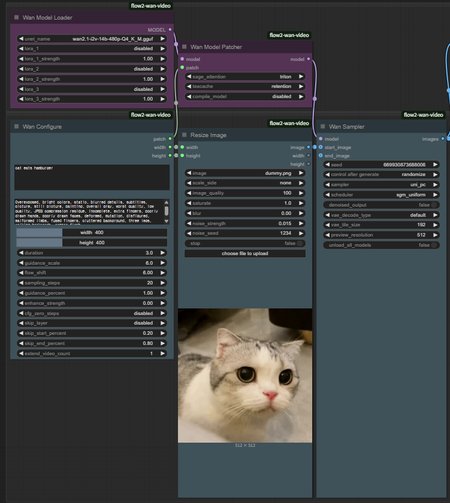
Simple Wan wrapper released
Requires Comfyui version v0.3.27 or higher.
https://github.com/Flow-two/flow2-wan-video
(OPTIONAL) Triton & SageAttention Installation
https://civarchive.com/articles/12851/easy-installation-triton-and-sageattention
Installation
option 1
Download archive zip.
flow2-wan-video.zip extract to
ComfyUI\custom_nodesGo to
ComfyUI_windows_portable/folder and Run command topython_embeded\python.exe -m pip install -r "ComfyUI\custom_nodes\flow2-wan-video\requirements.txt"
option 2
Go to comfyUI custom_nodes folder,
ComfyUI/custom_nodes/Go to
ComfyUI_windows_portable/folder and Run command topython_embeded\python.exe -m pip install -r "ComfyUI\custom_nodes\flow2-wan-video\requirements.txt"
Upscale Model
https://huggingface.co/mixfox/Upscale-Models/blob/main/4x_foolhardy_Remacri_ExtraSmoother.pth
to ComfyUI/models/upscale_models
Wrapper Features
Various image settings (blur, saturate, noise, quality)
Various model patcher integrated into one
Support for frame interpolation
Support for upscaler
Support high quality sampling preview
Support teacache retention mode
Support model auto download
Version 1.0
Features
Easy and simple parameter setup
Supports various parameters to minimize artifacts
Supports Skip Layer Guidance (SLG) to minimize artifacts
Two-step sampling process for faster sampling speed and relatively less noise
Faster sampling speed with TeaCache support
Supports various samplers
Easy upscaling control
Supports various frame rates for frame interpolation
Supports lower VRAM usage with the introduction of gguf
Nodes
ComfyUI-Custom-Scripts
ComfyUI_LayerStyle
rgthree-comfy
ComfyUI-KJNodes
ComfyUI-VideoHelperSuite
ComfyUI-Frame-Interpolation
ComfyUI-mxToolkit
Warning: You are fully responsible for any legal or ethical violations that may occur in the production of this video. It is important to comply with all relevant laws and regulations when creating and distributing the video, and to be cautious not to infringe on the rights of others.
Description
fixed error extends video
FAQ
Comments (24)
I find the new native i2v workflows produce grainier results with more artifacts than the old version. Try as I might, I cannot find parameters to generate a video as good as the defaults in the old one. Any suggestions for how to set the current version the same as the old?
Thank you for your work!. It is working perfectly on my pc. Do you happen to have a T2V workflow?
Hello, which option is related to the video playback time?
workflow not working. It creates only still image instead video. Second Video Combine node returns error - Int recieved while expects float.
On another attempt it returns OOM error and refuses to use shared memory.
On third attempt at reduced duration it just stuck at 0 steps.
This is so far one of easiest simple workflows for wan i tried yet to simply and quickly do img2vid or text2vid without a lot of clutter and over complication. and with sage attention and triton install guide it runs pretty quick on my 4090. I posted some img2vid's i made today with your workflow.
This is my fav WAN workflow! Great job! Maybe you can do a text to image as well? Would be very nice!
Hi there, possible to make it compatible with skyreels v2 ?
TypeError 401 WanvideoSampler f2.
TypeError: teacache_wanmodel_forward() got an unexpected keyword argument 'control'.
When you activate teacache, this message appears.
5070ti.
nice workflow
Is there any way to use more than 3 loras with this workflow? Thank you!
