WARNING: Hey, I've lately moved towards LTX2.3 but I will publish a fix to workflow issues mentioned in comments once I have enough free time.
I've officially switched to LTX due to slowmo issues with lightx2v loras. I might share a workflow but that model is already capable of 30s on 720p on a 4070ti so I'm not so motivated to do so. This one would still work if you found the missing packages. Thanks everyone for their support.
It finally happened!
Now there's a way for smoother continuous videos thanks to SVI team and Kijai.
We are at v1.0!
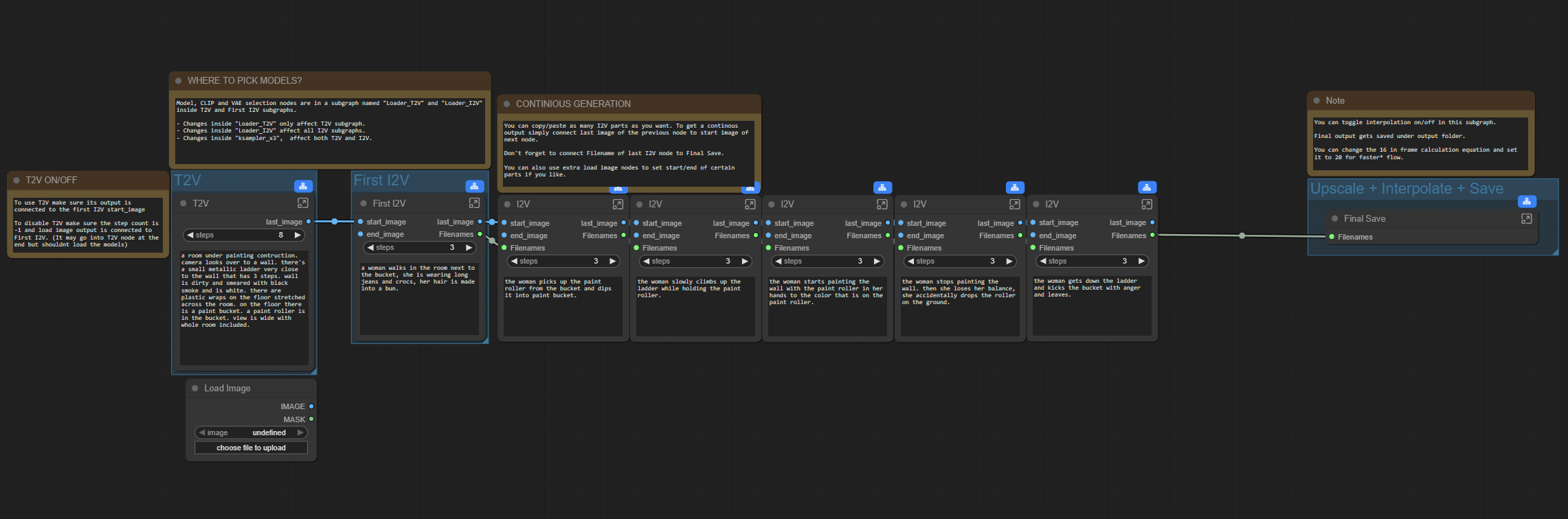
I've updated the workflow to add a few more features;
Video extend option by loading an initial video then converting it to latent that goes into first I2V(WIP)Option to switch between 3 and 2 ksampler phases by setting the initial step
Option to set cfg > 1 if you wanted to disable lightx2v
Images are saved partially in loseless format (use something like VLC to view them) and only loaded again on final merge, if something goes wrong you can merge those files to get a flowing video.
Implemented a bus system to reduce connections. Report if you have any issues but things should work as long as you have the right models and loras selected.
You can set and fix the seed for each part
There are options to upscale and interpolate before final save
Final save happens on main graph so you can preview your output
Slow motion issue probably persists. Couldnt find a consistent solution since when speed up using a third party tool every part becomes faster since they take previous latents as input until everything breaks.
Weak points of most SVI workflows right now is that it references first image in all parts so you might have background warping/chaning shape/textures on switches if the background has changed a lot.
I'll only be updating the workflow if kijai updates the node (there are two merge requests about end frame and better consistency(?)) and/or something breaks. So we can call this a semi final :)
Comfyui compatible SVI lora's;
LightX2V lora's I'm using;
FP32 vae:
Ultra Flux VAE for sharper !"Z Image"! outputs:
https://huggingface.co/Owen777/UltraFlux-v1/blob/main/vae/diffusion_pytorch_model.safetensors
GGUF still seems to be performing better than fp8 scaled in my experience.
