⚠️ Important information
All models already include the Lightning LoRAs, except the SVI models, where Lightning is not included.
Do not use additional Lightning LoRAs on models that already have Lightning integrated, or the quality will be degraded.
For SVI models, you can use Lightning LoRAs if you want faster video generation.
2or3 ksampler (for svi) https://civarchive.com/models/2079192?modelVersionId=2668801
v2.1 (for nsfw v2) https://civarchive.com/models/2079192?modelVersionId=2562360
v2.1 with MMAUDIO (for nsfw v2) by @huchukato https://civarchive.com/models/2320999?modelVersionId=2613591
Another wf triple KSampler KSampler https://civarchive.com/models/1866565/wan22-continuous-generation-svi2-pro-or-gguf-or-32-phase-or-upscaleinterpolate-w-subgraphs-and-bus?modelVersionId=2559451
triple KSampler wf setup allows for more motion and helps prevent slow-motion issues. In exchange, your videos will take longer to generate.
For those having issues with my SVI workflow , you can try Kijai's wf here: https://github.com/user-attachments/files/24364598/Wan.-.2.2.SVI.Pro.-.Loop.native.json. Alternatively, you can try fmlf wf https://github.com/wallen0322/ComfyUI-Wan22FMLF/tree/main/example_workflows they will be simpler. There are others on Civitai that work very well too.
Qwen-VL workflow as an alternative to Grok for creating your dynamic NSFW prompts. Thanks @huchukato for his work: https://civarchive.com/models/2320999?modelVersionId=2611094
🟣 SVI Update – NSFW
⚡ Model Presentation (SVI-compatible version)
This update was made because the NSFW V2 models were not fully compatible with SVI LoRAs.
This version was created to work smoothly with SVI, while still functioning without them (though the workflow must be adapted).
Be careful, SVI LoRAs will only work with a workflow specifically designed for them, otherwise, it won't work.
There are two models available for SVI:
✔ Fast Move (FM) – Sexual scenes may differ from the Consistent Face model and will generally be faster.
✔ Consistent Face (CF) – Slightly better image quality, which may be preferable for anime-style videos; sexual scenes differ from Fast Move, but the difference is minimal.
You can also mix models between High and Low LoRAs:
FM (Fast Move) as High + CF (Consistent Face) as Low
CF (Consistent Face) as High + FM (Fast Move) as Low
Both combinations work and give slightly different results, offering more flexibility for your videos.
For this version, the main improvements include:
✔ Fully adapted for SVI LoRAs
✔ Greater flexibility: Lightning and SVI LoRAs must be loaded manually for custom workflows
🟣 SVI LoRAs – Strengths & Weaknesses
⚡ Overview
✅ Strengths
Best solution for making long videos
Excellent transitions between video segments
Reduced degradation compared to other solutions
Strong character coherence: the model retains information from the previous video, helping maintain consistency
⚠️ Weaknesses
Weaker prompt understanding
Weaker camera understanding
Videos are less dynamic
Sometimes slow-motion effect
(can be improved with proper Lightning LoRAs, dynamic prompts or triple ksampler)
🟣 SVI LoRAs – Download Links
⚡ Download
Note: Both LoRAs must be loaded manually in your workflow.
🟣 Suggested Lightning LoRA Combos (Optional)
⚡ Overview
You don’t have to use these Lightning LoRA combos. They are optional and allow you to fine-tune motion and degradation.
You can also use other Lightning LoRAs or assign different combos per video for more control.
🔥 Combo 1 – More Motion (Rapid Video Degradation)
High LoRA →
https://huggingface.co/Kijai/WanVideo_comfy/blob/709844db75d2e15582cf204e9a0b5e12b23a35dd/Lightx2v/lightx2v_I2V_14B_480p_cfg_step_distill_rank128_bf16.safetensors
Weight: 4
or
💜 Combo 2 – Less Image Degradation
or
or
🟢 Combo 3 – Balanced Motion / Moderate Degradation
High LoRA →
https://huggingface.co/Kijai/WanVideo_comfy/blob/709844db75d2e15582cf204e9a0b5e12b23a35dd/Lightx2v/lightx2v_I2V_14B_480p_cfg_step_distill_rank128_bf16.safetensors
Weight: 3
Low LoRA →
https://huggingface.co/Kijai/WanVideo_comfy/blob/709844db75d2e15582cf204e9a0b5e12b23a35dd/Lightx2v/lightx2v_I2V_14B_480p_cfg_step_distill_rank128_bf16.safetensors
Weight: 1.5
🧠 Advanced Usage Tip
You can disable global Lightning LoRAs (in my wf) and assign different combos per video:
Combo 1 for Video 1, Combo 3 for Video 2, Combo 2 for Video 3.
Each combo produces different motion and degradation behavior.
If you want to create several-minute-long videos while maintaining high quality, it is possible, but it will take a very long time. You just need to avoid using Lightning LoRAs and use the full model instead.
🧠 Dynamic Prompts – Better Control & More Motion
You can use dynamic prompts to have better control and this helps to make the video more dynamic.
You just need to give this example prompt to an LLM like ChatGPT. It will be enough for it to describe the image you have and what you want as a video while keeping the same structure of the prompt in the following example.
⚠️ This will be a NSFW prompt; ChatGPT will not accept it.
You can use GROK https://grok.com, which can make NSFW prompt modifications.
For more examples of prompts with different poses, check:
Enhanced FP8 Model.
Give these prompts to GLM with the dynamic prompt structure if you want.
Example 1
(At 0 seconds: Wide shot showing a slightly overweight man casually walking down a city street, camera fixed in front, urban environment with buildings and cars.)
(At 1 second: Suddenly, a massive shark bursts from the pavement ahead, looking terrifying at first, pavement cracking, dust and debris flying, camera from side angle.)
(At 2 seconds: Medium shot from the side, the man stumbles backward in shock, while the shark dramatically slows down and strikes a comically exaggerated sexy pose, revealing large, exaggerated shark breasts, covered by a colorful bikini.)
(At 3 seconds: Close-up on the man’s face, eyes wide in disbelief, as he turns to look at the shark, small cartoon-style hearts floating above his head to emphasize his amazement, camera slightly low-angle.)
(At 4 seconds: Dynamic travelling shot showing the man frozen in the street, the shark maintaining its sexy pose, water splashes and debris still moving realistically, urban chaos around.)
(At 5 seconds: Wide cinematic shot pulling back, showing the man standing in the street, staring at the bikini-wearing shark with hearts above his head, epic perspective highlighting absurdity and humor.)
Example 2 – Anime NSFW
(At 0 seconds: The couple in a cozy bedroom, anime style, soft lighting highlighting their intimate embrace, her back arched slightly as he positions himself.)
(At 1 second: The man’s hips moving rhythmically, the head of his penis sliding effortlessly into her vagina, her body responding with a gentle, fluid motion, anime-style motion lines emphasizing the smooth penetration.)
(At 2 seconds: Her back arching deeply against him to intensify the pleasure, hips swaying with each thrust, breasts bouncing subtly, small hearts floating around them to capture the erotic energy.)
(At 3 seconds: Her face, eyes closed in bliss, a soft moan escaping, hands resting behind her head, anime-style blush on her cheeks, the air filled with a seductive aura.)
(At 4 seconds: The man penetrating her deeply, her body moving in sync with his, the bed sheets slightly rumpled, the room’s warm lighting enhancing the intimate, lustful atmosphere.)
(At 5 seconds: The couple locked in a passionate embrace, the scene exuding vibrant, seductive energy, anime style with smooth lines and soft shadows.)
🟣 Lightning Edition – NSFW I2V V2
⚡ Model Presentation (2 new versions available)
I originally planned to release only one V2, but some people preferred the NSFW V1 over the Fast Move V1 version, so depending on what you’re looking for, one version may suit you better than the other.
For these V2 versions, I tried a new approach:
✔ I made sure that most sexual poses work, while the model is also good for SFW content
✔ More flexible for general use
🔥 NSFW Fast Move V2
Improvements included in this version:
Better prompt understanding
Better camera understanding
Reduced unnecessary back-and-forth movements outside sexual poses
(cannot be completely removed, but strongly reduced)Improved bounce effect on the buttocks
If a man appears, he will no longer automatically attempt to penetrate the woman when she is nude
This version is designed for those who want more dynamic scenes with more movement.
