
Wanvideo 2.2 SVI Pro 2.0

I uploaded a version of ComfyUI without models (6.51G), it has all the nodes and workflows to run and avoid errors, if you have your own ComfyUI, you can ignore this part
https://drive.google.com/file/d/1Q7s78RTEspmvWUsJkQ1IA86m_ozg8uSb/view?usp=sharing
1.Model
ComfyUI\models\diffusion_models
Wan 2.2 fp8 (Original)
wan2.2_i2v_high_noise_14B_fp8_scaled.safetensors
wan2.2_i2v_low_noise_14B_fp8_scaled.safetensors
ComfyUI\models\vae
ComfyUI\models\text_encoders
ComfyUI\models\Loras
Lightx2v High LoRA
Lightx2v Low LoRA
The sampler's subgraph has an additional LORA reader, making it easy to use different LORAs in different samplers.


★ How to improve slow motion

Using Wan2.2 Distill Models with Lightx2v Lora, intensity set to 0.5
Wan2.2-Distill-Models
wan2.2_i2v_A14b_high_noise_scaled_fp8_e4m3_lightx2v_4step_comfyui.safetensors
wan2.2_i2v_A14b_low_noise_scaled_fp8_e4m3_lightx2v_4step_comfyui.safetensors
Wan2.2-Distill-Models GGUF
Wanvideo 2.2 Animate
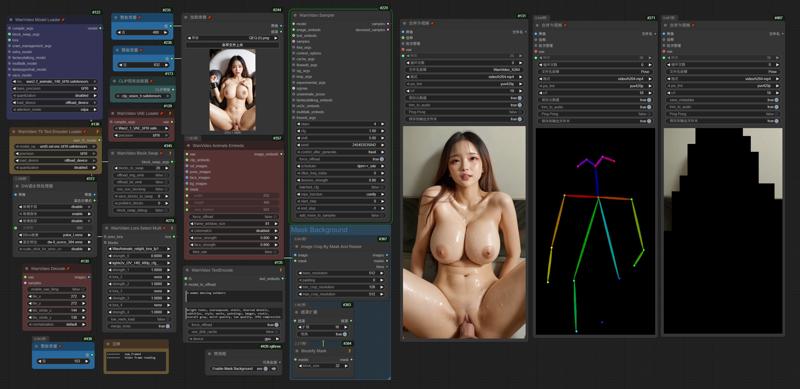 I uploaded a version of ComfyUI without models (4.38G), it has all the nodes and workflows to run and avoid errors, if you have your own ComfyUI, you can ignore this part
I uploaded a version of ComfyUI without models (4.38G), it has all the nodes and workflows to run and avoid errors, if you have your own ComfyUI, you can ignore this part
https://drive.google.com/file/d/1lcK9QX6FmLO6rQNP6200rbLiqnHpt0uK/view?usp=drive_link
1.Model
ComfyUI\models\diffusion_models
ComfyUI\models\vae
ComfyUI\models\text_encoders
umt5-xxl-enc-fp8_e4m3fn.safetensors
ComfyUI\models\clip_vision
ComfyUI\models\Loras
lightx2v_I2V_14B_480p_cfg_step_distill_rank256_bf16.safetensors
ComfyUI\models\detection
ComfyUI\models\sams\
---
ComfyUI\models\custom_nodes
auto_wan2.2animate_freamtowindow_server
Download the ZIP file and extract to custom_nodes.
