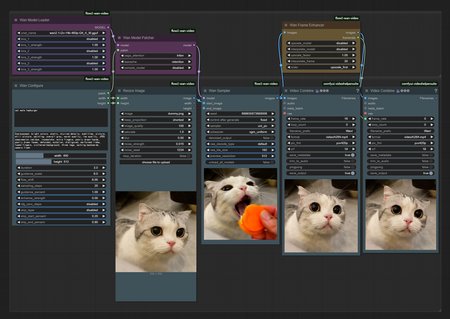
Simple Wan wrapper released
Requires Comfyui version v0.3.27 or higher.
https://github.com/Flow-two/flow2-wan-video
(OPTIONAL) Triton & SageAttention Installation
https://civarchive.com/articles/12851/easy-installation-triton-and-sageattention
Installation
option 1
Download archive zip.
flow2-wan-video.zip extract to
ComfyUI\custom_nodesGo to
ComfyUI_windows_portable/folder and Run command topython_embeded\python.exe -m pip install -r "ComfyUI\custom_nodes\flow2-wan-video\requirements.txt"
option 2
Go to comfyUI custom_nodes folder,
ComfyUI/custom_nodes/Go to
ComfyUI_windows_portable/folder and Run command topython_embeded\python.exe -m pip install -r "ComfyUI\custom_nodes\flow2-wan-video\requirements.txt"
Upscale Model
https://huggingface.co/mixfox/Upscale-Models/blob/main/4x_foolhardy_Remacri_ExtraSmoother.pth
to ComfyUI/models/upscale_models
Wrapper Features
Various image settings (blur, saturate, noise, quality)
Various model patcher integrated into one
Support for frame interpolation
Support for upscaler
Support high quality sampling preview
Support teacache retention mode
Support model auto download
Version 1.0
Features
Easy and simple parameter setup
Supports various parameters to minimize artifacts
Supports Skip Layer Guidance (SLG) to minimize artifacts
Two-step sampling process for faster sampling speed and relatively less noise
Faster sampling speed with TeaCache support
Supports various samplers
Easy upscaling control
Supports various frame rates for frame interpolation
Supports lower VRAM usage with the introduction of gguf
Nodes
ComfyUI-Custom-Scripts
ComfyUI_LayerStyle
rgthree-comfy
ComfyUI-KJNodes
ComfyUI-VideoHelperSuite
ComfyUI-Frame-Interpolation
ComfyUI-mxToolkit
Warning: You are fully responsible for any legal or ethical violations that may occur in the production of this video. It is important to comply with all relevant laws and regulations when creating and distributing the video, and to be cautious not to infringe on the rights of others.
Description
fixed resize node
FAQ
Comments (24)
Dragging workflow_example_i2v.json into ComfyUI window reports 6 missing nodes. No workflow appears.
I git cloned manually, ran the requirements.txt script, updated all nodes, it doesn't detect missing nodes, but it is missing nodes.
Here's startup log errors (I'm using Comfy Desktop):
I’m running ComfyUI on Colab, but I keep failing to install it:
0.0 seconds (IMPORT FAILED): /content/ComfyUI/custom_nodes/flow2-wan-video
for the new workflow:wrapper:1.0
WanVideoSampler_F2
index 0 is out of bounds for dimension 0 with size 0
I like how clean this setup looks. When you say 'fast' what does that mean? Fast as in setup or does this bring performance improvements that the usual kijai nodes dont? I don't want to install it yet for fear of breaking my install
When I load a workflow, none of the nodes are visible.
What could be the problem?
When i press go, terminal says “completed in .3 seconds” and nothing is outputed. Any clues anyone?
It's nice to see the work of a professional. Probably the best workflows I've ever seen.
welcome back, it's best wan 2.1 workflow. Could you add florence2 nodes like your old workflow?
Man you Very Great
I'm unable to find/download any of the flow2 nodes. Here's my error. Any idea why?
Failed to find the following ComfyRegistry list. The cache may be outdated, or the nodes may have been removed from ComfyRegistry.
flow2-wan-video
Thank you. I tried this out with the easy install on a fresh comfyui to see how this goes. works great.i struggled with install for a while until i figured out i had to upgrade setuptools. but works. the example i2v workflow and default cat image and prompt after 1st run finishes only 1 minute and 15 or so seconds on my pc and 4090 which is pretty good for wan. wan was taking so long when wan first launched of 5-6 minutes (maybe higher resolution, not sure, but i never seen anything close to this speed trying various settings)
So I2v works with lora's but T2V is outputting a ton of errors:
ERROR lora diffusion_model.blocks.9.ffn.0.weight shape '[8960, 1536]' is invalid for input of size 70778880
Etc. all various blocks. I tried multiple loras
Great work as always!
Really appreciate your workflows.
Is the endframe option a placeholder or does it only work with a specific config (e.g. only with safetensors instead of gguf)? It doesn't seem to work if I add an image to the end image input. (with 1.0.3 and Wn Q6)
How can I use the wan2.1 model I downloaded earlier in this workflow? After I select my own model to start, it still downloads the model by itself. Where should I adjust the parameters of Teacache? I only see a mode selection. Also, where can I select VAE and Clip?
Initial testing seems promising, but needs more documentation about nodes.
I'm very pleased to see another workflow!
And it was very smooth when I used it.
BUT I'm sorry to ask you about this,
does the 'end_image' node in the sampler work?
It doesn't seem to be working at all, after trying twice.
Should I enable "skip layer" option in config?
or Should I increase the CFG value or LoRA strength?
I'll share an example result with the workflow at the gallery. Please check it.
Always, thank you!
I have a error code like this.
WanVideoModelPatcher_F2
'NoneType' object is not subscriptable
Thanks for making this awesome workflow! I've been having more stability issues than the previous version with the main issue being generation will stall on 0% and stay there until cancelled, which means you can no longer queue up a bunch cause it never progresses. I don't know enough to guess at the reason
GGUF model >> teacache worked
other model >> teacache not worked
import failed?
My solution is~
delete (python_embeded\lib\site-packages\bitsandbytes*) folders..
Any way to update this workflow to split the work across 2 GPUs?
This is a surprisingly packed workflow. Thanks for the hard work!
is it only me cause the keep image proportion from 1.0.6 i2v keeps cropping out any wide image to the center unlike 1.0 even if i try changing the 3 options
Looks like we don't have an active mirror for this file right now.
CivArchive is a community-maintained index — we catalog mirrors that volunteers upload to HuggingFace, torrents, and other public hosts. Looks like no one has uploaded a copy of this file yet.
Some files do get recovered over time through contributions. If you're looking for this one, feel free to ask in Discord, or help preserve it if you have a copy.