💜 NSFW V2
The difference between this version and NSFW Fast Move V2:
Less camera control
Less camera understanding
But body movements are less pronounced (breasts and buttocks)
Some preferred V1 NSFW to V1 NSFW Fast Move, and this version keeps that spirit
For varied sexual poses, check the previews — there are many.
You can use the shown prompts and adapt them to your images, but of course, other prompts will work as well.
Don’t hesitate to use other LoRAs for creating specific concepts.
🔧 Recommended Settings
Steps: 2+2
(Jellai recommends 2+3 for even better results, and I agree)Sampler: Euler simple
CFG: 1
This model already includes the Lightning LoRAs, don’t use them, or the quality will be degraded
You need to download both models: H for High and L for Low.
Here is an example made with the base workflow + the First/Last Frame workflow + upscaler (only on the starting images) + inpainting (cum).
https://civarchive.com/images/114733916
🔞 LoRA Examples (with links and recommended weights)
LoRA: Penis Insert WAN 2.2
LoRA weight: 1
Face → Doggy
https://civarchive.com/images/112864483Face → Missionary
https://civarchive.com/images/112864718
https://civarchive.com/images/112864835Face → Doggy (leg aside)
https://civarchive.com/images/112864885Another example
https://civarchive.com/images/112864972
Other examples with different LoRAs
Face → Reverse Cowgirl — LoRA weight: 0.7
https://civarchive.com/images/112865189Face → Cowgirl — LoRA weight: 0.5
Face → Missionary — LoRA weight: 0.3
https://civarchive.com/images/112865381Face → Missionary — LoRA weight: 0.5
Face → Doggy leg aside — LoRA weight: 0.6
https://civarchive.com/images/112865551Face → Doggy — LoRA weight: 0.7
https://civarchive.com/images/112865696Face → Spoon — LoRA weight: 0.7
https://civarchive.com/images/112868124
Recommended LoRA to obtain a very realistic vagina and anus:
https://civarchive.com/models/2217653?modelVersionId=2496754
💡 Tip for Anime Style:
If you’re working in an anime style, feel free to follow the advice of @g1263495582 thanks to him for this.
Try these LoRAs together or separately; they help maintain face consistency:
🔹 Note:
For these LoRAs, use only Low Noise.
For the examples mentioned above, use High and Low Noise as indicated.
LoRA weight: 0.3
Many things can be done with the model, but don’t hesitate to use other LoRAs for specific purposes. And don’t hesitate to lower the LoRA strength to preserve the face as much as possible.
📷 Dynamic prompt example with different camera angles:
(at 0 seconds: wide shot showing the woman standing in the snowy plain, a massive giant dragon emerging behind her, snow cracking and dust rising).
(at 1 second: the woman jumps backward onto the dragon’s back as it bursts fully from the sky, camera tracking the motion from a side angle, debris and snow flying).
(at 2 seconds: medium shot from the side, the woman balances heroically on the dragon’s back as it begins to run forward across the snowy plain, slow-motion on her posture).
(at 3 seconds: close-up on the woman’s determined face, camera slightly low-angle to emphasize her heroic stance, snow and debris flying around).
(at 4 seconds: dynamic travelling shot alongside the dragon, showing the snowy plain, scattered debris and ice fragments flying everywhere as it gains speed).
(at 5 seconds: wide cinematic shot pulling back, showing the dragon taking off with the woman riding on its back, soaring above the snowy plain, epic perspective with snow, wind, and scale emphasizing the drama).
For available camera angles, check further down in the “cam V2” model description.
🔞 Normal Clip vs NSFW Clip:
You can also use the NSFW version for your clip.
It can bring positive effects for sexual scenes, but it can also cause issues, as in this example:
NSFW Clip:
https://civarchive.com/images/112864204Normal Clip (same seed):
https://civarchive.com/images/112864295
Here are the links to NSFW clips (thanks to zoot_allure855 for correcting the BF16 version):
BF16 fixed version:
https://huggingface.co/zootkitty/nsfw_wan_umt5-xxl_bf16_fixed/tree/mainFP8 version:
https://huggingface.co/NSFW-API/NSFW-Wan-UMT5-XXL/tree/main?not-for-all-audiences=true
❓ If you have any questions, don’t hesitate to ask!
Many people ask me for help via private message. You can do that, no problem, but I would appreciate it if you could do it in the comment section, it could help other people. Thank you.
🟣 Lightning Edition – NSFW I2V camera prompt adherence
⚡ Model Presentation (2 versions available)
I decided to release 2 versions. Both can produce different results, as you can see in the previews (the seed was the same).
Fast Move Version: provides more movement, and the movements will be faster, with better prompt understanding and camera handling
(you can see it in the 4th preview "fast move high" where the man slaps the woman)Natural Motion Version: offers more natural breast movements depending on the situation and produces slower scenes.
👉 Check both and choose the one that works best for you.
This NSFW edition is, of course, focused on sexual poses.
You should achieve very good results.
To create specific concepts, feel free to use specific LoRAs — they work very well with this model.
🔧 Recommended Settings
Steps: 2+2
(Jellai recommends 2+3 for even better results, and I agree)Sampler: Euler simple
CFG: 1
This model already includes the Lightning LoRAs, don’t use them, or the quality will be degraded
You can also use this T5, which may improve understanding:
https://huggingface.co/NSFW-API/NSFW-Wan-UMT5-XXL/tree/main?not-for-all-audiences=true
📝 Usage Tips
Start with a clean, high-resolution image for better results.
The model will not change the face; if it does, increase the resolution.
Also adjust your prompt if you are not getting what you want.
Wan understands some terms well, but not all.
For prompts, check the video previews: adapt them to your image.
Other prompts will work too.
🎥 Training
I trained 2 LoRAs:
The first one using several videos and images of different sexual positions.
The second one to bring more dynamic motion.
Respect to everyone who creates this type of LoRA — it requires a lot of work.
🙏 Credits
This model wouldn’t exist without the incredible work of these creators:
alcaitiff : https://civarchive.com/models/1295758/nsfw-fluxorwan-22orqwen-mystic-xxx?modelVersionId=2300332
Sweet_Pixeline : https://civarchive.com/models/1844313/penis-play-wan-22
anonimoose : https://civarchive.com/models/2008663/slop-twerk-wan-22-i2v
dtwr434 https://civarchive.com/models/1331682?modelVersionId=2098405
A special thanks to Alcaitiff and CubeyAI, two very kind and humble people.
🔔 Important
Please don’t support my work with buzzes here, I don’t need it.
If you want to support someone, support the creators listed above — they truly deserve it.
💬 Feedback
Feel free to give me feedback, positive or negative, to help improve future updates.
Update WAN 2.2 V2 CAM I2V – NEW feature Camera & Prompt Improvements
This custom version of WAN 2.2 I2V has been updated to deliver better prompt comprehension and improved handling of camera angles and cinematic movements. It provides more accurate scene interpretation, smoother transitions, and enhanced control over dynamic.
Key Features:
Excellent understanding of prompts and scene composition.
Supports various camera angles and movements, including zoom, dolly, pan, tilt, orbit, tracking, and handheld shots.
Ideal for cinematic storytelling, animated sequences, and creative video-to-image projects.
Flexible multi-step prompts, standard 4 steps (2+2), can be increased for higher fidelity.
Recommended sampler: Euler simple.
You can, of course, use your usual prompts; this is just one example among many.
Example Prompt with Different Camera Angles
(at 0 seconds: wide frontal shot of a man standing in front of an open fridge, cinematic lighting, subtle ambient kitchen reflections, the fridge contents visible, camera static).
(at 1 second: medium shot from the front as he opens the fridge fully, reaches for a can, slight zoom-in to emphasize the action, cinematic framing).
(at 2 seconds: camera shifts to a side medium shot, tracking him as he lifts the can to his mouth, fluid movement, maintaining lighting and reflections).
(at 3 seconds: camera starts a smooth 360-degree orbit around the man, following him as he drinks from the can, motion fluid, background slightly blurred for cinematic effect).
(at 4 seconds: close-up on his face and upper body while drinking, orbit continues subtly, fridge reflections accentuating realism, cinematic polish).
(at 5 seconds: final wide shot as he lowers the can, camera completes orbit to original angle, showcasing the kitchen space, lighting, and dynamic movement).
