















Stabilizer
Name is misleading. This is NOT a LoRA that can magically fix your overfitted merged base model.
This is a finetuned model from pretrained model. But trained as a LoRA.
11k images. No bias, no default style.
Zero smooth plastic glossy AI image in dataset. Glossy Al images are polluting the world, but not on my watch, I handpicked every single image.
Natural language captions from Gemini, rather than tags in random order with high FPR.
Standard noise scheduler. Inpainting/img2img friendly.
Improvements:
You can get the style exactly as it should be (as long as the model knows).
Comparisons with pretrained base model:
https://civarchive.com/images/84145167 (general styles, you get the style exactly as it should be)
https://civarchive.com/images/84256995 (artist styles, no style shifting because this model does not have bias)
See more xy plots in cover images.
Why LoRA?
This LoRA is a DoRA (from Nvidia), which is more efficient than traditional LoRA.
Enough for thousands of training images.
What? You prefer to download and store a 7GiB checkpoint than a 80Mib LoRA?
Share merges using this model is prohibited. FYI, there are hidden trigger words to print invisible watermark. I coded the watermark and detector myself. I don't want to use it, but I can.
This model only published on Civitiai and TensorArt. If you see "me" and this sentence in other platforms, all those are fake and the platform you are using is a pirate platform.
How to use
It is highly recommended that you use pretrained base model.
And load this LoRA with strength 1.
Versions:
cknb (ChenkinNoob-XL).
nbvp10 (NoobAI v-pred v1.0). FYI: you don't need CFG hacks (RescaleCFG etc.).
nbep10 (NoobAI eps v1.0).
illus01 (Illustrious v0.1).
Load this LoRA first
This LoRA uses a new arch called DoRA from Nvidia, more efficient than traditional LoRA. But the patch weight is dynamically calculated based on the currently loaded base model weights (which will be changed when you loading other LoRAs). To avoid unexpected changes, load this LoRA first.
Specify styles in prompt
This model does not have an strong default style and is very creative. You must specify the style you want in the prompt.
If you want to use it on finetuned/merged base models:
I personally disagree this. This is not the model's original intention. But this is a LoRA after all.
Be aware:
This LoRA can't remove glossy shiny plastic AI style. Although the dataset is "AI image free". It can't make AI image polluted 1girl overfitted 50 versions of Nova furry 3D anime WAI or whatever look better. What the model learned is learned. Use a pretrained base model if you want to get rid of overfitted AI style.
What is "overfitted AI style"? This is what Craft Lawrence (from spice and wolf) should be, if you've seen the anime: img. This is what those AI style polluted 1girl overfitted model generated: img
Some base models already merged this model. If you got deformed images with this LoRA even at low strength (e.g. <0.5). Your base model has already merged this LoRA (and you merged it twice). And the model weights got multiplied (because how the DoRA works) and collapsed.
Beware of fake base model creators, aka. thieves. Some "creators" never do the training, they only grab other people's models, merge them, wipe all metadata and credits, and sell it as their own base model.
