
Feel free to give me feedback, positive or negative, to help improve future updates.
Update WAN 2.2 V2 CAM I2V – NEW feature Camera & Prompt Improvements
This custom version of WAN 2.2 I2V has been updated to deliver better prompt comprehension and improved handling of camera angles and cinematic movements. It provides more accurate scene interpretation, smoother transitions, and enhanced control over dynamic.
Key Features:
Excellent understanding of prompts and scene composition.
Supports various camera angles and movements, including zoom, dolly, pan, tilt, orbit, tracking, and handheld shots.
Ideal for cinematic storytelling, animated sequences, and creative video-to-image projects.
Flexible multi-step prompts, standard 4 steps (2+2), can be increased for higher fidelity.
Recommended sampler: Euler simple.
You can, of course, use your usual prompts; this is just one example among many.
Example Prompt with Different Camera Angles
(at 0 seconds: wide frontal shot of a man standing in front of an open fridge, cinematic lighting, subtle ambient kitchen reflections, the fridge contents visible, camera static).
(at 1 second: medium shot from the front as he opens the fridge fully, reaches for a can, slight zoom-in to emphasize the action, cinematic framing).
(at 2 seconds: camera shifts to a side medium shot, tracking him as he lifts the can to his mouth, fluid movement, maintaining lighting and reflections).
(at 3 seconds: camera starts a smooth 360-degree orbit around the man, following him as he drinks from the can, motion fluid, background slightly blurred for cinematic effect).
(at 4 seconds: close-up on his face and upper body while drinking, orbit continues subtly, fridge reflections accentuating realism, cinematic polish).
(at 5 seconds: final wide shot as he lowers the can, camera completes orbit to original angle, showcasing the kitchen space, lighting, and dynamic movement).
Available Camera Movements
Zoom / Dolly
zoom in
zoom out
camera zooms in on subject
camera zooms out gradually
dolly in
dolly out
camera dollies in slowly
camera dollies out steadily
crash zoom
Pan
pan left
pan right
camera pans across the scene
gentle pan left
sweeping pan right
Tilt
tilt up
tilt down
camera tilts up to reveal…
camera tilts down from…
Orbital / Tracking / Arc / Rotation
orbit around subject
360° orbit
camera circles around
tracking shot
camera tracks alongside subject
arc shot
curved camera movement
Other Movements & Styles
static camera / static shot
handheld shot
camera roll
Note:
LoRAs work perfectly with this model, offering full compatibility and consistent results across styles and concepts.
# SUPPLEMENTARY ADVICE
You can use negative prompts, but be careful: this will double the generation time.
Only use them if you really want to prevent something from appearing in your video.
In that case, enable the corresponding node; otherwise, keep it disabled.
⚠️ Important
The model must be used with CFG set to 1, so negative prompts do not work by default.
However, there is a simple way to enable them.
How to enable negative prompts:
Open the Manager
Search for kjnode and install it
In your workflow, add the WAN Nag node
To use it correctly:
Connect this node after the LoRA Loader
Feed it with the negative prompt
Then connect it to the first kSampler (High)
👉 Only use this option when necessary, to avoid unnecessarily increasing generation time.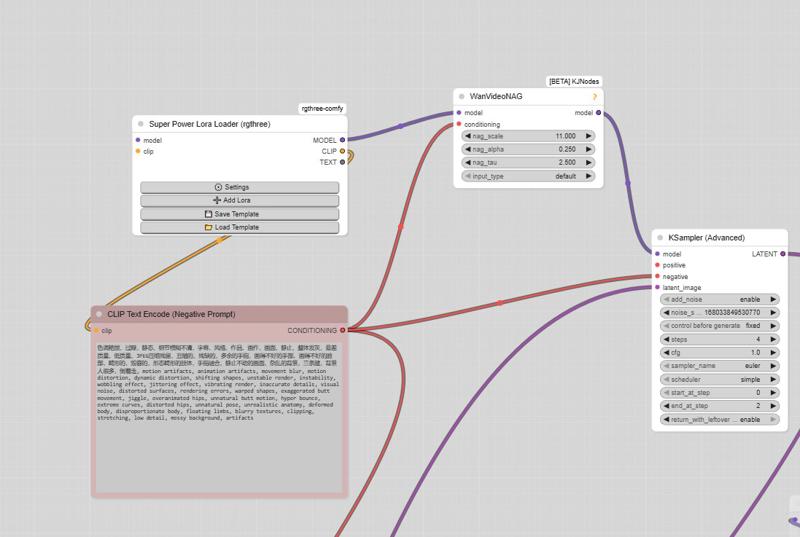
And here is the negative prompt for unwanted movements:motion artifacts, animation artifacts, movement blur, motion distortion, dynamic distortion, shifting shapes, unstable render, instability, wobbling effect, jittering effect, vibrating render, inaccurate details, visual noise, distorted surfaces, rendering errors, warped shapes, exaggerated butt movement, jiggle, overanimated hips, unnatural butt motion, hyper bounce, extreme curves, distorted hips, unnatural pose, unrealistic anatomy, deformed body, disproportionate body, floating limbs, blurry textures, clipping, stretching, low detail, messy background, artifacts, butt bounce, moving hips, swinging hips, shaking butt, wiggling butt, moving lower body, moving pelvis, jiggling buttocks, bouncing butt, unstable stance, unnatural hip motion, exaggerated hip movement, hip sway, hip rotation, bottom motion, pelvis motion, wobbling hips, fidgeting lower body, dancing hips, pelvic movement, motion blur, unnatural movement
And here is the negative prompt from the official ComfyUI workflow:色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走
Note: If you use the default workflow without the node, this negative prompt will not work.