Available Camera Movements
Zoom / Dolly
zoom in
zoom out
camera zooms in on subject
camera zooms out gradually
dolly in
dolly out
camera dollies in slowly
camera dollies out steadily
crash zoom
Pan
pan left
pan right
camera pans across the scene
gentle pan left
sweeping pan right
Tilt
tilt up
tilt down
camera tilts up to reveal…
camera tilts down from…
Orbital / Tracking / Arc / Rotation
orbit around subject
360° orbit
camera circles around
tracking shot
camera tracks alongside subject
arc shot
curved camera movement
Other Movements & Styles
static camera / static shot
handheld shot
camera roll
Note:
LoRAs work perfectly with this model, offering full compatibility and consistent results across styles and concepts.
# SUPPLEMENTARY ADVICE
You can use negative prompts, but be careful: this will double the generation time.
Only use them if you really want to prevent something from appearing in your video.
In that case, enable the corresponding node; otherwise, keep it disabled.
⚠️ Important
The model must be used with CFG set to 1, so negative prompts do not work by default.
However, there is a simple way to enable them.
How to enable negative prompts:
Open the Manager
Search for kjnode and install it
In your workflow, add the WAN Nag node
To use it correctly:
Connect this node after the LoRA Loader
Feed it with the negative prompt
Then connect it to the first kSampler (High)
👉 Only use this option when necessary, to avoid unnecessarily increasing generation time.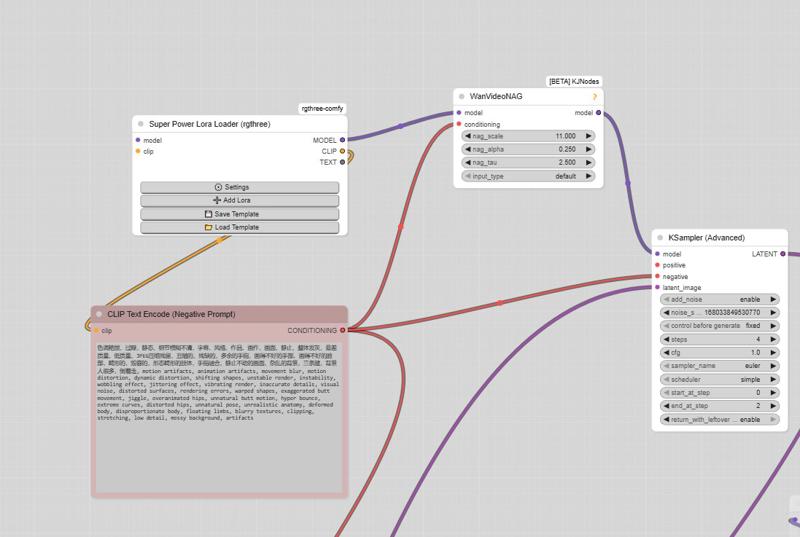
And here is the negative prompt for unwanted movements:motion artifacts, animation artifacts, movement blur, motion distortion, dynamic distortion, shifting shapes, unstable render, instability, wobbling effect, jittering effect, vibrating render, inaccurate details, visual noise, distorted surfaces, rendering errors, warped shapes, exaggerated butt movement, jiggle, overanimated hips, unnatural butt motion, hyper bounce, extreme curves, distorted hips, unnatural pose, unrealistic anatomy, deformed body, disproportionate body, floating limbs, blurry textures, clipping, stretching, low detail, messy background, artifacts, butt bounce, moving hips, swinging hips, shaking butt, wiggling butt, moving lower body, moving pelvis, jiggling buttocks, bouncing butt, unstable stance, unnatural hip motion, exaggerated hip movement, hip sway, hip rotation, bottom motion, pelvis motion, wobbling hips, fidgeting lower body, dancing hips, pelvic movement, motion blur, unnatural movement
And here is the negative prompt from the official ComfyUI workflow:色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走
Note: If you use the default workflow without the node, this negative prompt will not work.
UPTDATE: Lightning Edition – T2V
I’m not really experienced with T2V myself, but a colleague who works with it a lot tested this version and confirmed that it performs very well. From the few tests I managed to do on my side, I got the same impression, although I haven’t compared it directly with the base version yet.
The settings are the same as in the image-to-video version: 2+2 steps or more if you prefer, CFG at 1, and Euler simple (though other samplers also work great).
I don’t plan to make an NSFW version for the T2V release,
but for the I2V version, I’m already quite happy with the first results.
Update WAN 2.2 V1.1 I2V
Updated version of the original Lightning merge — same settings 2+2 steps or more, featuring more movement and smoother flow (depending on the prompt).
The model already works very well in NSFW. Just use the right LoRAs, and the movement will improve.
WAN 2.2 V1 I2V
This checkpoint is based on the original WAN 2.2, with the Lightning WAN 2.2 and Lightning WAN 2.1 LoRAs already integrated. This improves image quality, makes motion smoother and more dynamic, and removes the slow-motion effect that can occur with the Lightning models.
A common setup is to use 2 steps on the high model and 2 steps on the low model, though other settings may work as well. Do not apply the Lightning LoRAs manually — they’re already included in this checkpoint.
My workflow
https://civarchive.com/models/2079192/wan-22-i2v-native-enhanced-lightning-edition
Description
FAQ
Comments (212)
any non-guff models coming out anytime soon? Also, what model did you use to create these images? They're amazing. Thanks!
Is there a guide on how to get this up and running?
It's not clear what VAE, text encoder or example workflows. I've spent hours and can't figure how to run it.
I use runpod so I have no limitations on GPU and ram so I assume I don't have to both with lightning, GGUF etc?
Hello! Just download the workflow; inside, you will find the links for the VAE, Text Encoder, etc. Then, you just need to replace the files in each node with your own.
@taek75799 I'm in the same boat. Downloaded this and the workflow, downloaded all the files from the tutorial and tried to replace as best as I could... There is no low Unet loader file so im just using the high one twice, and my images come out as noise with barely a resemblance of the image everytime.
@swiftycross1736 Hello! Look at the top of the page; there is the H (High) model and the L (Low) model. Download both, and everything should work fine.
@OP do you have any plans to update your workflow and add the DIT nodes for cache improvements? Not sure if it applies here but they apparently reduce generation time substantially.
Hi, no need. You just have to add a node after the model loading: https://github.com/rakib91221/comfyui-cache-dit
I'm using Q8 model, 4High 4 Low. I didn't use ModelSamplingSD3 nodes (Should i add it?)
The problem occurs on FLF2V workflow.
Is there a solution for camera shake/moving camera, other than adding wan nag/increasing CFG ?
positive clip such as (static camera:2) doesn't seems working.
As for the clip itself, I didn't use (at 0 second) (at 2 second).
Instead, full paragraph such as
(camera static:2). the girl is chopping a log of tree with axe. After chopping a log, the girl wipes his face with towel. 16FPS.
Hello! It depends on which model you are using. If it's the SVI models, they might struggle to understand camera movements. For that, you should try the Cam V2 model instead. As for the First Frame / Last Frame feature, I haven't experimented much with cameras, so I'm not sure if it will work well.
Does anyone else have the problem that the model overflows the RAM and causes the system to freeze? I don't have this problem with other models, only with this one. I've already tried the Q6 and Q8 models and have the same problem with both. I have 64 GB of RAM and 16 GB of VRAM. The model seems to put a lot of strain on the RAM; after the second run, the RAM is 99% full and the VRAM is at 85%. I've tried a lot of things but haven't been able to fix the problem yet. Thanks for the checkpoint.
its not just this model. its most models. there is a node called "Cache Cleaner". this is the only node that works. put it in the end of the workflow before the "combine video" node. your comfyui will never crash after that
@Johndoe1911 Thank you for this information. I will try out the node.
This is fake, cannot replicate what this showcases.
Hello! Actually, there are metadata in the videos. It's just like with images: you drag and drop the video into the ComfyUI interface, and the workflow used to create it will appear.
By the way, are the videos from other users under each model fake too? Lol!
Question: in your workflow, for "Lora No Lightning High" I am confused for what lora is truly recommended. I am using current gguf that you posted, SVI nolightning cf q8. Do I also need to add a "lora lightning high" and "lora lightning low" as well? thank you
Hello! When you use the 3 KSamplers, the two top LoRAs correspond to the High LoRAs; so, place the two High LoRAs there.