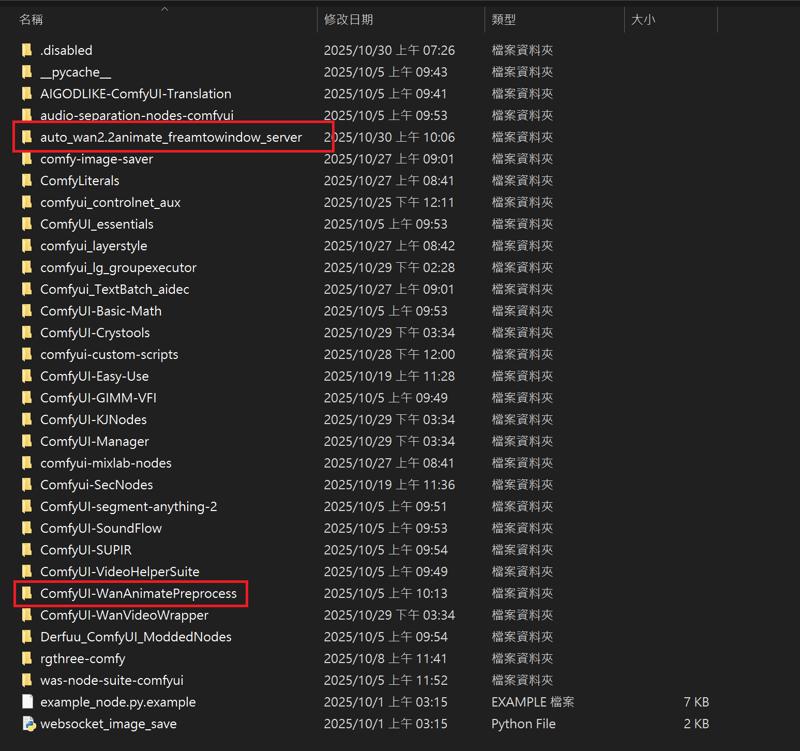
---
Wan2.2 Kijai I2V

I uploaded a version of ComfyUI without models (6.51G), it has all the nodes and workflows to run and avoid errors, if you have your own ComfyUI, you can ignore this part
https://drive.google.com/file/d/1Q7s78RTEspmvWUsJkQ1IA86m_ozg8uSb/view?usp=sharing
1.Model
ComfyUI\models\diffusion_models
Kijai bf16
Wan2_2-I2V-A14B-HIGH_bf16.safetensors
Wan2_2-I2V-A14B-LOW_bf16.safetensors
Kijai fp8
lightx2v Distill
lightx2v/Wan2.2-Distill-Models
(After testing, it can greatly improve video dynamics)
---
ComfyUI\models\vae
ComfyUI\models\text_encoders
umt5-xxl-enc-fp8_e4m3fn.safetensors
ComfyUI\models\clip_vision
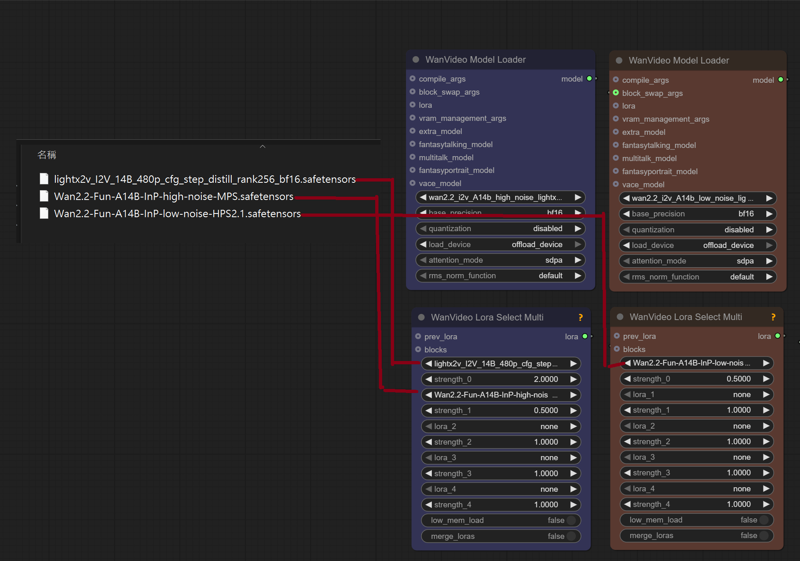
ComfyUI\models\Loras
lightx2v_I2V_14B_480p_cfg_step_distill_rank256_bf16.safetensors
Wan2.2-Fun-A14B-InP-high-noise-MPS.safetensors
Wan2.2-Fun-A14B-InP-low-noise-HPS2.1.safetensors
---
InfiniteTalk + UniAnimate
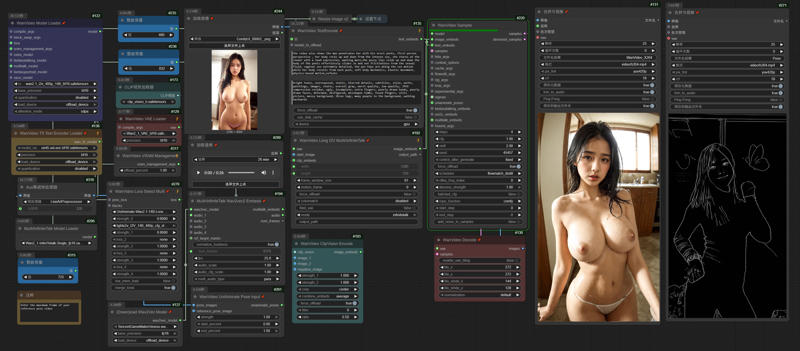 I uploaded a version of ComfyUI without models (4.38G), it has all the nodes and workflows to run and avoid errors, if you have your own ComfyUI, you can ignore this part
I uploaded a version of ComfyUI without models (4.38G), it has all the nodes and workflows to run and avoid errors, if you have your own ComfyUI, you can ignore this part
https://drive.google.com/file/d/1lcK9QX6FmLO6rQNP6200rbLiqnHpt0uK/view?usp=drive_link
1.Model
ComfyUI\models\diffusion_models
Wan2_1-InfiniTetalk-Single_fp16
ComfyUI\models\unet
ComfyUI\models\vae
ComfyUI\models\text_encoders
umt5-xxl-enc-fp8_e4m3fn.safetensors
ComfyUI\models\clip_vision
ComfyUI\models\Loras
UniAnimate-Wan2.1-14B-Lora-12000-fp16
lightx2v_I2V_14B_480p_cfg_step_distill_rank256_bf16.safetensors
---
InstantID
InstantID does not support the latest version of ComfyUI. Please download the old version. I deleted the model and kept the nodes to ensure that there will be no errors when running (5.62g)
https://drive.google.com/file/d/1_HPGG2iMAyovS3jO8ubhti4YIcOhOLUj/view?usp=drive_link
1.Model
ComfyUI\models\checkpoints
leosamsHelloworldXL_helloworldXL50GPT4V
ComfyUI\models\loras
pov-squatting-cowgirl-lora-1-mb
ComfyUI\models\unet
ComfyUI\models\clip\
CLIP-ViT-bigG-14-laion2B-39B-b160k
Rename 「open_clip_model.safetensors」 to 「CLIP-ViT-bigG-14-laion2B-39B-b160k」
Rename 「model.safetensors」 to 「clip-vit-large-patch14」
ComfyUI\models\vae
