Loras used - beeg - (and my sheer lora)
No real Loras where used here for female Dominance - this is all from prompting.
Add more loras. get more from it. ;)
New style : Femdom



This has become such a big project i am struggling 
to find every flaw, so expect some.
It will be updated every 2 days until i feel like i cant fix anymore - i wont be adding more features i think just tweaks.
Will update over the next few days. - but i need a break lol im tired :D
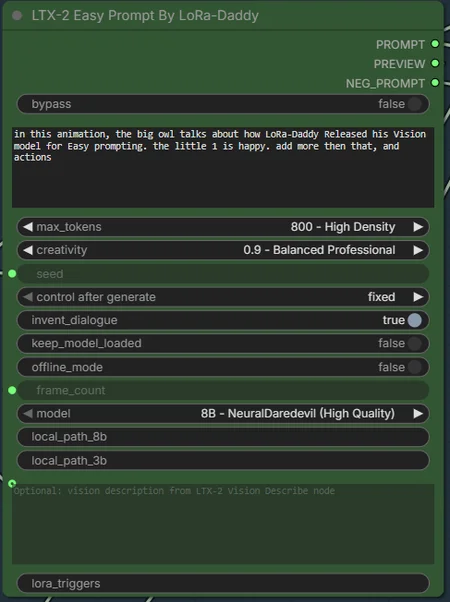
The old Lora daddy Easy prompt was 2000 lines of code,
This 1 + the library is 14700 - 107,346 words Between your prompt and the output.
DELETE YOUR ENTIRE - Comfyui\custom_nodes\LTX2EasyPrompt-LD
FOLDER AND RE-CLONE IT FROM Github
Also you will need The lora loader
WORKFLOW
if the tool is great and love you it and only if. consider buying me a coffe <3
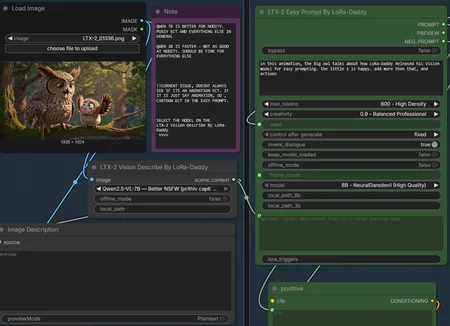
keep in mind i only do text to video, this stuff would probably work better image to video like the loras associated with this stuff would suggest.
Sex Position Triggers ( I HAVE ONLY TRIED Cowgirl and dildo so far - this is a placement holder for future loras, as it has full instructions on how to do it + dialogue)
missionary missionary, face to face, on her back
cowgirl cowgirl, on top, riding him, rides him, sitting on him
reverse cowgirl reverse cowgirl, facing away on top
doggy doggy, doggy style, from behind, on all fours, bent over
blowjob blowjob, blow job, going down on him, fellatio69 / sixtynine69, sixty nine, mutual oral
riding (solo toy)riding a dildo, riding a toy, riding a vibrator, dildo riding, solo riding
So this has been a fun little project for myself. This is nothing like the previous prompt tools.
it has an entire dialogue library Each possible action had 30 x 4 selectable dialogues that SHOULD match the scene
plus there is other things it can add like swearing / other context - (this is assuming you don't use your own dialogue or give it less prompt to work with.
Now i've added a music Genre preset selector
44 music genres, each mapped to its own lyric register and vocal style: 🎷 Jazz · 🎸 Blues · 🎹 Classical / Orchestral · 🎼 Opera 🎵 Soul / Motown · ✨ Gospel · 🔥 R&B / RnB · 🌙 Neo-soul 🎤 Hip-hop / Rap · 🏙 Trap · ⚡ Drill / UK Drill · 🌍 Afrobeats 🌴 Dancehall / Reggaeton · 🎺 Reggae / Ska · 🌶 Cumbia / Salsa / Latin · 🪘 Bollywood / Bhangra ⭐ K-pop · 🌸 J-pop / City pop · 🎻 Bossa nova / Samba · 🌿 Folk / Americana 🤠 Country · 🪨 Rock · 💀 Metal / Heavy metal · 🎸 Punk / Pop-punk 🌫 Indie rock / Shoegaze · 🌃 Lo-fi hip-hop · 🎈 Pop · 🏠 House music ⚙️ Techno · 🥁 Drum and Bass · 🌊 Ambient / Atmospheric · 🪩 Electronic / Synth-pop 💎 EDM / Big room · 🌈 Dance pop · 🏴 Emo / Post-hardcore · 🌙 Chillwave / Dream pop 🎠 Baroque / Harpsichord · 🌺 Flamenco / Fado · 🎶 Smooth jazz · 🔮 Synthwave / Retrowave 🕺 Funk / Disco · 🌍 Afro-jazz · 🪗 Celtic / Folk-rock · 🌸 City pop / Vaporwave
and on top of that Pre defined scenes, that are always similar (seed varied) for more precise control
-
**57 environment presets — every scene has a world:**
🏛 Iconic Real-World Locations
🏰 Big Ben — Westminster at night · 🗽 Times Square — peak night · 🗼 Eiffel Tower — sparkling midnight · 🌉 Golden Gate — fog morning
🛕 Angkor Wat — golden hour · 🎠 Versailles — Hall of Mirrors · 🌆 Tokyo Shibuya crossing — night · 🌅 Santorini — caldera dawn
🌋 Iceland — black sand beach · 🌃 Seoul — Han River bridge night · 🎬 Hollywood Walk of Fame · 🌊 Amalfi Coast — cliff road
🏯 Japanese shrine — early morning · 🌁 San Francisco — Lombard Street night
🎤 Performance & Event Spaces
🎤 K-pop arena — full concert · 🎤 K-pop stage — rehearsal · 🎻 Vienna opera house — empty stage · 🎪 Coachella — sunset set
🏟 Empty stadium — floodlit night · 🎹 Jazz club — late night · 🎷 Speakeasy — basement jazz club
🌿 Natural & Remote
🏖 Beach — golden hour · 🏔 Mountain peak — dawn · 🌲 Dense forest — diffused green · 🌊 Underwater — shallow reef
🏜 Desert — midday heat · 🌌 Night sky — open field · 🏔 Snowfield — high altitude · 🌿 Amazon — jungle interior
