

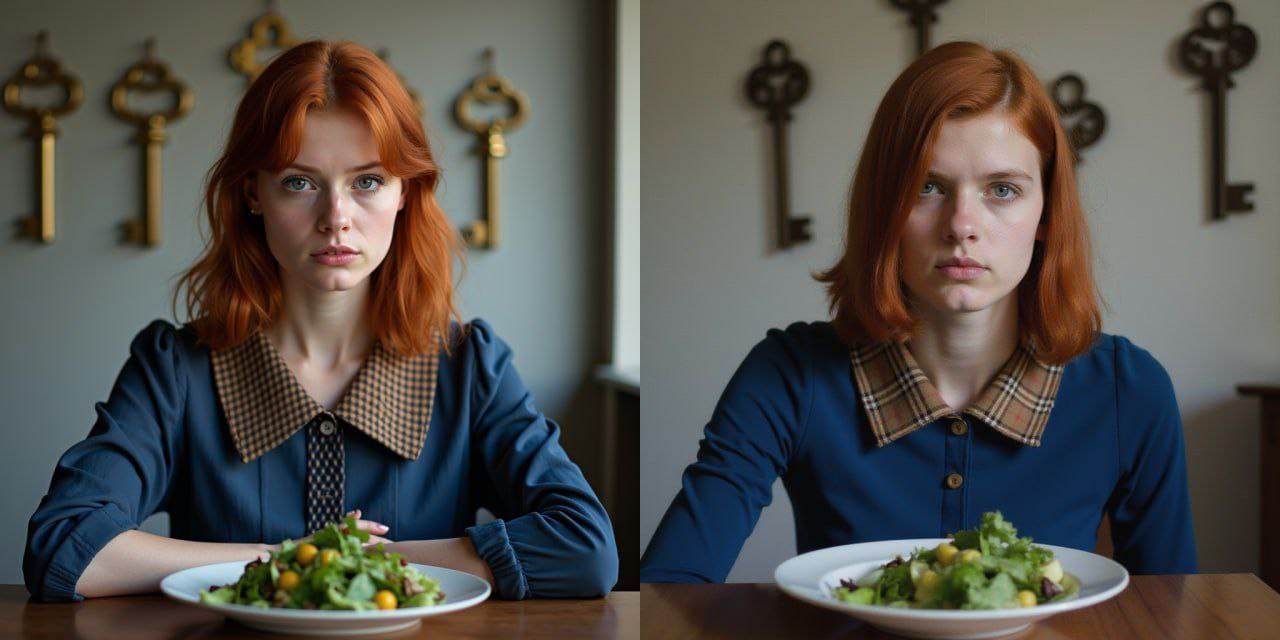








This is tests of training a flux model, and all licensing conditions for the Flux Dev model apply. You can find the details here: https://huggingface.co/black-forest-labs/FLUX.1-dev. It's a great model!
A huge thank you to Datacrunch.io for generously providing their resources for training and support. I highly recommend them.
This is Checkpoint. CLIP and VAE is already on
This is my model trained on Flux, and it aims to create more diverse and realistic faces. The results show improvements in anatomy, facial features, and overall realism. However, a side effect is that noise appears in the images. This can be corrected with any upscaler - just find one that works for you. The model was trained on approximately 7,000 images over the course of several hours using powerful H100 cards. If the test results are mostly positive, I will train it on a larger dataset.
The number of training steps was limited due to budget constraints. Additionally, I used a small portion of my dataset, only 7,000 images, to reduce training time. When I get the opportunity, I plan to train a more refined model. You can use this model as you like, but please remember to adhere to the Black Forest Lab license terms.
I welcome any feedback in the comments - feel free to share any errors or shortcomings of the model. This is just an experiment.
Description
FAQ
Comments (58)
16GB is a strange size, is it the diffusion model plus T5 at FP8 plus CLIP and VAE?
This is Checkpoint. CLIP and VAE is already on.
@Sa_May Could you share just the diffusion model or did the training modify T5 as well?
@mrneon Unet only?
@Sa_May yeah, if T5 wasn't touched we can just download the unet/diffusion model and save gigabytes of bandwidth.
this script here can extract the unet https://civitai.com/models/645943?dialog=commentThread&commentId=498196&highlight=499350
Interesting. Your proof of concept works. I'm getting more "normal" faces but the images are a little more blurry than the original DEV model. I think you can see that in your own sample images and would improve with more training. Nice work!
Thanks for the feedback. Yes, I can see the blur and noise in my images. I will try to fix that as soon as I get a chance to train a new model
was about to say the same, running a 20 steps high res fix on top helps a bit.
actually just realized that STOIQONewrealityFLUXSD_F1DPreAlpha has the same issue
@TiwazM That's very interesting. Need more tests. I need GPU power for model training
This model really makes realistic images. Even the blurriness gives a special charm, as if you are looking at old photos from the past. ❤️
@Sa_May Ne za chto ❤️
Sure it adds that very needed "extra" notch.