Just share your outputs with us folks as well :)
v0.9
Left sampling on (1 + 3 + 3) steps with 4 parts (19s~). Takes around 10mins on my 4070ti with sage + torch compile. Feel free to extend it further if you need.
Everything is GGUF. Patch sage attention and torch compile are disabled by default but you are welcome to enable them back since they speed things up a lot if you have the environment set up.
You can set part specific or common lora's thanks to rgthree power lora node.
Happy generations! \('-')
Description
v0.3
Edit: had to do a few hotfixes. Write a comment if you think something is broken.
Make sure you are running comfyui frontend 1.26.2, I've been told that the linked subgraphs are in the features of the subgraphs and will eventually be working flawless again. Until then run this command to make sure you are on the right version;
.\python_embeded\python.exe -m pip install comfyui_frontend_package==1.26.2Changes;
optimized save function to save parts but only merge them at the end, takes less than %20 of space that was used in previous version
added very subtle temporal motion blur to last frame, transitions look smoother when not much is going on but sharp turns can still happen so it works sometimes and other times you can see the motion change direction. Values could be tweaked further later on
added basic lora example in each part that only affects them
added basic upscale using model support to final save node
removed mp4 converter since most of editing software will support the type, you can use vlc to view part files
changed default resolution to be 480x832 vertical
removed comfyui essentials requirement, used something from the basic data handling instead
FAQ
Comments (25)
Very good workflow, just needs good frame matching so camera movements and character movements track across shots effectively for action shots when the camera is moving. Track movements of non-linear too, e.g. "butterflies fluttering"
Thanks. For that part I'm thinking of cropping both start and end of the generations to put another transition generation in between two parts after they are generated that is only focused on smooth transition between end and start frames. I'm not really sure about the time cost tho.
I guess it wouldnt be impossible for them to add the option to input an image array instead of a single image for model to generate better transitions but that is out of my control.
ive looked through this multiple times and I cant seem to find it. Where are you defining how many frames get generated in each cycle?
Edit: Nevermind found it, it's in the latent subgraph with the resolution.
Just enter any of the I2V nodes and you will see the I2V latent subgraph. You can modify it inside there and it will apply for all of them.
Whoopsie I'm kinda late and maybe a little dyslexic..
i've never been so confused in my life
Thats probably what everyone thought switching from 1111 to comfyui. Did the subgraphs confuse you?
I apologize for my poor English.
This is a very impressive workflow. It is very educational. Regarding the subgraphs, there are still many points that I do not fully understand, but I intend to tackle them one by one. Considering the limitations of my environment, I plan to experiment with creating a version that runs within the 5B model based on this workflow. I hope it will be successful.
Its what it is. I do not agree with you on the spagetti part but I look forward to referencing things inside subgraphs from outside and changing important things on the main page without any of the connections.
Couldn't agree more, you hate the spaguetti until you notice it's a lot more confusing without spaguetti.
agree here, noidea where to change models, found some spot but other are nowhere
@domjanovic261 There's a loader node in T2V and I2V nodes, changing one will change all in I2V if you are on the correct version of comfyui frontend.
I love the way you designed this, even if it took a little digging to discover how it's built. Not sure if my system specs are the issue, but I can't seem to string more than FFLF2V 3 subgraphs before I OOM. But more confusing to me is why all my videos are coming out super sped up! I'm using the 14B High/Low GGUF models and the lightning T2V High/Low LoRAs. Any ideas what I can tweak to slow down the people's movements?
You need to use T2V models for T2V part, I2V models for I2V. Same goes for loras. Make sure you dont have duplicate loras.
You shouldnt get any OOM if you can finish the first I2V part because it uses the same model and loader for the next parts.
Make sure you are on the right version of comfyui frontend package because it simply could be a broken workflow issue due to wrong frontend.
This is great. Thank you so much.
This is the first "usable" long video workflow I was able to find.
I love to see this evolve, I think the biggest challenge is the character drift when the characters face is not visible in the last frame or the eyes are closed... I tried to build such a workflow myself but failed miserably... I ended up trying to use IPAdapter for FaceDetection and FaceMatching but it was a mess and never worked..