UPTDATE: Lightning Edition – T2V
I’m not really experienced with T2V myself, but a colleague who works with it a lot tested this version and confirmed that it performs very well. From the few tests I managed to do on my side, I got the same impression, although I haven’t compared it directly with the base version yet.
The settings are the same as in the image-to-video version: 2+2 steps or more if you prefer, CFG at 1, and Euler simple (though other samplers also work great).
I don’t plan to make an NSFW version for the T2V release,
but for the I2V version, I’m already quite happy with the first results.
Update WAN 2.2 V1.1 I2V
Updated version of the original Lightning merge — same settings 2+2 steps or more, featuring more movement and smoother flow (depending on the prompt).
The model already works very well in NSFW. Just use the right LoRAs, and the movement will improve.
WAN 2.2 V1 I2V
This checkpoint is based on the original WAN 2.2, with the Lightning WAN 2.2 and Lightning WAN 2.1 LoRAs already integrated. This improves image quality, makes motion smoother and more dynamic, and removes the slow-motion effect that can occur with the Lightning models.
A common setup is to use 2 steps on the high model and 2 steps on the low model, though other settings may work as well. Do not apply the Lightning LoRAs manually — they’re already included in this checkpoint.
My workflow
https://civarchive.com/models/2079192/wan-22-i2v-native-enhanced-lightning-edition
Description
FAQ
Comments (140)
First of all bro let me tell you how awesome your work is. It is so inspiring to look at your descriptions and your examples. It will take me many days to understand everything. I am honestly blown away by your output. Thank you for answering my last comments. I come back every day to read more.
question can be for anyone and feel free to respond (or not) some later, since they are many lol
1. Are you sure that 4 by 4 steps on the high and low sampler is the best for the nsfw v2?
2. What text encoder gives you the best quality? umt5 xxl fp16 or the nsfw wan umt5 xxl bf16 or the fixed one?
3. Did you ever see a glow around the subject? Maybe from motion amplitude or from the paint i2v node.
4. Do you start with the original image or the one from Find Perfect Resolution for better results?
5. For a 25 second video do you think using the same seed for all five clips is a myth? I see you do not use it.
6. Wan vae question. What do you think of Wan2 1 vae bf16, Wan2 1 vae fp32, Wan2 2 vae, and Wan2 1 vae?
7. Prompt question. Do you like the At X Seconds format or natural words more? And do you think it helps to let a llm describe the image first with things like tattoos?
8. Do you have a post workflow that mixes videos, blends frames, or makes the video smoother?
9. Is your best way to stitch videos still to take the last frame, upscale with lanzos two times, and use that?
10. Did you test the painter flf2v tool and make a workflow for it? Or do you just swap the node in your setup?
11. The mqlab loras change faces a lot for me. Do you feel the same?
12. Do you have a good example of a full circle orbit or a full circle turn? I try to make a 360 turn in two clips and test character consistency.
13. Do you have a trick to keep the workflow style and groups when using the api? I want to post the same json from the ui.
14. Do you have a trick to save a workflow in the api version? Some nodes break when they are not turned off, like save workflow.
I know wan2.2 is not perfect.
Hello and thank you for your feedback.
I do 2 steps in high and 2 steps in low. Of course, you can also do 2 in high and 3 in low, that will work as well. You can try other combinations too; it should work, but 2+2 is, in my opinion, the best compromise between speed and quality.
I don’t use NSFW, unless I want to create horror scenes lol. But it can add something for certain sex scenes. As you can see in the description, it can also be problematic. Personally, I don’t use it.
Hmm, I haven’t noticed that. By the way, all my previews are made with PainterI2V.
I didn’t understand the question? The Find Perfect Resolution node is just meant to adjust the correct ratio for the image. This avoids cropping and will adapt the video to a resolution that is a multiple of 16. It’s ideal for AI models, although I think WAN might work with 64, I don’t quite remember.