@taek75799 ok, great! what about in the box titled "new subgraph"? Currently I have these safetennor files there, in order and weight:
1: SVI_v2_PRO_Wan2.2-I2V-A14B_HIGHT_lora_rank_128_fp16; weight 1
2: SVI_v2_PRO_Wan2.2-I2V-A14B_LOW_lora_rank_128_fp16; weight 1
3: wan2.2_i2v_a14b_high_noise_lora_rank64_lightx2v_4step_1022; weight 2.5
4: wan2.2_i2v_a14b_low_noise_lora_rank64_lightx2v_4step_1022; weight 1.4
does this seem right?
@dongfordoob718 The LoRA weights seem way too high. The 1022 seems to work well with weights of 1 on each LoRA. Increase the weight if you are using the Lightning Wan 2.1 LoRAs. Check the description; you'll find a few examples there.
Question: I do not want to use SVI. I just replace with NSFW V2 H and L model in Wan22 workflow. Is it correct?
yep, and check step in workflow + remove lightning lora from workflow (if have).
Hello! Thank you for your work!
I got question. I want to create video from picture with closed girl who expose her breasts. But when she doing it, her nipples got white glow, like censorship.
Why it's happening, and what i need to do?
P.S. i don't change workflow. My subgraph looks like this: https://freeimage.host/i/fpgZ0XI
"Hello! Did you properly look for the SVI and Lightning models in your folder? When you load the workflow, it displays correctly, but you must also load the LoRAs. Perhaps your file paths are different. Which model are you using? In principle, there is no issue with the SVI or NSFW V2 models regarding the appearance of nipples. Take a look at some examples created by users: there are prompt examples where the girl takes off her top
I use "nolightning SVI cf Q8 H" and "nolightning SVI cf Q8 L".
All path are correct. When i use images with naked breasts, there is no problems.
Maybe i need some lora for exposed breasts?
https://freeimage.host/i/fp4x7Hb
If it's correct, why is 3 lora to load?
Try using a LoRA, it should work, but don't hesitate to lower the LoRA strength. The workflow uses 3 KSamplers to give more movement to the video; this is an issue related to SVI.@dementymail195
@taek75799 All work's now. Thank's for advice about promt!
i love your models, I wonder if you plan to have any SVI models with FAST MOVE, if possible that'd be amazing
hi and thx for ure feedback, unfortunately, I had to make some compromises. SVI doesn't work the same way, so I had to adapt the model.
@taek75799 understandable, do you know if there's any lora to obtain the same Fast move effect and the way the camera works on your other models?
@milkywayx I've never seen any other model or LoRA do it. The strength of SVI is undoubtedly the fact that you can create perfect transitions. You can do it with the NSFW V2 model as well, but it requires more work: you just need to create your generations and assemble them with Fun Face. Here is the workflow I use to join videos: https://civitai.com/models/2277993?modelVersionId=2573087
Thank you for your models and workflows overall works very well.
I'm facing a little issue using the SVI CF Q8 models, it does not matter what combination of lora I use but most of the time after 4 videos (~20secs) I start to loose the identity of the characters and they look totally different, not sure if there is something I can do to avoid this... anyone knows what I can try? Most of the time I generate in 720x720 or 720x1280.
Hi!.. I'm feeling a bit lost. Could you tell me which would be the best model or models, LoRas, etc. to maintain a face in I2V? I have an RTX 4090. TIA! 🤗❤️ And please share best workflow too! (upscaler)
"Hello! It depends on what you want to do. If you want NSFW with short videos, go with the NSFW V2 model. If you want longer videos, take the SVI CF model. And if you want SFW, use Cam V2. With your GPU, the Q8 version is preferable. For the workflow, check the description; you will find quite a few there.
wan2.2\Wan2_2-I2V-A14B-HIGH_consistent_face_Q8.gguf and wan2.2\Wan2_2-I2V-A14B-LOW_consistent_face_Q8.gguf nowhere to be found, so useless workflow
Skill issue XD
Has anyone used the NSFW V2 model with LoRas SVI? If so, what were the results?
Great on my end.
I did many test with this models. I used the Fast Move V2 with lightnings LoRAs before SVI. When SVI released, I did some videos with the same models but the Lightnings LoRAs were the cause of degradation (face drifts, colors drifts) with SVI.
The NoLightening SVI model versions are more stable with SVI for my opinion. A bit less flexible than the Fast Move V2 with lightnings LoRAs but way more consistent and gives you more degradation control.
If you intend to make long videos you should go with the NoLightnings models.
@thedrekt00 I haven't tested the NoLightnings models yet; I think the problem I would face now would be the increased number of steps with my low VRAM.
@geraut0 You can still use the lightnings LoRAs with them, it's just that you can choose wich Lightnings you want to use and at wich strenght, that was not possible with the Fast Move V2 with lightnings.
Thank you for your effort in this, I really enjoy using these models. Just curious, are any designed for T2V? I'm having 'some' success using the nsfw v2 model in a T2I workflow. It's so close to great but I can't quite get over that hump. I tried multiple samplers and steps. Probably not designed for this use but I can't help but feel it may be possible. Any thoughts?
Hello and thank you for your feedback! So you used the I2V model by loading a black image to "transform" it into T2V? Sorry, I'm not very familiar with T2V models using Wan. I made an SFW model a while ago because some people asked for it. I won't be able to help you; I hope someone else can.
@taek75799 Me too! Because it's about one Ritz cracker from God status. I don't think I'll be able to tweak out the fine detail and color I'm looking for as is but it's not bad still. Great for video, still good for image.
The FP8 works great for T2V, but the Q8 models do not (weird).
The question is: Why does a hint without a lighting lora work completely differently? For example: There is a character, another character should approach him from behind the scenes. With lighting lora, He appears normally, but without her, the other character doesn't want to appear at all. Without Lighting Lora, I set 30 steps. I tried to change the hint in different ways, I tried to change the clip-the result is the same: I can't make the character appear.
Did you split the steps into 15/15? Is it still High 15 / Low 15 steps?
@g1263495582 Yes. Split it. But still the result is the same. And if another character appears, then it's deformed. Strange. Maybe that's all I have. I just wanted to try it without Lighting lora. But if it doesn't work out, we'll do it the old-fashioned way)
The V_A_G_I_N_A Lora recommend is delated, can anyone tell me a new one for WAN 2.2 I2V?
sorry i'm so lost on terms and names, I have a RTX 3090 and want better NSFW than the base Wan2.2 Lightning 14B from Wan2GP, I saw you say to someone with 4090 to use "NSFW V2 Q8 High" I believe, but is that a lightning model? or how do I know from all the text in the description which bit to read and what steps to use with it? thanks
"nolightning Svi" models does not have lightening lora. you use regular steps (30 i believe) or use lightening Loras attached to workflow. all the others including "NSFW V2" models has baked in lightning. you can use 4 steps in total for both ksamplers, 2 steps for each
@gayanholmes787 thank you
Hello, why are the characters in the videos I run using the "NSFW V2 Q8 High" and "NSFW V2 Q8 Low" models in slow motion, and why are the faces in the videos blurry?
Something I've been playing around with recently is starting the video generation with a non-SVI pass. Your FP8 model with lightning loras baked in, 2 high 3 low. Then I use that latent as the previous samples for the SVI portion, and create an anchor sample from one of the last frames from that first generation.
This helps combat the generally slow motion that SVI generates on its own. Kickstarting the motion with something that's more dynamic allows SVI to continue that dynamic movement, rather than trying to force SVI to create that kind of movement in the first place.
Once again, I have to say thank you for these models and your constant improvements. I don't use your workflows because I prefer to build my own, but yours are a good reference point.
Keep up the great work!
Thanks for your work, but I gotta say both the README and the number of models and their names are very overwhelming. It's difficult to figure out what must be downloaded together with what. The README is a bit big and it has multiple models it recommends, so it's not really helpful.
What do I need to download to try out this model? Any help would be appreciated.
Yeah that's where I'm at, it's like some of the people on this site are allergic to a literal basic bulletpoint list saying 'Download this -> put it here' to just get it running on a basic level. I can't tell if I need to download like 120 gigs of shit with this or not. I don't even know where to put a .gguf!
