









This is my first distributed workflow for ComfyUI.
I had a simple idea to "re-image an existing image" type request. The idea was born, and this is it executed. In a nutshell this workflow take an image you give it, runs it through a image to text model, then re-combines what the image to text generates back into a prompt with T5xxl and ClipL along with any LoRa's or CSV Styles you want.
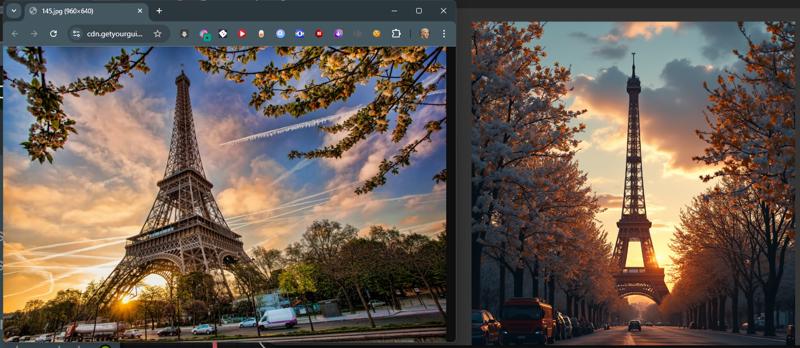
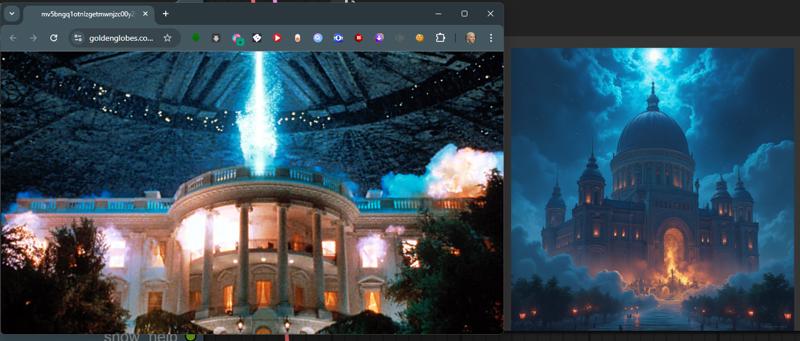
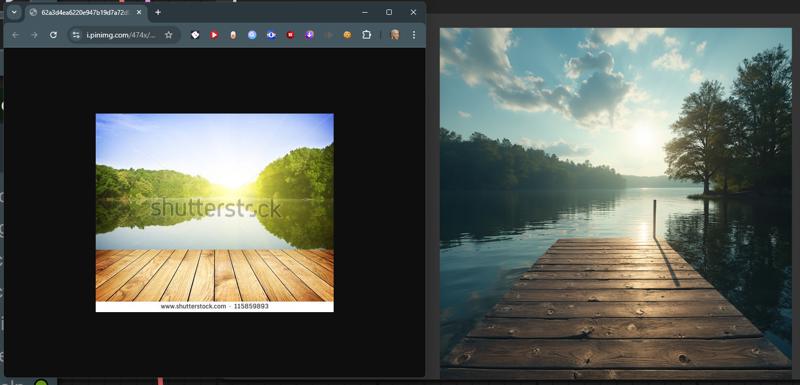
I have given some example pictures I am using the Flux GGUF models for this workflow but with a little editing you could alter it to fit any model.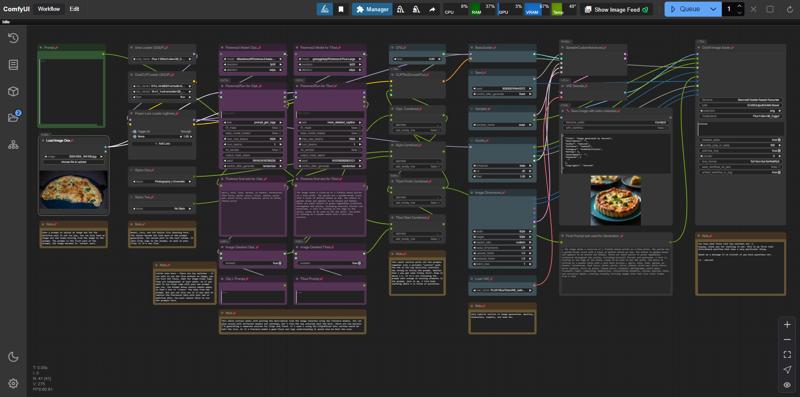 Some examples of what it will do. To the left the image directly from the internet. To the right, what the model did to "re-imagine" the that image.
Some examples of what it will do. To the left the image directly from the internet. To the right, what the model did to "re-imagine" the that image.
Description
This one uses a totally different way of Image to Text. This doesn't have a Florence model so even less VRAM, but it seems to be slower, significantly slower. It's also not very descriptive. This was actually my starting point for the project. The Image Text only lists large broad descriptions with no details. Just check out the Independence Day image, it's because it describes the image in only extreme basic descriptions. The last 3 images in the set are the same Movie shot, and it's vastly different from each other. Where this workflow might work well is extremely simplified images. Otherwise it just doesn't produce anything like the original image most of the time.