I didn’t know that, it could be true, I’ll test it, thanks.
Again, I don’t know. I always use the same VAE, the one provided by ComfyUI. I can’t really comment.
Here’s a good question: the format at 0 sec, etc., can be replaced with 1, 2, etc. It does the same thing. I think WAN will understand better with this prompt structure and provide a more controlled and dynamic scene. It can even help remove WAN’s annoying slow-motion effects.
Another good question. The workflow I posted is a bit outdated: transitions aren’t smooth, and since then I’ve been using Fun VACE. You can see in the first preview a 15-second video with almost perfect transitions. I think I can reach perfection, but I still need to work on it.
I haven’t tried FFLF Painter yet, but you just reminded me that it can also be very useful for creating excellent transitions. I can’t make a tutorial here, but I think others have already done it.
Yes, I’ve also noticed this. It’s because LoRAs are trained with similar faces. Some interfaces have mask options to avoid this problem, but it seems people either don’t use them or don’t know about them.
This is very hard to do with a single generation. It should be done in 10 seconds, and here we’ll have a face problem if the camera is behind the person at 5 sec. Or use a LoRA orbit, I think there are 3.
Sorry, I don’t know the API.
Again, sorry, I don’t know. Maybe it’s a ComfyUI-related issue; there are still many things to fix.
And lastly: feel free to download my videos if you want to see how they were generated. The metadata hasn’t been erased. Only the two videos of 15 sec and 10 sec no longer have metadata because I had to assemble them with a video editing software. By the way, I use an old ComfyUI for WAN, and it seems that with the latest ComfyUI versions, the workflow doesn’t open. I don’t know why.
GGUF smaller version for FAST MOVE V2 when?
Hello, which version do you need?
@taek75799 can you make nsfw fast v2 Q6_K versions please?
@tedajo2035450 Hello, some people have already asked me for the Q4KM, so I think I’ll make it this weekend. And I probably won’t be able to make the Q6KM for another two weeks. Sorry for the wait.
Amazing work!! Thanks, it's great! (Needs settings tweaks for those who can't get it to work.)
I allways have a problem using thigs like this xD. i use the NSFW Fastmove fp7 High with the, WAN 2.2 I2V native Enhanced worflow but the video that comes out is hella blurry idk why that happens but i always had problems with using things like this hope someone can help, idk what else to do
Hello, I’m sure we can make it work. Tell me which GPU you have, how much RAM you have, and if you want, send me the workflow you’re having issues with. Many people have already done it and it works well now.
Seriously awesome work! 100% improvement from the previous version. From my testing, the prompt adherence is unmached by other models. Works very well when doing complicated scenes with specific pose or camera transitions.
The only thing i was struggling with was the prompting of the orbiting motion of the camera. Does anyone know how to correctly prompt that? Something like "camera moves left" or "camera orbits left" don't seem to work for me.
Hello, and thank you for your feedback.
Here, you can see an example:
https ://civitai.com/images/108548197
or here:
https ://civitai.com/images/108548050
On this one, ‘left’ or ‘right’ isn’t mentioned, but it’s simply a way to show the AI how to move the camera.
Your model alterations are very good. It even can be used with loras without getting wonky (have to adjust weights bit more or less sometimes but otherwise I've had no issues).
Hello, and thank you for your feedback. By the way, excellent analysis that’s indeed the case: it’s more designed for general use.
You just reminded me that it might be useful to indicate the LoRA weights to people.
@taek75799 So far, WITHOUT LoRA's I've had stellar results and I like your workflow too. Very consistent prompt adherence and it's done everything I've asked with less fuss than any other model I've tried. You really have done a great job here.
@LetTheBassDrop I’m glad you like it. I hope to release a better version of the workflow soon, using Fun Vace to create perfect or almost perfect transitions.
Hello. Can someone help? I have 3060 12gb and 16gb ram. Im already using Wan 2.2 i2v Q4_K_S easily but its not NSFW. So i have decided to use this model but i dont know which i2v version is right for me. Also, should i download workflow, vae, high-low loras? Bcs i already have a workflow. thanx
Hello, use the workflow you already have. Here, you have the NSFW model in Q4KM; it will be almost the same as the one you’re using:
https://civitai.com/models/2053259?modelVersionId=2431117
bro 16gb ram is too low
@kumarkishank959811 i know but RAM prices have gone up. I'm going to buy some if the prices goes down.
are workflows included in the sample videos?
Hello, yes, except for the two videos that are longer than 5 seconds.
Which models are not gguf?
Where it says fp8. :)
"If a man appears, he will no longer automatically attempt to penetrate the woman when she is nude"
😂😂😂 Human nature lives also in the diffusion noise 😂😂😂
haha
i didn't get it, what models are T2V? some has "I2V" in the name and some doesn't but works bad with T2V...