vae-ft-mse-840000-ema-pruned.ckpt
ComfyUI\models\controlnet
ttplanetSDXLControlnet_v20Fp16.safetensors
ComfyUI\models\instantid
Description
October 25, 2025
Fix「WanVideoAnimateEmbeds」
「AdaptiveWanVideoAnimateEmbeds」 cannot support the latest 「WanVideoSampler」 and has been replaced
October 15, 2025
Added SeC-4B「SeC-4B-fp16.safetensors」
https://huggingface.co/VeryAladeen/Sec-4B
Added SeC-4B BBox Input
October 12, 2025
Added「SeC-4B」
SeC: Advancing Complex Video Object Segmentation via Progressive Concept Construction
https://github.com/9nate-drake/Comfyui-SecNodes
October 8, 2025
Replace Model 「Kijai-Wan2.2 Animate 14B_fp8_scaled_e5m2_KJ_v2.safetensors」
September 30, 2025
Added PoseAndFaceDetection
September 28, 2025
Added WanVideoContextOptions
September 26, 2025
Added WanVideoUniAnimateDWPoseDetector
September 25, 2025
Added AdaptiveWanVideoAnimateEmbeds
Added No Poseimage input
Added Load Image Batch
Replace LoRA
Replace VAE
September 21, 2025
Added No mask or background image input
FAQ
Comments (52)
Your audio is longer than your reference frame video.
How can I get the WanVideoAnimateEmbeds node? I saw it in someone’s workflow but can’t find it anywhere. Is it part of a specific extension or custom node pack
Update ComfyUI-WanVideoWrapper
@gsk80276 What version of ComfyUI do you have? I've already tried that. I even deleted the folder from "custom_nodes" and reinstalled it, but I still have the same issue
@gsk80276 nevermind, I fixed it.
I switched it to the nightly version. But I had to update it from the stable version.
@lev_ Great! It works.
I have the same problem - wanvideoanimateembeds node missing and even with update to wrapper this node doesn't appear - any tips? I tried switching to nightly update, tried reinstalling but this node always missing? Any help much appreciated
я новичек и не понимаю как заменить персонажа, оставив исходный окружение видео, получается только анимировать картинку = (, как нужно расставить зоны внимания зеленое-красное чтобы дабиться этого?
The black area is responsible for the replacement part. If you pass the bg_imags and mark nodes into WanVideoAnimateEmbeds, it will replace the place where the mask is written.
Use GrowMask and BlockifyMask to control the range of the black area
@gsk80276 Hello. What if I only want to replace the face in the input video? Thanks in advance.