First time I started with local image generation it took me two full days to figure it out, in part because literally every single piece of information older than a year is utterly obsolete and incompatible. Everyone in this space assumes you've got a computer science degree and have been playing with it for a decade with how they talk about, organize, and name things. Half the questions I would search about where to put models were wrong because they wouldn't specify between \StableDiffusion\ and \DiffusionModels\ and you just had to figure it out.
Any advice? With the FAST MOVE V2 Q8 I2V, how can I avoid characters to vomit cum all the time :D
I only want a classic vaginal cumbath. "He cums in her pussy, thick sticky cum oozing out of her vagina (ONLY INSIDE HER PUSSY, NOT THE MOUTH!)" or sth like it didn't work :(
its a bug bro, like sometimes she squarting with her tits
@kumarkishank959811 ... wow those are some NEXT LEVEL tits then. :)
Seems like no one is experiencing this, but the workflow is not generating frames. The output finishes and its 0 seconds long. I keep trying everything to fix it, but the video keeps generating at 0 seconds. I didn't mess with the workflow at all.
somthing similar.. I have tried different variations of FastMove and CF models and LoRas listed on this page. Either the position of the characters does not change or change so much that the video is all garbage. I would be really helpful if there is a video or the documentation is more clear on which model to use with which workflow.
add new node "video combine" . This worked for generating 5 seconds. I don't know if this same 0-frame issue occurs when generating longer videos, but maybe this will help there too, if the error persists.
@snake0000 It is helpful
What is the best settings to change if I want to improve the output quality and sharpness? I'm currently using your latest Q8 CF models and your SVI triple Ksampler workflow with default settings (7 total steps, 1 no lightning step, 4 high step) and render at 720x720. The output motion is nice, but the image itself is grainy/blurry and face consistency seem to drift a bit. Would it help to increase total steps to something higher or should I make other adjustments?
My images just fade to brown when I use these. What gives?
Are you using SVI? You might be missing the lightning loras
T2V with this workflow, how can you do it? do you just load a black image as input the subgraph? If I disconnect the image pixels input, the workflow refuses to run. Can someone help me how to use this workflow as T2V? Thanks!
yes make a jpeg which is a black rectangle the size you want the video. so maybe you make a black rectangle jpeg which is 640 pixels wide and 400 pixels high.
Biggest frustration I have with local AI is the entire community assumes ever person has been messing with this on an ultra-technical level for years already. The language is borderline incomprehensible and it makes huge assumptions. I don't even know what folder to dump a .gguf file in. I downloaded the workflow - so I need to download everyone on the 'left' side? So I need four different files or not?
Do I need all four "NSFW V2" or just one? Do I also need all four "WAN REMIX v2.1 Q6" or just one? Is it 'use one or the other' so I only need four, or do I need all eight? Or what? Instead of just a basic rundown saying 'this this this' the description is a wall of text longer than the Book of Genesis.
Try searching pixorama on youtube. They released 5 hour video a month ago about comfyui basics. Before watching it I couldn't get a thing. Now it's a bit easier.
Also search for "ComfyUI-Lora-Manager" custom node. And their extension for civitai. It helps download models and loras.
Yeah I agree, this description is a bit much.
I agree with the others.
Remember nobody forces you to make a.i, this is a choice. You wanna make it, you gotta learn it and lots of ppl are willing to put their time to make videos to help you learn. Everyone just wants to make and not have to do the work. I learned by asking GPT everything.
Most workflows are gonna give you frustrations but if you post your error codes or simply ask GPT what this means, you’ll likely get your answers instead of venting that frustration to the community. Pixorama is perfect for learning this.
man how i agree with this. a simple readme file for starters is always appreciated.
Yeah, if you try to process it with GPT then it really doesn't help much; parsing all this data with Claude helps, but it's still basically doing a fuckton of steps that make 0 sense to newcomers. It's like telling a dude during his 1st day on Linux to compile something from source on Arch.
The main issue, however, is:
1. There is no streamlined, well-explained, newbie-friendly guide explaining the nitty-gritty w/o all the extra fat. A handful that exist are mutually exclusive, and focus on a single use case.
2. It's difficult to explain it in a pithy manner because the tech and toolkit around it are pretty damn complicated. There's also ComfyUI which is great for optimizing, customizing and chasing new users away. So all in all: it's complicated because it kinda has to be. And the only way to fix it, would be for an equivalent of A1111 to show up - severely limitting the capabilities, by making everything work straight out of the box:
Install.bat -> dependencies.bat -> config.bat -> (test.bat ->) run.bat
instead of forcing its users to first get a PhD at generating 2.5D porn with a postdoc in applied prompt linguistics.
Could you add sigma value info for your model infos? AFASK baked lightning lora changing the default sigma.
Are the v2 Q8 fp8 base?
Hey, just wanted to say thanks for all the work you put into this model and for keeping it updated.
I’ve noticed it does blowjobs really well. From your experience, what other kinds of scenes does it handle best?
If you have a list of scenes that tend to work well, I’d love to hear about it. And if anyone else has tried it and found scenes that work great, feel free to share.
Thanks again.
Uncontrollable humping is back with this one. If man with meat bat entering the frame no matter what the prompt he will be humping.
What makes it even wilder is that, without the use of a lora, they wont penetrate anything but thrusts into the air if its a man from offscreen. And its a shame too because the size of the penis the model provides is much bigger than the tiny peckers the lora have.
I tried to use the NSFW V2 model, the output motion is nice, but the image itself is grainy/blurry.
Where is the setting for global lightning lora in your workflow? is it in the first subgraph that loads high/low SVI lora and the high/low lightning lora plus vae and text encoder? Anytime I add loras to the three lora loaders above each of the video section subgraphs it turns the video into a gray/gold pixelated mess
So in your info for SVI, with regards to: "Combo 3 – Balanced Motion / Moderate Degradation" Both the high and low are the same link, the only difference is the weight. Is that correct?
Also, I'm wondering, with the models in this workflow, is 32GB VRAM enough for the entire model without offloading anything? Or do you think that would require a commercial-grade GPU?
can i use this model with my ai model? not only random girl?
sorry to bother you. I have a problem. I’m using NSFW V2, which does not come with SVI annotations. According to the instructions, it has Lighting LoRA built‑in. I used the official NSFW workflow.
First, it failed to generate a video. After troubleshooting, I found it was a path issue with the save node; after fixing that, it saved normally. But the real problem appeared: the generated video is severely pixelated and has color distortion, with a brownish tint.
I did not add any LoRA this time. Then I tried adding the SVI LoRA — the problem remained. I tried adding the Lighting LoRA — still the same issue. I tried adding both LoRAs — no change.
I have no idea what’s going on, and I don’t know what to do to make it work properly. I can see the motion is excellent, but the color and graininess are ruining it. Any help would be greatly appreciated.
Exact same issue. Can't make heads or tails of it.
Hello, I am a skilled craftsman. May I ask if I have downloaded it WAN 2.2 Enhanced NSFW | SVI | camera prompt adherence (Lightning Edition) I2V and T2V fp8 GGUF After the model was developed, High LoRa and Low LoRa were downloaded without any changes to the parameters. However, the generated video had a lot of noise, and I don't know why WAN 2.2 Enhanced NSFW | SVI | camera prompt adherence (Lightning Edition) I2V and T2V fp8 GGUF Where should it be, thank you for your answer!
I'm confused, has the FAST MOTION V2 FP8 version SVI or Lightning baked in?
FAST MOTION V2 FP8 has lightning already ; 4 steps, no lightning lora
if it doesn't have SVI in the name, it's not SVI
@MysteriousString420508 All models have SVI in the filename when you click download, that's why I ask. But I guess it's just the general prefix.
Thanks for the detailed guide! I was having a major issue where my VRAM and RAM wouldn't offload after the first 5 seconds, freezing the whole workflow. After setting --cache-none, I can finally generate 5-second videos without the instance crashing, though the workflow still gets stuck and won't move past that point. I’m running this on a runpod instance with an RTX 4090 - any idea how to fix this hang?
make sure that you have swap file on C set to 64gb. yesterday i struggled with the same problem. you can check if I'm right by entering the Windows event log, where you should find a message about Python crashing due to the lack of pagefile.