Hello, you can find the info on the right side of the previews, at the top — scroll through the models on the right and it will appear.
Or here: https://civitai.com/models/2053259?modelVersionId=2356018
You can also load a white image in the Load Image node and use a prompt with the I2V models.
t2v means "Text to video", i2v means "image to video"
it makes my ComfyUI crashing.
Dont know what you did but everytime if i quee multiple videos it crash my comfy ui.
Tried it on my pc 5080 ram 32 gb
and then on runpod 4090 ram 32gb
I had to use higher ram to make it work.
which is wierd bcs this v2 version has what 13gb
and the previous fast move Q8 had 15Gb and it works fine.
Hello, with a 5080 and 32 GB of RAM, everything should work.
It’s hard to say why this is causing a problem: ComfyUI isn’t perfect, there are still many bugs.
Besides, if the Q8 version work, it’s not a resource issue, since FP8 is less demanding.
I’ll release the Q8 in some time, but I prefer to release the Q4KM first so that people with less powerful PCs can benefit from it.
I can't figure out how to make your model work with SVI LoRA. When I set the SVI LoRA weight to 1.0, it significantly reduces the quality. The official Wan2.2 SVI LoRA examples don't support negative prompts because they use WanVideo Sampler. Any ideas?
Hello, it will be difficult for me to help you, I haven’t tried yet. Does SVI work correctly with the WAN 22 Base model? I’ll need to try it tomorrow if I can.
I just tried, but not with Kijai’s workflow. To be honest, the WAN Wrapper nodes work very poorly for me with the native, so I don’t think it’s optimized for it. I still get freezes during transitions.
I’ve seen other examples with the correct workflow too, I don’t find it exceptional, as Fun Vace does better, but I need to test more.
@taek75799 SVI 2.2 is perfect working with your model, the only issue is the backed in lightning lora, as they have found out that you need to lower the strength of it as a workaround. As it's build in, we are not able to do that and that leads to -> your start image returns sometimes unexpected and unrepairable. If you are luky and do all the other things required, you can get more then a minute of video, maybe more ? But it's not much fun when you can not use your model. BTW it's working with wan2.2 without backed in lightning.
@josh80809336 Hello, thank you for your feedback. I will look into it and maybe make a version adapted for SVI.
Thank you. Sometimes it would be nice to be able to test things without lightning anyhow. Not only because of SVI.
@taek75799 Its a lot simpler, they just messed up the first workflow. With the newest workflow it's working without that bug. Fun stuff.
@josh80809336 Good news then, and thanks for your feedback.
You didn’t have to do it. I had already tried the first one, but I preferred to stick with the transition method using Fun Vace, even though it's a bit long.
So I'll check out this new workflow. Thanks.
Awesome work, just a question though, what steps should I do to improve facial distortion? I'm starting with two portraits and the faces are just ever-so different, kind of jarring. I'm using the workflow you included.
Hello and thank you. What resolution are you using?
@taek75799 I'm trying it with 832x480 images because the model/loras I previously used required it. I haven't changed anything in the workflow you included except for the models, I'm using the nsfwFASTMOVEV2FP8 H/L instead. Should I try generating with higher res images? Like, what size?
@jehfreek Yes, don’t hesitate to use 1024x1024 for square images or the equivalent for other ratios.
@taek75799 I'll try that, thank you so much.
I love the output. I used an alternate workflow as the workflow you provided seems to be running an error.
- Node ID: 117
- Node Type: KSamplerAdvanced
- Exception Type: RuntimeError
- Exception Message: PassManager::run failed
By any chance, good sir, what lora should I match to increase the quality or make the faces more smooth?
Hello and thank you for your feedback.
I don’t think a LoRA exists for that, but it’s easy to get better quality, give the UI a clean, high-resolution image.
If it isn’t high res, upscale it first there are good upscalers like SeedVR2.
Then, something very important: increase the video resolution.
I hope this helped you.
@taek75799 Hey sorry for the long respone. I got it working. I love the outputs! Thank you sir.
Continuing to knit the last frame will result in distortion of the original image.
Is there any way to use the last frame feature without color distortion?
Hello, honestly, I don’t think I have this issue Or maybe you have a better eye than me, haha ;). It’s hard to say, but if it’s a color problem, you could try a node like Color Match using the KJ nodes.
@taek75799 very simple test. try same image with start frame and end frame. Like making a loop video.
last frame have distortion and more brighter.
@zzozz I see, I understand better now. I should check that, because I’ve never tried it with the same image
issue is real, I will start documenting it
@juliusmartin I should also check that, I haven’t tried it yet. Feel free to give feedback here if you want, in case you find anything.