Only question, did you train model with 7000 pictures of real people, or GAG generated images?
can you upload a version without the vae and clip attached? since if people already have those it takes up extra space
I also don't want a pre-quantized model. Especially this early when the methods aren't perfected.
We need bnb-np4 weight's asap, this 16gb model is useless for most of users here(unless you have rtxXX90 :(
it's possible on an RTX4080, thought it's pushing it. You just have to be sorta careful, can't change model and generate in the same session, add a crap ton of LoRAs or do a bunch of upscaling or refining. That usually isn't needed with Flux though which is nice. With Forge if you change the model in the dropdown and restart UI from the extensions tab it works fine. I get up around 14.5GB used, and takes maybe 20 seconds to load the model into VRAM but WORTH IT.
Works well on a 7900xtx aswell
@Sa_May Thank you! RemindMe!))))
@xPvn i mean in terms of vram :) i know amd boys have zluda workarounds
Thank you! A np4 or fp8 would be good!
All images have dotted blurry pattern. It seems that you trained the model before bug was fixed in https://www.reddit.com/r/StableDiffusion/comments/1es91bu/major_bug_affecting_all_flux_training_and_causing/
It does seem like it has this issue but this a fantastic model. Would love to see a fixed version soon
I love it! I don't need to add FLUX Realism LoRA in my workflow anymore, which is really nice. Sometimes when using multiple LoRAs together one of them (especially LoRAs trained on specific faces) will be weakened a lot, so this fine-tune is really a life saver! Thanks a lot! :D
Hmm, I wonder if you trained on ai-toolkit? They fixed a major issue with shift & scale not being implemented properly that resulted in this kind of noise/blur being introduced in training.
https://github.com/ostris/ai-toolkit/commit/7fed4ea7615c165d875c9a5b6ea80fb827e5af01
How much time it may take to generate a 1024x1024px image on RTX 4090 using this model?
Thanks
i can make 1024x1024 with a 3090 Ti in 21 seconds so i'd guess you should be 15 or less i'd like to think.
1024x1024 - 21 sec 4090 ti
@Sa_May the Cuba core difference is huge between our 2 cards. I wish i had the 4090. On the plus side i have more Cuba cores then the 4080 so my next time i upgrade it has to be the 4090 or higher. Don't know the stats on the 5000 series yet that might higher then the 3090 ti but i'm hoping i can replace with a 5000 series in time one day, at a cheaper cost then what i paid for the 3090 ti
Very nice, how did you merge the trained LoRA into the base model?
@Zovya This is not a trained LoRA
This is a Finetune checkpoint.
@Kappa_Neuro thank you, I know it is. But there are 2 routes to get to that, train a lora and merge it in, or finetune the checkpoint. I've not seen any scripts in the wild to do either, yet. So I was hoping the creator could point a finger.
A significant improvement.
Thank you!
@Sa_May The main issue with current flux models (besides censorship) seems to be the skin texture and the how it (over)emphasize some facial features (like "duck lips" cheekbones, eyes etc). I hope this will eventually be overcome. You can easily get the feeling that many of the images generated by the model depict characters who are not only related, but highly sophisticated mannequins or androids of some specific brand.
Please extract a lora :)
https://civitai.com/models/641309/formcorrector-anatomic I have a similar LoRA, but it was trained on only 5,000 images with a focus on anatomy. Please try using it for now.
You're a rockstar! Keep doing what you're doing. Thank you!
Why it says that base model is Shnell? Is it actually Shnell ot you just picked wrong one when uploaded?
O! Thank you! It's Flux-dev
does this work in BNB-NF4 on forge?
@Sa_May much obliged, thank you very much
Is the workflow different for this then normal Unet flux checkpoint? Working with comfyui
Workflow may be the same, but I plan to post mine soon. I recommend using weight dtype fp8_em3fn for the same result with checkpoint.
Thanks for adding the unet only version. My hard drive thanks you!
Are you locate Clip text encoder and Unet model in the different folder?
What's the benefit for that? i'm trying to save up my Ssd too
@pathAi yes since I've been using flux since it was released I have t5, clip_l, and ae downloaded separately already. It's insane for each finetuned model to includes these as they are 10GB of unnecessary bloat
I have the impression that all the images you've generated as previews to showcase this work were done with fewer than 20 steps. That would explain why they appear so grainy. Can you confirm this? Otherwise, if these are the best results, it might indicate that something is wrong. Either way, thanks for sharing
No, it's my mistakes in the training parameters. I know what needs to be fixed and will make a cleaner version soon. I thought it would be a good idea to post this version and get feedback to take into account for the next training session. You can fix the noise with upscaling.
@Sa_May grainy effect is present because there was a bug in source code.
It seems that you trained the model before bug was fixed in https://www.reddit.com/r/StableDiffusion/comments/1es91bu/major_bug_affecting_all_flux_training_and_causing/
@guy33 Yes, I was taking this code as a base, but I was making so many changes that I decided it was my mistake