WARNING: Hey, I've lately moved towards LTX2.3 but I will publish a fix to workflow issues mentioned in comments once I have enough free time.
I've officially switched to LTX due to slowmo issues with lightx2v loras. I might share a workflow but that model is already capable of 30s on 720p on a 4070ti so I'm not so motivated to do so. This one would still work if you found the missing packages. Thanks everyone for their support.
It finally happened!
Now there's a way for smoother continuous videos thanks to SVI team and Kijai.
We are at v1.0!
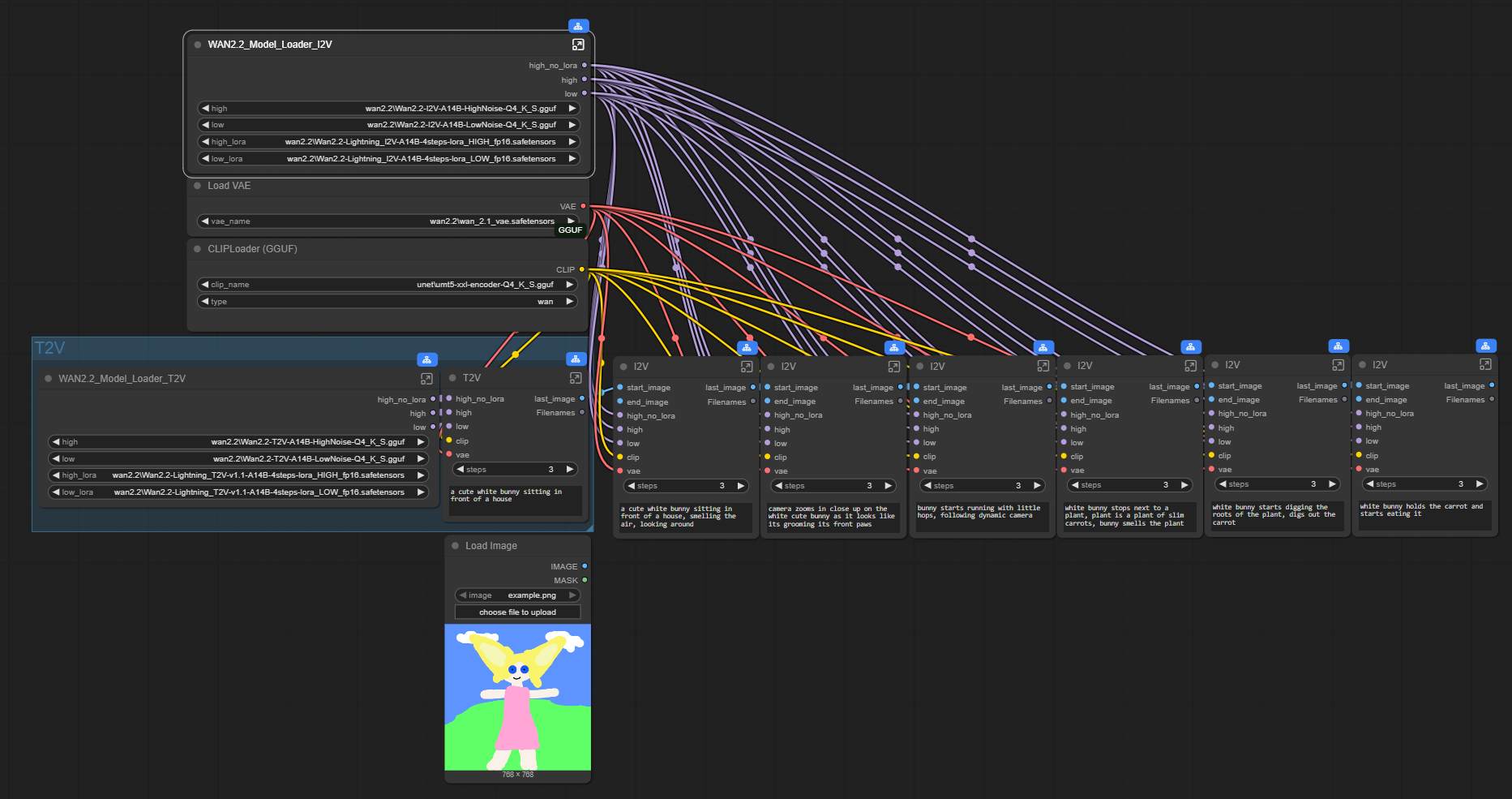
I've updated the workflow to add a few more features;
Video extend option by loading an initial video then converting it to latent that goes into first I2V(WIP)Option to switch between 3 and 2 ksampler phases by setting the initial step
Option to set cfg > 1 if you wanted to disable lightx2v
Images are saved partially in loseless format (use something like VLC to view them) and only loaded again on final merge, if something goes wrong you can merge those files to get a flowing video.