@taek75799 thank you for beeing so active, I have started a new comment for that with my current experience, hope thats ok
@juliusmartin In my experience, there seems to be a problem or bug in the last frame function.
If you input only the first frame in the wanfirstlastframetovideo node, it works like a regular I2V.
If you input only the last frame, the prompt will direct you to the last frame, but you'll get distorted results near the end.
If you use both the first and last frames together, you'll also get distorted results near the end.
@zzozz Alright, thank you for your feedback. I screenshotted your comment to look at it later, when I check it more closely, even though it seems fine. Thanks again.
@zzozz
my tests clearly show that the extreme pale drift is model dependent, and the last-frame node is more like a "magnifying glass" for that flaw
if I am allowed to, I will re-upload an old non nsfw model from our great taek75799 where this issue does not happen
Any GGUF release for V2?
Hello, yes, I’m releasing the Q4KM version this weekend.
Thanks for the work. Using Wan Thiccum and some other loras results in distorted video (blurry eyes and details). They often recommend different settings than you (different cfg, steps). Any idea how to make them compatible?
Hello, yes, with merged models you can use LoRAs without any problem, but you need to lower the strength.
I added a few examples in the description, so feel free to do the same — it will work very well too.
I2V keep presenting me weird shape penis (balls placed on top of weiner :P) Any solution?
Haha, the man is probably in a slightly upside-down position, maybe?
Unfortunately, it’s hard for everything to be perfect. I would say the solution is to add a ‘penis’ lora.
I’ll let you look for one, and if you can’t find any, I’ll check. ;)
Maybe tweaking the prompt could help, but I don’t think it will work very well.
@taek75799 all your models are missing. or are you updating?
Hello yes, it’s a bug that was reported to me. It’s probably an issue on Civitai’s side. We’ll have to wait.
@taek75799 seems to be fixed now
which ones are the i2v files?
Hello, look below download, there will be the information for each model, all except in I2V, except one on the far right in T2V.
cool models, can you make aio version? for image to video
Hello, what do you mean by AIO?
@taek75799 like this https://civitai.com/models/2173571/z-image-turbo-aio or this https://huggingface.co/Phr00t/WAN2.2-14B-Rapid-AllInOne
@Swagerka22 Yes, here it’s the same principle.
@taek75799 you have two separate models, I am asking if you can combine them + clip and vae together in one checkpoint
@Swagerka22 Oh sorry, I didn’t understand that. I could do it, I need to check that.
@taek75799 thanks
breast and ass jiggle is lot of the time too much. too watery. playing with positive and negative dont realy help. Many times recognising the ass as a breast, creating nipples on it
Hello, and thank you for your feedback. NSFW models are not perfect, and you may sometimes have issues with butt and breast movements. Try the NSFW version: the fast move one shows this effect more.
There is currently a bug on Civitai, the models cannot be downloaded on some browsers, i tried with edge, and it seems to work.
Where is the lighting diffusion model? wan2.2 i2v a14b low fp8 (lighting edition)_ v2?
Hello, on this webpage lol, I guess you can’t download it? Try another browser, or you’ll have to wait it’s a Civitai bug.
I downloaded all the other requisites, but the lighting i dont see it. Whats the exact name on the download slider thingy?
@jojulori12186 Are you talking about the Lightning LoRAs? If so, don’t use them they are already included in the model.
i downloaded everything, but on the load diffusion model im missing wan2_2-i2v-a14b-nsfw-high_fp8(lighting_edition)v2.safetensors. Where is that file to download?
i downloaded nsfw fast move v2 fp8 h and l, but im still missing the file with (lighting edition) on its name
Sorry mate i just cant find it lol. Can you point me to it? i wish i could upload a photo
@jojulori12186 It’s surprising: I downloaded the files of the V2 version and I have to check Civitai renames the uploaded files, and I think this one matches what you have: wan22EnhancedNSFWCameraPrompt_nsfwV2FP8H.safetensors. There are only two V2 NSFW versions, the other one is named fast move. So it makes sense that this one matches what you have.
So I think the one you’re missing would be: wan22EnhancedNSFWCameraPrompt_nsfwV2FP8L.safetensors. Look at the top, in the model selection: it’s named NSFW V2 FP8 L, but I’m not sure if it actually matches. I don’t understand how it’s possible to have different names lol.
@jojulori12186 fast move is this one for me: wan22EnhancedNSFWCameraPrompt_nsfwFASTMOVEV2FP8H.safetensors, so the name is normal. Here is the name that I personally uploaded and that Civitai changed: Wan2_2-I2V-A14B-NSFW_fast_move-LOW_FP8(lightning_edition)V2.safetensors.