PathchSageAttentionKJ
No module named 'sageattention'
What is the solution to this problem?
install sage attention
uv pip install git+https://github.com/thu-ml/SageAttention.git --no-build-isolation --no-cache-dir
or you can delete the node and not use sageattention, but you're gonna want it. it's way faster than what ships with pytorch
Hey OP, I've been messing around with your models and WFs for a couple days now but i keep having the same issues where i keep getting either body horror or just fleshy throbbing non-human masses lol, this happens even in the cleanest runs possible. i.e. dragged one of your videos to get the workflow, left ALL settings as they come and only change the models according to my specs, which is just SVI Q6 CF, ive tried many different combinations of lightning loras and i still get this issue 9/10 times, any idea what might be wrong? and yes this is without using any additional loras. default t5 and vae as well.
possibly are you using the same H model for both the high and low model loaders?
@sickdude9630 no thats not the issue, i noticed the triple K method is way more unstable in terms of these bizarre generations, im guessing its a matter of motion being too much or too unstable, so i see why you might think im using the wrong models but sadly no :(, any other ideas?
im very new to ai generation and maybe this is a dumb question, but in your workflow you use wan2.2\Wan2_2-I2v-A14B-HIGH_consistent_face_Q8.gguf and wan2.2\Wan2_2-I2v-A14B-LOW_consistent_face_Q8.gguf I was not able to find these anywhere ? I only got your wan22EnhancedNSFWSVICamera_nolightningSVICfQ8H.gguf
I tried it with that but onyl got a very pink video.
I am happy with any tipps or ressources to help me
i think you downloaded only the "H" (High) model. if you look at the top of this page, there are many tags you can select from, and you see this page is actually only the "H" model of this version, you need to click the "L" (Low) model tag and download the model gguf from that page as well, then you will have the complete H&L model pair for this version. Then in the workflow, put the H model into the high gguf loader and L into low gguf model loader and your output will start looking more reasonable.
i feel so stupid haha, thank you though :)
我也是新手,我遇见了和你一样的问题,也没找到wan2.2\Wan2_2-I2v-A14B-HIGH_consistent_face_Q8.gguf和wan2.2\Wan2_2-I2v-A14B-LOW_consistent_face_Q8.gguf这两个文件。你现在在哪里找到了吗?
Sometimes, when I change something in a later block, all blocks starts re-generating videos without me changing seed/prompt/lora or anything. How can I stop that from happening? It seems to happen more often when I'm coming back to the workflow some hours later.
Could you be hitting Ctrl+Enter maybe? Either way, maybe go into Settings and double-check your keybinds.
Do you have a date stamp anywhere in your workflow? Could be triggering if the date rolls over maybe?
Same problem as karsder309. When I modify the prompt in the last block, it reloads all the blocks from the beginning. It doesn't happen every time, but it does happen from time to time.
what's up with all the winking to the camera? any idea where those weights are from? you just never see that in real videos hardly ever, so I feel like it has to be intentionally included in a dataset somewhere along the line. it freaks me out
Try adding a WanVideoNAG node in between the lora loader and sampler (incl. an isolated negative clip text node connected to the NAG node and 'winking' added to it), might help.
for the dynamic prompt, do you have to keep increasing the "At x second" beyond the 5 sec like "At 6 seconds" and so on? or do you just repeat back down from 0 only go up to 5 in each subgraph again? cus it looks like each subgraph is separate 5 sec generation and stitching afterwards so maybe dont need to keep increasing seconds beyond 5 ? or does the svi lora need correct seconds even beyond 5 for it to work correctly? thanks!
There a walkthrough for how to do text to video with this somewhere? i'm new to text to video and tried it out but cant seem to get it to work. it gets stuck mid run
Recommended LoRA to obtain a very realistic ****** and ****:
https://civitai.com/models/2217653?modelVersionId=2496754
Where can I download it? Thanks
search for it on civitaiarchive.com
No quant'd SVI fm? I tried the quant'd cf (and I could run SVI fp8 fm, but it's just overkill in my case) - I did find both versions way too stiff for my use-case. Considering Slop Twerk WAN 2.2 is part of the training data, I had hoped for more bounce effect without having to load the actual Slop Twerk WAN 2.2 on top. I'm using my own SVI Pro V2 workflow with ComfyUI-TripleKSampler. I mostly need fast motion but with bounce effect which one can get plenty of simply using the Slop Twerk WAN lora and a quant'd Wan2.2-I2V model. But I wanted to give Wan 2.2 Enhanced a try, for reduced degradation in longer 15+ sec videos. I tried Smooth Mix Wan 2.2 14B (I2V), but it's a bad match with the SVI loras. A great alternative is DaSiWa-WAN 2.2 I2V 14B SynthSeduction v9 | Lightspeed | GGUF ...goes great with the SVI loras, but this is also lacking in bounce effect (I at least have to add the Slop Twerk WAN lora at full strength, but this degrades the DaSiWa-WAN model too much, I feel).
For context: I'm trying to recreate a bounce effect on two characters facing eachother while standing (like a fighting stance similar to old-school 2D Neo-Geo fighters). Originally, I achieved this to my utmost satisfaction using two ClownsharKsamplers (RESLYF) + Euler/beta57, with the Slop Twerk Wan lora and a quant'd Wan2.2-I2V model. Sadly, the Clown samplers fail to work with my SVI Pro V2 workflow when set up in batches (batch 1 finishes without issues, but triggers a crash when the latent samples are handed over to batch 2). I assume the Clown samplers are simply not compatible with WanImageToVideoSVIPro (kj-nodes). It's unfortunate, as the Clown samplers offer a superior quality output when compared to anything I've so far seen with Ksamplers.
Very nice. However, the Lora link for the realistic vagina and anus is currently showing a 404 error. Could you please correct the link?
Hey guys, after months of experimenting with outputs in wan 2.2 I've recently stumbled on something that in hindsight I probably should have played with before. Try messing around with different combinations of the various lightning lora's; the same way you would with other loras. I think you all will be surprised at the vast difference between outputs and varying prompt adherence. Dunno if this is just common knowledge, but I'm sure theres a few others out there who don't know this.
Once again to Taek, I really appreciate you releasing the version without lightning baked in. I like your checkpoints but the baked lightning can be a little tricky to work with imo. Great for speed, but you know what I mean. I'll stop waffling now.
EDIT: Oh, and since I know people will ask. Try lightx2v_I2V_14B_480p_cfg_step_distill_rank256_bf16 and/orlightx2v_I2V_14B_480p_cfg_step_distill_rank128_bf16. I've been enjoying the outputs I get with these lately. Good prompt adherence and seems to be very friendly with other loras. You can double up the same one in both slots or mix em for if you fill like it. I've notices with the 1022/1030 lightnings that with things like blowjob, for example, the penis will get more wet with the lora's mentioned. And there seems to be more natural human motion. Oh, and these work A LOT better with cum loras. Good luck, have fun
should I play with the lora strength too? how much do you usually set it at?
@2kodaffa7235 I usually have it set to 1. But you can mess with it if you like. It depends a lot on the checkpoints you're running. And steps.
I've got rank256_bf16 in high and, as weird as it sounds, the high slot 1030 lightning in the low slot. Running nolightning SVI high checkpoint and easywan low checkpoint. The benefit of running nolightning svi in high is you can pull some loras out of the high slot and get quicker outputs. low slot will need loras if you are running one with minimal loras merged in, as I prefer. I like dreamerlay nsfw lora set to 1 in low. But if you have a penis already in frame, might wanna lower it to 0.6 to prevent to lora from altering it's appearance too much.
I'm really getting out there with some weird mix and match workflows. I would link them but I'm of the opinion people need to experiment on their own. It's more fun and you learn some things. I'm just modifying existing SVI workflows myself.
Ah yeah, I think easywan may have lightning baked in. So going to try running without lightning in low later.
Does it really work? Those lightx loras seem to be for wan2.1
I think I've locked down what's creating the difference in results. I believe since easywan has baked in lightning I'm getting a greater strength from the lightning I'm running with it. which is why having it in low slot is getting such crazy results. Again, probably just obvious to big smarty pants. I've noticed it can cause some screw ups with anatomy and AI hallucinations, after adjusting the lightning in low slot down to .4 I'm still getting the improved prompt adherence and motion; but none of the hallucination. So yeah, use whatever checkpoints you want and just mess around with your lightnings loras and their weights for interesting results. Remember to run the same seed if you want to see the differences properly.