Besides that, my current problem is that the quality gets visibly worse with each step.. I can not see that in the painting video or in the cat video... The image gets "noisier" and "brighter" step by step
Added an example vid to show you what I mean.. No idea what is causing this. I use Q6K quantized models and some nsfw LoRa's, that's all. Oh and I use 512x512 format since input image is 1024x1024
Already looking forward to V0.4!!
Oh god thats a continious shot indeed, infinite perhaps.
I've noticed a sharpening effect as the video gets longer.
Its relatively less with GGUF models but still there. There's a fix using shift values and sigmas but I couldnt get around that yet.
I'd suggest using the fp32 vae for start, see if it makes any difference;
https://huggingface.co/Kijai/WanVideo_comfy/blob/main/Wan2_1_VAE_fp32.safetensors
Experimented with v0.4 a little, added florence captions and wan latent somehow takes multiple images and blends them but didnt like the output that much.
@iLegoLoon Thanks for the VAE suggestion, I will try that out. I currently have some of my (Wan 2.1 trained) LoRas under suspicion. I will try generating some vids without them and then see what's causing the degradation.
In my testing this works ok for videos where there's a lot of changing elements. Videos that have a lot of repetitive motion, where the scene isn't changing as much and elements are just shifting around... will run into the "photocopier effect" where the image deteriorates in subsequent rounds of video. It's inevitable because at every stage the final image drifts slightly from the quality and clarity of the original. It's not as noticeable after the first round but it does add up.
As long as the scene is changing, its not as obvious, because elements don't hang around long enough for you to start to notice the degradation. You can crank the steps to get a better quality output, but that can cause its own problems with overcooking a single stage.
@q5sys I'm currently running a few tests on this will do a v0.3.1 with optimized settings.
First thing I noticed was my decode tiled was configured wrong and you could see small tiles. Currently I'm experimenting with fp32 vae, lower cfg at no lora steps, shift value set to 5 etc. Will update if I can find something.
@q5sys yes I noticed that as well. There is also another workflow that does a "undress + blowjob + facial" combination of 4 videos and since the camera is moving around and changing, you don't really see the degradation. However if it's a static scene (like normal sex without changing angles) it's super noticeable.
@iLegoLoon fp32 vae didn't change anything, unfortunately. I use Q8 Model, no change. I also used FP8 model, same effect. Can't go higher since I'm locked to 16GB VRAM.
I think the only way is to run the final frame image through an "Img2Img" pipeline to "restore" the original quality without changing it much. But that is rather hard so setup, still playing around with it.
There is a fundamental understanding here- a video model has to invent a LOT of detail- i2v gives only a single 2D ref. The second gen for the next 5 secs will invent DIFFERENT detail, and there's nothing that can be done to prevent this incoherence using current extension methods, including this one.
In the future, a model could, say, do only 5FPS, and these would act as keyframes across, say, a 15 second sequence. Then other passes could 'fill in' frames between these frames. That would give us better coherence across a longer time in the same VRAM.
Another method would be to take the output of this workflow, and pass it through a system that dragged data from the first 5 seconds across the rest of the video in waves, each one acting as a refiner. This would be a very slow process, unfortunately.
Our problem is that the people creating the current models run then on 'blades' with a sheet ton of VRAM, They don't even think about peeps with home GPUs of 16-32GB VRAM. Sadly this means they won't even think about new methods that could give us coherence across much longer than 5secs. Today the best answer is to plan a long video carefully with 'tricks' used that best suit the way our current models work.
@iLegoLoon This also might be relevant... https://www.reddit.com/r/comfyui/comments/1n8erbt/psa_vhs_load_video_node_the_ffmpeg_version_avoids
this might be the closest thing ive found and tried to achieving my goal of making a movie with ai but one thing is to solve is the consistancy mayb if we can have the ai referance the previous segment that would fix all the problem with consistancy or something like that
I'm currently working on fixing the burn in/sharpening problem for longer videos. The transitions on my current test look better than the shared workflow but I wont publish it before fixing or improving existing problems.
Then there wont be a lot to do without messing with the latents themselves but I'm not entirely sure if its possible to feed the model a few blend frames and let those frames modify the denoising steps as all frames are modified at once and they probably dont know much about their neighbours.
If nothing comes out of that there is something that could work in my mind; render one part and next one then remove one second from each and regenerate that transition again but it will be costier than current process.
Or if there was a way to skip frames during sampling so we can generate certain frames and run the real generation at the end.