@jojulori12186 I can only give you one piece of advice to be sure: take these NSFW FAST MOVE V2 FP8 H and NSFW FAST MOVE V2 FP8 L, or NSFW V2 FP8 H and NSFW V2 FP8 L. They are slightly different; check the description for more details.
I places the nsfw fast move v2 fp8 h i on the diffusion models folder and im gonna give it a try. Maybe thy are renamed or something. Thanks!
@jojulori12186 Yes, unfortunately, as I told you, Civitai renames them and they don’t become clear. I guess they have their reasons for doing this.
@taek75799 Yeah, i tought i was going crazy. couldnt find it haha. Thank you mate, now ill do some testing!
whats the difference between regular diffusion model and gguf
Hello, VRAM consumption is the most important point. It depends on your setup. Let’s say the regular one is FP8, which is roughly equivalent to K5 in terms of precision while being less resource-hungry. So Q6K will be more precise, and Q8 even more, and it will be very close to the FP16 version.
I'm getting very impressive results right from the beginning, no add on LORAs even required! Nice work. I wish you would do a NSFW T2V version ;)
Hello, and thank you for your feedback. To be honest, I made a T2V version because many people asked for it, but I don’t master that type as well. I did my best, but it’s not as good. I don’t know if I’ll focus on it further: the nsfw models, especially V2, took me a huge amount of time and work, mainly to test everything thoroughly so it works well in all situations.
If you want, you can try to “transform” the I2V version into a T2V version with a simple trick: just put a white image in load image and write your prompt. Personally, I’ve never tried it, but several people told me about it. If you want, you can give me feedback on this trick to see if it actually works, although I think it probably does.
I almost forgot: since there’s a white image, you will have a few frames showing that image at the beginning. I don’t know if it’s visible to the naked eye.
COLOR ISSUES:
First I want to thank you for this great model and for the time that went into creating it. The results are impressive and the improvements are clear.
I would like to document a color pale issue that I can reproduce reliably. When extending videos the subject becomes lighter with each new segment. After the second or third extension the skin tone starts losing saturation and quickly becomes pale. This is much stronger than the usual mild drift that WAN models often show. It appears even with low denoise, fixed seeds, no padding, no color matching and with SageAttention either on or off.
For testing I am not using any LoRAs and only a simple prompt:
A woman gives a wink to the camera, her expression is neutral.
The issue can currently be confirmed in the following models on my system:
wan22EnhancedNSFWCameraPrompt_nsfwV2FP8
wan22EnhancedNSFWCameraPrompt_nsfwFASTMOVEV2FP8
wan22EnhancedNSFWCameraPrompt_nsfwFP8
(the last one shows the effect but slightly lighter than V2)
I will test more model variations later.
To reproduce the issue simply use the same workflow and keep extending by feeding the last frame back into the pipeline. After the second or third generated video the whitening becomes very visible. I am using 1024 resolution for testing with real high quality photos as the initial image.
The following model does not show the strong whitening for me and stays stable even without any colormatch applied:
wan22EnhancedLightning_v2I2VFP8HIGH.safetensors
SHA256 79B66EC4C3272BE4BD56B4A2CAE940D0772EBE6D75EB9FE2DFA658247DA15738
I include the SHA256 because some filenames have changed and different builds behave differently.
I am using the latest native workflow for this model:
https://civitai.com/models/2079192/wan-22-i2v-native-enhanced-lightning-edition
Everyone who experiences this issue is welcome to comment so we can compare results and help identify what is causing it. I kindly recommend generating a long five by five seconds test video before releasing the next update, because the problem shows itself clearly during longer chained extensions.
I hope this helps to track down the source of the color pale behavior.
thank you for information. I'll try with wan22EnhancedLightning_v2I2VFP8HIGH.safetensors
@zzozz ty too, lets continue the conversation here then
can you tell me the link of wan22EnhancedLightning_v2I2VFP8HIGH.safetensors?
I searched civitai and google, but can't find it.
This is what I always test when I first download a model.
I put the same image in the first and last frames and try looping the video.
I've had this issue with every model I've tried so far:
dasiwaWAN22I2V14B_midnightflirt, dasiwaWAN22I2V14B_lurenoir, smoothMixWan22I2VT2V_i2v, Wan2.2-I2V-A14B.
And I've had this issue with every model I've tried, including WAN 2.2 Enhanced NSFW, fastmove, V2, and V2 fastmove.
@zzozz Possibly, the problem with all these models, including mine, comes from them being merges with certain nsfw loras. Maybe try the cam V2 version: it only has very few loras. By the way, it’s the version I use all the time.
@zzozz I can upload is it if the author is ok with it, will remove after you have downloaded it too then
@taek75799 good info, will try now
@juliusmartin I think it’s the V2 cam. It no longer has the same name; I changed it myself and reuploaded it, but it’s named V2 and isn’t NSFW. So this is indeed the cam V2. However, you can take the Q6K or Q8 version if your PC can handle it.