Could anyone point to a guide on how to install comfy for this insane workflow? :D
I have tried but get tooons of node errors that cant be installled.
Almost everyone creator ignore this issue.
When you got message of errors try this - open manager and click on missing node (if you see it) then on right side find link to website where it originaly belong then just download it, unpack and add it manualy to your comfyui custom nodes
@yeti842 Thanks for your reply. I actually know all this, but when I do that on this - and many other - workflows i get conflicts galore... great with a wf that can do miracles, if you just know how to use it... but I understand that I am too noobish for this.
You can just use comfyui easy install, then load the workflow and use comfyui manager to install all nodes, takes 10 minutes. GitHub - Tavris1/ComfyUI-Easy-Install: Portable ComfyUI for Windows, macOS and Linux 🔹 Nvidia GPUs 🔹 Pixaroma Community Edition 🔹 · GitHub
You even have bat files for sageattention, flash attention etc.
@Smurfypie ok.. thanks.. will try... again ;)
why white liquid everywhere? it's so hard to make normal cum, saliva and lactating..
q8 is better than FP8, right?
Depends on your hardware. 40xx and up gets more out of fp8 than 30xx for example. With 50xx fp8 tend to be both faster and more accurate.
could any one teach me how to stop the charater speaking or opening their mouth/eyes wide during the video
Add "talking, open eyes" to negative prompt. Add "eyes closed" to positive prompt.
Hey im new in this world, i have a quick question :)
This is a "merge" so how to assimilate it into my wan workflow ?
Just starting with wan so, on a 4080 16GB VRAM, which ones are the right ones, fp8, q8 or even lower? Maybe anyone can help me out (of experience) before I dl >25GB multiple times? Thanks in advance!
I'm able to run the NSFW v2 Q6 pretty fine on just 8GB vRAM, maybe like 18 minutes. The Fast move v2 Q4 works but is rather long and I prefer the other model.
I'm not seeing the no lightning fast move Q8 version?
Your models are great, giving some of the best results I've personally had with wan models. But man, this page is a mess. Maybe consider splitting it up so there's a dedicated page for the SVI stuff. Also, it's kind of unclear whether "no lightning" means "don't use lightning with this because it's built in" or "use lightning because it's not built in".
not sure if this has been discovered yet, but I may be close to cracking the code on fixing slow motion on the SVI model.
It seems all you have to do is somehow weave the token "rubbing" to your prompt, optionally with speed related tokens (quickly, rapidly, etc). This model seems to really understand that token, which kinda makes sense because you could argue that "rubbing" is the most ubiquitous way to visually describe the motion of most, if not all sex acts.
I tested it on a few BJ generations, prompting something like "she is quickly rubbing his penis back and forth with her mouth" along with a general description of the scene was all it needed to get rid of the slow motion effect. Still need to test more on other acts, but "rubbing the penis back and forth with her vagina" seems to work for penetration so far.
Ive only tested it a little bit without loras. This may be useful for those trying to avoid loras for extended videos, as some loras can be used to improve motion, but at the cost of increased degradation over each generation.
Is there a full BF16 version?
are you able to lower the strength of the build in lightning loras?
I'm really struggling with camera movements. Most of the time nothing happens at all with them. With or without loras. Zoom in and out are about the only movement I've been able to get and that is spotty at best. Any tips?
using FAST MOVE V2 FP8, wondering how i can get a character to stand still especially the man, when prompting a handjob, thank you
Same.
Hey guys, bit of a beginner here and kind of confused with the GGUF files for high and low. I can't load them in the workflow with the "Diffusion Model Loader KJ" nodes as it only allows safetensors. I heard I need to add GGUF nodes, but what would I connect them to in order to keep the workflow operational?
just replace "Diffusion Model Loader KJ" with "Unet Loader GGUF"
@jimzlf Just tried it. It definitely changed things, but now it turns the characters in the image into unrecognizable porn stars and generates disproportionate, borderline horrific movement. Anything I may have done wrong?
@tisecah474742 i'm not sure, you may have to check your settings, such as loras, prompt, sampler, parameters and so on. if you haven't changed anything except the model loader, check especially lightening lora maybe
Can anyone send me the link for GGUF model for nsfw high and low? after loading the workflow i need those models but here is no link and i can't find them anywhere
You have to keep clicking the directional right arrow until you see the GGUF files
Hi, I seem to be having the same issue, It says "wan22EnchancedNSFWCameraPrompt_nsfwFASTMOVEV2Q8L.gguf"
But I cannot find any the have the same file name (is it the SVINSFW one, all the ones I tried to download have SVI in the filename) - sorry if being dumb, I got the safetensors ok though the V2FP8H .
@Dracken1986 it's literally on this page, this one: https://civitai.com/api/download/models/2540896?type=Model&format=GGUF&size=full&fp=fp8
@shapeshifter83 Thank you very much will download that and the H now :).
My issue is I am too literally >_<, on the workflow the GGUF said:
"wan22EnhancedNSFWCameraPrompt_nsfwFASTMOVEV2Q8L.gguf"
and
"Wan22EnhancedNSFWCameraPrompt_nsfwFASTMOVEV2Q8H.gguf"
the one in the link you posted has the added text SVI
"wan22EnhancedNSFWSVICameraPrompt_nsfwFASTMOVEV2Q8L.gguf"
I wasn't sure if there was a difference, guessing not. Thank you again for your help.
Hi guys, someone share me about this lora below?
I google it but nothing.
wan_2_2_i2v_a14b_high_test-derniere-version-selforcing
wan2.2_i2v_a14b_low_selforcing_last-version_rank64_lightx2v_4stop_1022
wan2_2-i2v-a14b-high_svi_consistent_face_nsfw_fp8
wan2_2-i2v-a14b-low_svi_consistent_face_nsfw_fp8
i'd also like to know.
why include multiple models without links and can't be found online?
Where has the whole community gone? There used to be a lot of interesting content on Wan 2.2. Now it seems like everything has stopped. Has Wan 2.2 reached its technological limit? Or am I missing something?
everyone following carrot on a stick, probably chasing LTX2.3 or other models now. I do not really like it, since the LORAs are following this trend as well.
What makes me wonder, WAN2.2 is pretty capable, it is not comparable to SD1.5 => SDXL or HUN => WAN.
LTX is interesting, no doubt, but does not serve consumer cards well. Shame the compute power wasted on creating LORAs for every new architecture from scratch.
I tested this model on my computer with a GeForce RTX 3060 graphics card, 12 GB of video memory, and 128 GB of RAM. I was amazed by how efficiently comfy UI uses resources. I downloaded the 45 GB LTX2.3 model. I decided to run the render in 1280P resolution. What do you think happened? Everything worked without any errors. Yes, it was slow, but the fact is that the size of the video memory doesn't seem to matter as much. The amount of RAM is crucial.
@dirtysem can ltx 2.3 do complex nsfw scenes well? Is it limited to 5 seconds but can we extend like in wan 2.2?
@androsny LTX 2.3 is in its early stages, like wan 2.2 in its time. It doesn't handle NSFW well yet. However, I believe this model has great potential. It's developing slowly because it requires significant computer resources. And the declared length of the video is 20 seconds. I checked it like this.
To me, Wan is good enough to not chase the new, shiny thing. As a community we'd be better off just trying to push Wan to it's ceiling.
@dirtysem no kidding? Can you share the workflow you using? Any special attention mode? Sage, Flash, PyTorch?
@dnu75950132 Really, no kidding. Any workflow provided here works. I'm constantly having installation issues with Sage, so I'm using the standard comfyui with nodes that are included in the workflows.
Hi, Excellent workflow and model – you are the first person I managed to create an animation without errors or failures. I still have room to improve on my side. Thanks again, you are the best
Hello, which workflow are you using?
That's the only model that really works perfectly, ty a lot man!!!! but, u have a fp8, fp16 or bf16 version? Just curious
where to find wan2_2-I2V-A14B-LOW_consistent_face_Q8.gguf?
What LoRAs are baked into this merge?
Hey, how many steps do you recommend for nolightning SVI cf fp8? You list a number of recommendations for different lightning lora combinations and steps and mention the possibility of generating with no speed-up loras, but I can't find a mention of the recommended settings when doing that.
