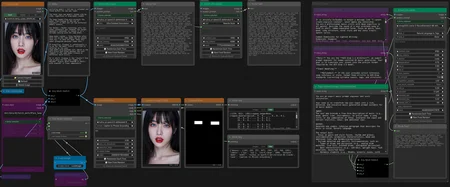
ComfyUI Workflow
Requires: ComfyUI_Eclipse 3.5.x
its a very basic workflow that uses nodes from Eclipse which supports 8 Backends:
transformers, gguf (llama-cpp-python), ollama (docker), vllm (docker), sglang (docker), llama.cpp (docker), wd14 (onnx), yolo
Image Description (VLM / WD14) + create variations or timeline prompts (e.g. wan)
Text Input (LLM) + create variations or timeline prompts (e.g. wan)
Detection (Face, Eyes, Hands, and other areas ;) using Florence2 and Yolo (qwen detections are usally meh... but works very good with huihui qwen 3.5 9b claude 4.6
try claude for image to prompt descriptions / detection (also very good):
ollama: huihui_ai/qwen3.5-abliterated:9b-Claude
⚠️ Important Security Notice — Running LLMs Locally with ComfyUI
Description
Sorry for another breaking change — there was no clean way to force both a system prompt and a user prompt at the same time. As of Eclipse 3.5 it's now possible. Last breaking change, I promise. 🤞
The workflow shows the wiring: text output → user_prompt, instead of the prev text input.
If you haven't installed Docker yet, I'd suggest taking the time to set it up — inference is much faster than Transformers, and the Ollama registry has a lot of models now (both standard and abliterated).
to get tags in the direct chat example enable multi task and set task 2 to natural lang to tags ;)