@juliusmartin Thank you. I would appreciate it if I could download it with the author's permission.
@juliusmartin It won’t be NSFW. In fact, I always recommend taking the cam V2 and using appropriate LoRAs for the scenes you want; this will cause fewer problems.
@taek75799 Wan2.2-I2V-A14B is pure version. no lora and just q8 gguf.
link is here. https://civitai.com/models/1820829/wan22-i2v-a14b-gguf
but it have problem too.
@zzozz @taek75799 no re-upload needed, the master was right:
wan22EnhancedLightning_v2I2VFP8HIGH.safetensors -Algorithm SHA256 79B66EC4C3272BE4BD56B4A2CAE940D0772EBE6D75EB9FE2DFA658247DA15738
wan22EnhancedNSFWCameraPrompt_v2CAMI2VFP8HIGH.safetensors -Algorithm SHA256 79B66EC4C3272BE4BD56B4A2CAE940D0772EBE6D75EB9FE2DFA658247DA15738
version "79B66EC4C3272BE4BD56B4A2CAE940D0772EBE6D75EB9FE2DFA658247DA15738" is extremely special
will test the mentioned gguf too
@juliusmartin You can also look at the prompt structure in the description: it helps to add dynamism and avoid WAN slowdowns, and to use the painter i2V node, which also helps. In the preview videos, there are also some examples (the one made with the shark to help), and in the description, if you like to play with the camera, they are listed.
@juliusmartin @taek75799 I downloaded wan22EnhancedNSFWCameraPrompt_v2CAMI2VFP8HIGH.safetensors
but SHA-256 is different. AB1D6661ACE820F7CA5BFE9D478FB64FD09804DE116FC897E4EFC6050A241228
is this link right?
@zzozz
you were right, I have re-downloaded wan22EnhancedNSFWCameraPrompt_v2CAMI2VFP8HIGH.safetensors and got the following hash too
AB1D6661ACE820F7CA5BFE9D478FB64FD09804DE116FC897E4EFC6050A241228
now I have uploaded and re-downloaded my prev downloaded wan22EnhancedLightning_v2I2VFP8HIGH and got the following hash
79B66EC4C3272BE4BD56B4A2CAE940D0772EBE6D75EB9FE2DFA658247DA15738
I have allowed myself to host this for 1-2 hours until you have downloaded it
https://huggingface.co/rebifo9573/wan22EnhancedLightning_v2I2VFP8/tree/main
lemme know once you (both?) have downloaded it, so we are talking about the same model
@juliusmartin thank you very much.
downloading.
btw, civitai provide hash at detail tap. click > button to change method.
@zzozz I guess you are having good results :)
@juliusmartin before go to sleep I ran just a quick test.
end frame problem is same as other models.
can't make natural loop video.
everything is yellow or greenish dark tint. I'm using a normal workflow 14b template 20+20 steps
Good day. Try to use "V2 CAM I2V FP8", but get this error "FP8 scaledmm failed, falling back to dequantization: Bias must be either Half or BFloat16, but got Float8_e4m3fn". Someone know how to fix it?
I don’t know this error, I’ll try to look into it.
I wonder if it’s related to the recent Civitai bug where people couldn’t download files.
Hmm… it’s possible the file was corrupted for a while, I’m not sure.
Have you tried a GGUF version?
@taek75799 i'm nooby in all this. I use wan 2.2 i2v a14b fp8 template workflow from comfyui. All working with original wan fp8. After downloaded your model, just replaced orginal wan models with yours, and after hit "run" and system try to go to ksampler got this error. If i replace model's weight_dtype from original "...e4m3fn" to just "default" it starts working. But with orig wan model realystic style image result pretty good (visually), but with your model with same image and res, result have a little (but in comparison, notisable) cartoonish style, some kind of more contrast, more smoothness skin (but sooo better prompt understanding and recreating it). Maybe this because of weight_dtype? Also, don't know how to use with gguf versions.
@saputini I see. Would it be possible to send me the workflow with the same parameters you used that produce the error? (Same model, same settings, etc.)
Here is a simple link you can use to upload your JSON so I can check it:
https://www.swisstransfer.com/fr-fr
Hello! Thank you for your work. I'd like to ask: what Lighting lores are used in the NSFW FAST Move model? The description says 2.2 and 2.1, but which versions and what forces are used? Is it possible to get a download link for the GGUF NSFW FAST MOVE model without the acceleration lores so I can use my own with unique weights?
Hello, yes that's correct: I use the latest lightning WAN 2.2 for the fast move version, and for WAN 2.1, sorry, I don’t remember, but I can check the information on my laptop, which I don’t have with me right now.