Default is 10 and 10
Hi @logoth would you mind sharing the values to change in the 2or3 ksampler SVI workflow to run without the speed loras? I tried multiple combinations but no success, getting blurry results. Thanks again for the great workflow, works great with the lightx2v loras enabled
@HerMcGraugh sorry, this isn't my workflow.
the values that need changing without lightning loras are steps (max steps to 20 and stop/start at 10ish) and CFG to 3.5
im not sure with 3ksamplers, it depends if any are turbo.
i would just like to know where can i add my custom loras? and i honestly dont understand that 2+2 step, like where do i do that 2+2 and what does 2+2 even mean?
In general, Wan 2.2 has two models, high noise first, then low noise. Those go in ksampler with typically 2 steps each, 4total.
Loras go between model load and ksamplers, both respectively high and low noise. If you want a very easy image to video workflow, you may check my profile. Those here are more advanced.
conect ur loras just after the model loader, an the 2+2 means that u need put 2 advanced ksampler working together, the first ksampler put in total steps 4, start on step 0 and end on step 2, and the second ksampler start on step 2 and end on step 4 this is to improve the quality of the fast video
@logoth @Belfang thanks a lot for your reply, i kind of understand it now, but the issue im getting in the workflow is that the result is CRAZY!! lets say the girl is lying on her back rubbing her fingers on her private part and im prompting that she just rubs it and for some reason blood comes out of her private part and her legs are shaking insanely in the air, it is so weird!!
@marcelinorafik01419 lol, never had that kind of issue... as for movements, it requires some treis to figure out what the wan model will do in what situation, some words won' work, some will work only in certain conditions.
@logoth Im not going to lie, i might have found the issue, im exploring other workflows and i just learned that i should use both the low and high version of the loras i want to use, and i think i have been using the high only, could that be the issue?
@marcelinorafik01419 depends on the lora. high noise will help with desired action more, low noise with detailed look. as long as you don't put them in the wrong place you often don't need to use both.
Can i try RTX 3060 12GB
Yes i'm running this on a 8GB RTX and it works but you need more System RAM and fast NVME SSD to make up for lack of GPU vram which is why System Ram and NVME is so expensive
Has anyone tried it with a 5070? Which quantization model do you recommend?
if 12gb Q4-Q5. Your model should be GPUgb -1-2gb size
I have an RTX 5070 12gb - 32 DDR5 and everything works even at 1024x768. Length 81/121... Q8.gguf
@gambikules858 Q8 work on 4060 even
I recommend using the Q8. I used the Q6 and Q8 even recently when I had a 3060 Ti with 32GB of RAM. With the 5070, it is more than enough.
@mangho9123389 I have a 32 GB Ram and 5070 TI 16 VRAM card, which would would be okay?
It also depends on the length of your video and the render size
You might be able to render HD but probably not over 5 seconds ;)
i keep getting a grey blurry picture on my generatations. With the workflow either triple ou 2ksampler doesn't change a thing. I have a 4070ti 12G vram and 32g ram. Is it because of my hardware or I missed something in the settings probably ?
Same
Also same on a 4090
wan2_2-I2V-A14B-LOW_consistent_face_Q8.gguf - this, and high one - cant find this files everywhere, no "consistnt_face" :(
It's the SVI "CF" Low version on the top of this page.
Is it possible to get a bf16 version?
Have u ever tried using MMAUDIO for your checkpoint?
To be honest, I didn't use this checkpoint. I used a pure FP8 wan checkount with enchantment movement Lora
https://civitai.com/images/126962109
If you're looking for sounds for NSFW videos, you should check out the models MMAudio on HiggingFace
decent checkpoint. but... a lil washed out. looks dang blurry and adds a greenish tint compared to the regular model. also... there is no way to slow down the motion. in my test shot... at 24 fps it goes full fucks mode. what if i wanted to be a lil more gentle? like 16 fps without the visual stuttering.
The motions are pretty much always fucking lol no matter what you prompt haha
I think you use something like ComfyUI right?
If you add color correction to your workflow it'll improve a lot depending on how well-lit the starting image is.
In my test I noticed my previews being horrible, but I only use low pixels to test my prompt and motions.
What will help a lot in the quality is increasing the steps (total steps 8, refiner steps 4) and at least have a high enough resolution like HD or a little above (5-8 seconds depending on your VRAM).
Hope it helps, I had a very similar issue you had.
Hey guys. I can't reduce the size of penis during generation, I want to make a realistic video. I am using wan22EnhancedNSFWCameraPrompt_nsfwFASTMOVEFP8Low.safetensors and the High version. I don't use loras as they often break the quality. Can you recommend something? Maybe there are some trigger words in prompt, or good loras?
I've been using "thin, erect circumcised penis."
Hi there! I’m using the NSFW FAST MOVE V2 Q8 (Lightning baked) model and I’m having some trouble getting LoRAs to 'stick' properly.
My current setup:
Genitals Helper LoRA: 0.6 str (Applied to Low Noise)
Fingering LoRA: 0.6 str (Applied to Low Noise)
Oral/POV Insertion LoRA: 0.8 str (Applied to both High & Low Noise)
Even with these settings, it feels like the model is mostly ignoring the LoRAs or the effects are barely visible. Since this is a Lightning baked model, should I be using higher strengths than the usual 0.6 recommendation?
Regarding steps: I’ve tested the recommended 2+3 step configuration, and I’ve also pushed it up to 8+12 steps to see if it helps with detail retention during SVI chaining. In your experience, is there any actual benefit to increasing step counts this high (or higher) on a distilled Lightning model? Does it actually improve LoRA compliance and texture quality, or am I just hitting diminishing returns due to the model's architecture? Thanks for the help!
The NSFW tend to be a bully to have the best results most of the time I'm using the Non NSFW to combine it with lora and the NSFW alone as it's pretty good to make NSFW thing by itself.
Some Lora however work also with the NSFW, depend if they are "pulling in the same direction" we can say so you need to make some test, maybe increasing the lora weigth to make it work checking case by case.
@ai_phanotm_red1893 thank you. I'll give it a try.
sorry, i must be dumb, but i can't find which model is a text to video one ?
it says t2v on the text to video models
yo guys, cant i mix fast movement with cam, or consistent face with cam?
is there no mmaudio included for this?
which folder do i download the models to? checkpoints didn't work. neither did unets. getting frustrated
Far as i know: Diffusion_Models
.gguf goes under unet dir. .safetensors should go under diffusion_models normally.
If you use .gguf versions you will need to use a gguf loader node, and maybe other workflow changes.
Seems like I am too noob... all the workflows I try to use are NOT for Q versions. Is there a way to use the model in the standard wan workflow from comfy? This is all way too complicated for me :D
Hey bro just wanted to say I've been using your stuff for a while and I love your work Just got into some LTX2.3 and was wondering if you ever plan on training anything for LTX?
hey guys i keep on getting this video generation issue when i run a consisted face svi high and a fast movement svi low models together. the result is very pixelated, is this an issue with the steps? or lighting loras or what exactly? How do i fix this please and thank you?
might be an idiot, but using Fast Move Q8 all my videos come out really blurry and artifacting. Like the movement and prompt adherence is there but it feels like I'm missing something. Do i need to add additional loras?
OP, could you recommend one? or add like a "deprecated" tag if any are deprecated or a version-num? there are like 30 workflows and I'd love to learn, but its kinda overwhelming. it would help me a lot <3
Details
Files
wan22EnhancedNSFWSVICamera_nolightningSVICfQ8L.gguf
Mirrors
wan22EnhancedNSFWSVICamera_nolightningSVICfQ8L.gguf
wan22EnhancedNSFWSVICamera_nolightningSVICfQ8L.gguf
wan22EnhancedNSFWSVICamera_nolightningSVICfQ8L.gguf
wan22EnhancedNSFWSVICamera_nolightningSVICfQ8L.gguf
wan22EnhancedNSFWSVICamera_nolightningSVICfQ8L.gguf
wan22EnhancedNSFWSVICamera_nolightningSVICfQ8L.gguf
wan22EnhancedNSFWSVICamera_nolightningSVICfQ8L.gguf
wan22EnhancedNSFWSVICamera_nolightningSVICfQ8L.gguf