Update log
Moved here
Description
FAQ
Comments (6)
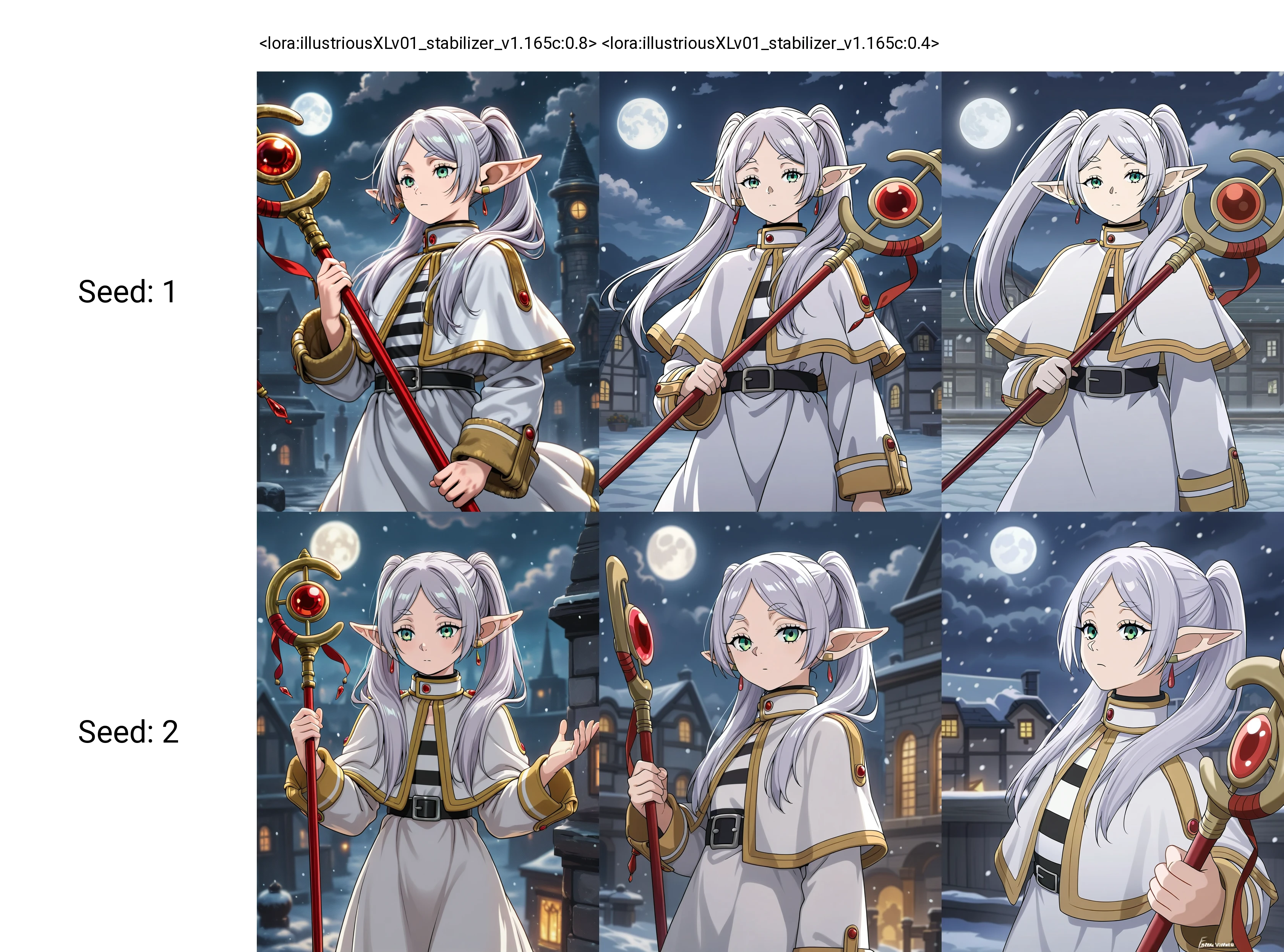
165c surely improves some weak aspects in 164, although the effects are really strong, recommend setting the strength around 0.3-0.4 for ideal results.
yeah, the effects are strong because I did that on purpose.
It is fine on vanilla base model. But on merged model (which may have 10+ LoRAs inside), you may need to lower the strength.
Strangely, this stabilizer causes various artifacts for me, and at any weight. Also, this thing greatly changes the faces of the characters, they become less recognizable...
🪱
After experimenting with the illus01 1.165c and illus01 1.164 versions of this lora I have observed several issues which significantly affect their usability.
The first issue I have observed is that while running either lora version with the recommended NoobAI e-pred v1.1 model and settings, I've encountered significant visual artifacts in generated images. Furthermore, there seems to be an imposed 3D style on many of the outputs.
The second issue I have observed is that switching to other models than NoobAI e-pred v1.1 or running these stabilizer versions with additional style loras will frequently result in outputs with hyper saturated colors and very high contrast.
I hope someone has a solution for these issues or that they will be addressed in future versions of these loras.
Thanks for the feedback.
"significant visual artifacts" I need your settings, prompts etc. to reproduce.
"imposed 3D style", this is expected. There is no default style. This is crucial to fix base model overfitting effects. You need one or more style hint in prompt to tell the model what style you want, e.g. game name, character name, artist names.
"additional style loras will frequently result in outputs with hyper saturated colors and very high contrast." That is their problem, (70% belongs to Civitai as well). Those models were trained with "noise offset." , and Civitai online trainer not only enabled it by default but also set the strength to 0.1.