Implemented a bus system to reduce connections. Report if you have any issues but things should work as long as you have the right models and loras selected.
You can set and fix the seed for each part
There are options to upscale and interpolate before final save
Final save happens on main graph so you can preview your output
Slow motion issue probably persists. Couldnt find a consistent solution since when speed up using a third party tool every part becomes faster since they take previous latents as input until everything breaks.
Weak points of most SVI workflows right now is that it references first image in all parts so you might have background warping/chaning shape/textures on switches if the background has changed a lot.
I'll only be updating the workflow if kijai updates the node (there are two merge requests about end frame and better consistency(?)) and/or something breaks. So we can call this a semi final :)
Comfyui compatible SVI lora's;
LightX2V lora's I'm using;
FP32 vae:
Ultra Flux VAE for sharper !"Z Image"! outputs:
https://huggingface.co/Owen777/UltraFlux-v1/blob/main/vae/diffusion_pytorch_model.safetensors
GGUF still seems to be performing better than fp8 scaled in my experience.
Just share your outputs with us folks as well :)
v0.9
Left sampling on (1 + 3 + 3) steps with 4 parts (19s~). Takes around 10mins on my 4070ti with sage + torch compile. Feel free to extend it further if you need.
Everything is GGUF. Patch sage attention and torch compile are disabled by default but you are welcome to enable them back since they speed things up a lot if you have the environment set up.
You can set part specific or common lora's thanks to rgthree power lora node.
Happy generations! \('-')
Description
Edit: Removed last frame from the previous video to reduce amount of stillness
Initial version with unet loader + clip loader (gguf) + lightx2v + patch sage + torch compile
FAQ
Comments (14)
Thank you for sharing! Adding another one to merge six videos into one would be perfect. This effect is indeed much better than the for loop, the only drawback being that it takes longer
I'm thinking of adding it since Filename outputs are already there. Its just a busy week :)
Might collect a few more feedbacks to implement before to make the update significant.
How to add loras?
Go into the WAN2.2_Model_Loader_I2V subgraph. You can add a new lora at the end to only update high and low outputs to use loras. You may wanna add loras to high model before lightx2v lora is loaded so you can output high_no_lora(no speed lora) from there.
iLegoLoon i will try to make sense of that. Thank you
Simply a great workflow love it, delivers great results.
Do you think it's possible, to add some pause function between generated videos.? Like quality control, before it continues to generate the next video, and then remake that video clip again without needing to start all over.
Thank you, I'm not entirely sure. I want to implement seeds from outer scope. I'm not sure if I should limit user to use same seed for all (for more consistent generation) or seed per part but I'll keep this in mind.
iLegoLoon Fair enough, there is also now a "Stand In" Using an image of a character, as a inference through the generation. https://github.com/WeChatCV/Stand-In
That could be awesome to add, course many time after 20 seconds, the character can be extremely different from the original image.
Thats great! I created a continuous version of my WAN 2.2 I2V Lightning 4 Step Lora Workflow, based on this principle, which is also really fast and based on a workflow I found here or on reddit, (don't remember). I added sliders for width, height and length and added preview pictures for the last image. You can get it here: https://pastebin.com/TvDK5chT
Still no video stitching though. Does anyone know how to do that in comfyUI?
I have recognized none uses acceleration loras in these wflows no need?
did you steal idea from https://civitai.com/models/1416594/wan-aio-22-subgraphs ?
I thought of it on my own, didnt even know my packages were not up to date until I had figured out what to do. Didnt know subgraphs were on main branch since I was waiting for them and I also didnt know for loops were possible in comfyui before subgraphs :P
There is no "stealing" on this site. It's a place to share, remix, learn, and maybe borrow. If you're not okay with that, then hide your kids and your wife.
Whtas the point?? Totally different wfs!!