I’ll get back to you with the details.
I would need to make the fast move models without LoRA I don’t mind doing it but I can’t make them in GGUF, only in FP8.
It takes some time, and I’ve been short on time lately, or I’ll do it when I can.
One man made Lora the "Ultimate Pussy and Anus helper" If you could use this Lora model in your model, it would become legendary.
Thank you for your comment, the lora looks excellent from what I can see. I’ve set it aside.
The creator allows using their LoRA. I need to check if everything works fine with it.
Unfortunately, I’ve already tried another LoRA (Pussy), and it transformed male genitalia into pussy.
This is really a problem with this kind of LoRA trained on women. It’s very hard to get something correct in every situation.
That’s why in the description, I included some examples made with LoRA.
In my opinion, this is the best solution to have the most stable model possible in a maximum number of situations while being able to do most things.
@taek75799 I understand you, thanks for the reply.
Can you please tell me the versions of the things you use:
1)comfyui
2)python
3)pytorch
4)cuda
5)sageattention
6)triton
if possible anything more i need to reproduce your version decently. I am only asking this because for some reason my outputs simply don't line up with expected outputs for a lot of loras, for example some guys used seko lightning loras for some specific loras and got very good results, while i got extremely poor results. I am not sure if this is because im using a weird combination of comfyui and other things, im using an old comfyui version(because i oom on a new version for some reason). I have never actually used sageattention yet, but since outputs usually only get worse with it, i dont think it matters, something is messed up from my end. can u help please?
Hello Donaldi, of course.
I personally use an older version of ComfyUI to create WAN videos. Here are your ComfyUI details:
ComfyUI portable 0.3.66, Python 3.12.10, PyTorch 2.7.1 + CUDA 12.8, Sage Attention 2.2, and Triton 3.2.0 post 13.
Don’t pay attention to Triton and Sage Attention unless you want to install them: they are only used to speed up inference and slightly degrade the video, even though it’s very, very minor; the result will remain the same.
By the way, are you using a Lightning LoRA with my model? You mentioned Seiko. If so, do not do that at all — it will degrade the video.
So if you are using an older version of ComfyUI like me, it should work. Take a video from the previews, any one except those longer than 5 seconds (they no longer contain metadata). Put it on your desktop and drag it into your ComfyUI interface: you should get the workflow that was used to generate the video.
Feel free to come back if you still encounter any issues.
Any new workflow from you?
Hello, I’m using a new method to create excellent transitions via Fun Vace. I need to incorporate it into the workflow, but it’s not simplified yet. I need to automate everything, and I’ll upload it to Civitai as soon as it’s done.
PLEASE WHAT TEXT ENCODER I USE WITH THIS MODEL?
Hello, this one:
https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/blob/main/split_files/text_encoders/umt5_xxl_fp8_e4m3fn_scaled.safetensors Or the NSFW version. I invite you to check the link in the description: there is also a comparison between the one provided here and the NSFW version.
What is the speed/time difference between fp8 to q4 ?
not sure why but my q4 doesn't do better for speed or quality..
I think fp8 and q4 are equivalent, and fp16 to a q8
Hello, it depends on your GPU. The Q4KM will work on a GPU with less VRAM.
Many people request the Q4KM versions because FP8 doesn’t work for them.
The equivalent of FP8 would be Q5.
I have 16 GB of VRAM, so I use Q8. It’s the most precise model and very close to FP16.
@taek75799 Thank you !
@Rainart1989 No
@Rainart1989 yes fp8 is very bad with details and higher resolution sometimes it breaks..
Details
Files
wan22EnhancedNSFWSVICamera_nsfwFASTMOVEV2FP8H.safetensors
Mirrors
wan22EnhancedNSFWSVICamera_nsfwFASTMOVEV2FP8H.safetensors
wan22EnhancedNSFWSVICamera_nsfwFASTMOVEV2FP8H.safetensors
wan22EnhancedNSFWCameraPrompt_nsfwFASTMOVEV2FP8H.safetensors
wan22EnhancedNSFWCameraPrompt_nsfwFASTMOVEFP8High.safetensors
wan22EnhancedNSFWCameraPrompt_nsfwFASTMOVEV2FP8H.safetensors
wan22EnhancedNSFWCameraPrompt_nsfwFASTMOVEV2FP8H.safetensors
wan22EnhancedNSFWSVICamera_nsfwFASTMOVEV2FP8H.safetensors
wan22EnhancedNSFWSVICamera_nsfwFASTMOVEV2FP8H.safetensors
wan22EnhancedNSFWSVICamera_nsfwFASTMOVEV2FP8H.safetensors
wan22EnhancedNSFWSVICamera_nsfwFASTMOVEV2FP8H.safetensors