Edit: I miss the old Lora Stacker from the previous version, if there was any way to incorporate that back in that'd be amazing
Edit2: I manually added the power lora stacker back in and an additional Load Clip to make it work and it works great
Q8 720p i2v gguf error
'WanVideoSampler_F2
teacache_wanmodel_forward() got an unexpected keyword argument 'control''
flf2v i2v 720p error
'WanVideoSampler_F2
skip_layer requires teacache to be enabled'
I have TeaCache installed though.
Also if I set extend_video_count to 2 I get
'WanVideoSampler_F2
The expanded size of the tensor (49) must match the existing size (17) at non-singleton dimension 0. Target sizes: [49, 720, 720, 3]. Tensor sizes: [17, 720, 720, 3]'
Hi, I'm getting times of 20 min at 512x896 with 1088x1920 images in a wan teacup kijai i2v, a long wait time for me, how is this cheese???
when extend video count is >1 it gives me this error on wansampler f2
RuntimeError: The expanded size of the tensor (49) must match the existing size (65) at non-singleton dimension 0. Target sizes: [49, 512, 512, 3]. Tensor sizes: [65, 512, 512, 3]
Full traceback:
!!! Exception during processing !!! The expanded size of the tensor (49) must match the existing size (65) at non-singleton dimension 0. Target sizes: [49, 512, 512, 3]. Tensor sizes: [65, 512, 512, 3]
Traceback (most recent call last):
File "E:\Projects\ComfyUI_windows_portable\ComfyUI\execution.py", line 345, in execute
output_data, output_ui, has_subgraph = get_output_data(obj, input_data_all, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb)
File "E:\Projects\ComfyUI_windows_portable\ComfyUI\execution.py", line 220, in get_output_data
return_values = mapnode_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb)
File "E:\Projects\ComfyUI_windows_portable\ComfyUI\execution.py", line 192, in mapnode_over_list
process_inputs(input_dict, i)
File "E:\Projects\ComfyUI_windows_portable\ComfyUI\execution.py", line 181, in process_inputs
results.append(getattr(obj, func)(**inputs))
File "E:\Projects\ComfyUI_windows_portable\ComfyUI\custom_nodes\flow2-wan-video\custom_nodes.py", line 714, in process
new_images[i 49:(i + 1) 49] = images
RuntimeError: The expanded size of the tensor (49) must match the existing size (65) at non-singleton dimension 0. Target sizes: [49, 512, 512, 3]. Tensor sizes: [65, 512, 512, 3]
i generate with sage and teacache it have error
x0 is valid processing in default vae decode...
and it will regenerate again
Works well.
If you can build me a version with 10 integrated lora loaders I will send you 20 bucks. I'm too dumb to even open those "boxes".
Actually worked like a charm.
can Causvid lora work with this one,
Cant you make an update for your very first workflow? I loved how the previous one worked.
Your original one had Florence had resolution, video length, sample steps, it could upscale and had frame interpolation
Is there a way to use this checkpoint https://civitai.com/models/1295569?modelVersionId=1463630 instead of the ones that are on the list?
Legendary workflow, using only two custom nodes, and it's flawless.
Minor nuisance is that you need to put gguf's into checkpoint folder instead of unet.
LoRAs are disabled on the Wan Model Loader. Is this a bug? All it says is disabled, even when there are loras in the folder
Wow, very nice. I have a RTX 5070TI 16 gb, 64 gb DDR5 RAM, Ryzen 9 9950X and this workflow increased my performance by 2.3 times for a project I have been working on. 760x760 3 second clip @ 30 steps went from 30 min to 13 min. Thank you so much!
FUSIONX: use wan2.1_i2v_720p_14B_fp16.safetensors or fp8 with lora Wan2.1_I2V_14B_FusionX_LoRA.safetensors and this goes very fast, just change in wan_Configure: guidance_scale:1.0, sampling_steps:8, the lora fusionx:1.0
Just out of curiosity, how does this workflow work without any mentions of CLIP, VAE and Clip Vision models that had to be defined in other workflows? Are these things not needed to run Wan?
Looks like we don't have an active mirror for this file right now.
CivArchive is a community-maintained index — we catalog mirrors that volunteers upload to HuggingFace, torrents, and other public hosts. Looks like no one has uploaded a copy of this file yet.
Some files do get recovered over time through contributions. If you're looking for this one, feel free to ask in Discord, or help preserve it if you have a copy.