@codeaim Use the GrowMask node to adjust the range of the black area so that it covers the head
@gsk80276 I used the GrowMask node, which creates a similar area covering the entire body in the input video. I also noticed the Point Editor node—should I make any modifications to this one?
@codeaim If the marking is wrong during the first run, you need to mark the characters and background manually, Shift+left mouse button = green = character, Shift+right mouse button = red = background
@gsk80276 Thanks for your kind replying. I now understand how this point editor works.
good workflow, good output. thx for posting.
how to keep background from photo instead of video
September 21, 2025
Added No mask or background image input
@gsk80276 great, ty man
How to do, background from photo instead of video? And is there hope get this working with 1280x720 resulution (81frames) with rtx4090, WanVideoDecode crashes always for me. 832x480 works.
@gsk80276 thank you
Wan 2.2 Animate to Animation works great! Except for face adherence. The generated face looks nothing like the reference image. Suggestions to resolve?
Figured it out. DWPose Estimator with still using detect_face even when disabled. Physically disconnecting the face_images in the WanVideo Animate Embeds resolved.
@jamespolk96648 September 21, 2025
Added No mask or background image input
@jamespolk96648 Node inputs can now be properly turned off by switches
if i disable face from dwpose esti and remove the face_images from wanvideo animate am getting black pixels behind the person in the final video. any solutions ?
I'm trying the Wan 2.2 Animate workflow, but the face is too different than what was used. Am I doing something wrong? The similarity between the faces are very little
If replacing, reduce the strength of the face node input
This is a great workflow, the first Wan Animate workflow, that creates decent to good results for me. I have one question: it saves all the created image video image files as well. I haven't figured out yet where I can disable it. Can you pinpoint me to the right node? Thanks!
「WanVideoDecode」is responsible for transmitting the generated image. You can find two nodes for merging videos in this node, one for storing X264 and one for storing PNG image sequences.
@gsk80276 Thanks!
I keep getting: Exception: Error while deserializing header: HeaderTooLarge
@gsk80276 Thank you for linking, it's still not too helpful on there what to do, though. I'm inserting the exact same models that everyone else has done, but it's not working for me which is weird.
What's the best way to do longer videos like 2-3 minutes?
infinitetalk
This is great, but how do I set the frame rate of the output? I can't seem to change it from 30fps.
I unified the fps setting with the reference image video node. The VHS_LoadVideo on the left can set the FPS
too bad the animation for dancing still has the same age old problems. It has a really hard time capturing if the input video is turning around. I get all kinds of broken necks. Also the faces are all mushy - but that might be my 16gbVRAM limitation.
Sorry all the workflows are too complicated and nothing works wasted your time
great workflow, very nice work
Thank you
I'm getting this error in WanVideoSampler:
Error during sampling: index 32 is out of bounds for dimension 0 with size 32
!!! Exception during processing !!! index 32 is out of bounds for dimension 0 with size 32
I uploaded a version of ComfyUI without models, it has all the nodes and workflows to run and avoid errors
@gsk80276 tried the new workflow. Now I'm getting the following error:
WanVideoModelLoader
'blocks.0.fuser_block.linear1_kv.weight'
Also both WAN22_MoCap_fullbodyCOPY_ED and lightx2v_elite_it2v_animate_face are printing "lora key not loaded" errors in the console
I downloaded the version without the model for testing and encountered no errors
https://drive.google.com/file/d/1GUO5Cb9aWEYzTsBUqUcKQlrBrM9t0bkt/view?usp=drive_link
@gsk80276 this is working, not getting the desired results, but working! Let me play with it a bit. Thank you for your amazing work!
As someone who is new to ComfyUI and video generation, are there any recommended resources for optimizing it, operating it, and understanding it? I want to use this workflow, but I'm struggling to optimize it best to work locally on my 3090, and also produce the desired results.
Why don't you just make use of chatgpt? you can export your workflows state and upload it to chatgpt, instruct it precisely and explain what you want to do, and then work together with chatgpt to solve your problems and questions. That's how I did it, after 2 days I built my first own T2I workflow, then came wan 2.1, then i wanted to faceswap and so I looked into reactor, got familiar with segm and shit, and now im making all my shit locally and dont need no runpod or tutor or nothing. It's very simple if you think about it. So get started!
Old version worked well, but with the new version, if I ask to use mask background, it isn't placing the person from the reference photo into the video. It places a random Asian girl instead?
Cuz random Asian girl bang bang white boi longer time