
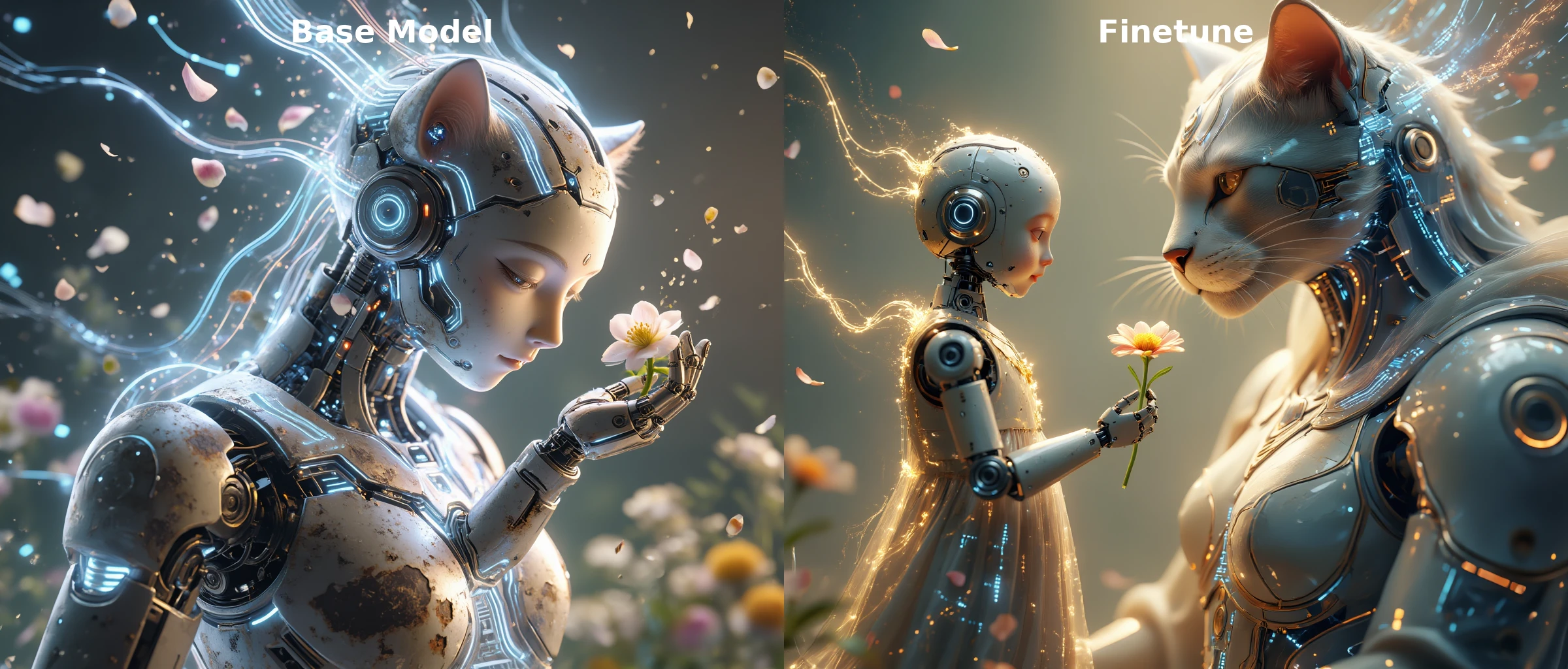




The purpose of this finetune is to improve the visual aesthetics of the Z-Image "Base" (Non-Omni) model. This is very much a proof of concept finetune. Its beta stage and will likely need more refinement.
Update as of 1:35pm PST: I just fixed the file. It should work in ComfyUI now. It is called ZImage_Eminence_v1_fix.safetensors
Version: Beta 1
Features
Improved visual aesthetics
Maintains base model's general results
Trained on word tags, short and long descriptions to maintain broad understanding. (Z-Image paper: https://arxiv.org/pdf/2511.22699)
Notes
All images are oneshot generations using the same seed. They were generated using musubi-tuner.
Issues
Unknown. Sampling looks decent across a variety of topics but I am not aware of any systematic issues but I'm sure you will let me know.
Shoutout
OneTrainer: Awesome job everyone! Seriously, if you are not using OneTrainer, I would definitely recommend checking it out. Lots of functionality and they offer features/concepts that are taken directly from research papers.
Musubi-tuner: kohya-ss is a legend! Another great trainer. Updated quickly and great notes.
Z-Image Team: Thank you so much for the detailed paper. A great source of information, strategy and concepts. I can read 100% of it and understand about 15% of it but the 15% is enough to emulate concepts at-home. I would highly recommended checking out the research papers. These are a great source of information.
Civitai: Thank you all the hard work and posting/updating everything so quickly!
ComfyUI Team: Thank you for the awesome community support and continued development!
Description
v1
FAQ
Details
Files
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.