🏖 Maldives overwater bungalow · 🛁 Japanese onsen — mountain hot spring
🏙 Urban & Interior
🏛 Grand library — vaulted reading room · 🚂 Train — moving through night · ✈ Plane cockpit — cruising · 🚇 NYC subway — 3am
🏬 Tokyo convenience store — 3am · 🌧 Rain-soaked city street — night · 🌁 Rooftop — city at night · 🧊 Ice hotel — Lapland
💊 Underground club — strobes · 🏠 Bedroom — warm evening · 🪟 Penthouse — floor-to-ceiling glass · 🚗 Car — moving at night
🏢 Office — after hours · 🛏 Hotel room — anonymous · 🏋 Private gym — mirrored walls
🔞 Adults-only
🛋 Casting couch · 🪑 Private dungeon — red light · 🏨 Penthouse suite — mirrored ceiling · 🏊 Private pool — after midnight
🎥 Adult film set · 🚗 Back seat — parked at night · 🪟 Voyeur — lit window · 🌃 Rooftop pool — Las Vegas strip
🌿 Secluded forest clearing · 🛸 Rooftop — Tokyo neon rainThere's Way too much to explain.
Description
Supports I2v
FAQ
Comments (17)
Nice fast update, but I get an error when trying to run the vision node, can't connect to huggingface, I tried both models in online mode.
Thanks for the new 1.5 Update. 1.0 was working very well. With the new 1.5 update i can't find the LTX2VisionDescribe node you have used in the I2V workflow example. Do you have a github reference?
Great job!
As a suggestion that could further simplify video generation, could you add a definition of which LoRa should be added to a video, based on the LLM model's automatic analysis of the prompt? If that's possible, of course.
Thanks for the update Lora-Daddy! Another banger. I will be pushing a PR to you soon as I have created some new features to both your LoRA Stack and the LTX-2 Prompting Node.
if it uses neural daredevil, can't we just download the gguf versiin manually and put it there? why do ee need to make it download the full version automatically?
Big thanks for sharing your workflow and custom nodes with the community. It honestly makes things so much smoother for anyone working on LTX2 (or other ai models) videos, and that kind of effort doesn’t go unnoticed.
And the same goes for all the other awesome contributors out there, the LoRA creators, the UNet and checkpoint builders, and everyone else putting in the time to make tools, models, and resources for the rest of us. A lot of what we’re able to do is because of the work you all choose to share.
Really appreciate all of you helping push things forward.
excited to check it out, im getting "[VisionDescribe] Missing: qwen-vl-utils. Fix: pip install qwen-vl-utils then restart ComfyUI." I didnt see any mention of needing to do this in your instructions tho.
I've tried both Online and offline mode, running on a 16GB Vram video card and 96gb RAM. Running the 8B Neural Daredevil model. It took 5 minutes for the prompt, 10 times longer than the LTX model to create the video itself. Something is wrong
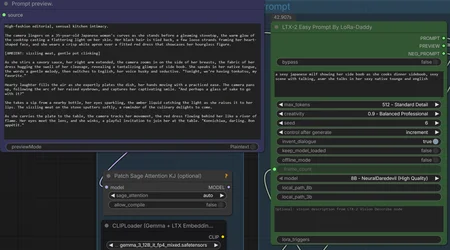
For the T2V flow I think I've done everything correctly, but on the LTX-2 Easy Prompt node I get an error about the creativity 512 Standard Detail.
In the dropdown I look to have options for 0.7, 0.9, 1.1. If I select one of those, I then get:
Finally got this working with the assets on the reddit link in the previous comment ... https://www.reddit.com/r/StableDiffusion/comments/1r8wdd4/final_release_ltx2_easy_prompt_vision_two_free/
Did the 18 second city scene in the provided t2v workflow with a 5060ti, 16GB VRAM, 48GB RAM in 32 minutes. Will probably be faster with local prompt gen (llama) model. I'm still impressed with the generated prompt and video quality as well as the ability to actually complete the 18 seconds.
im getting this when trying to download the llm. also model not downmloading at all even setting to offline i get this error.
LTX2PromptArchitect
Repo id must use alphanumeric chars or '-', '_', '.', '--' and '..' are forbidden, '-' and '.' cannot start or end the name, max length is 96: '8B - NeuralDaredevil (High Quality)'.
Prompt execution failed
Prompt outputs failed validation: CLIPTextEncode: - Return type mismatch between linked nodes: text, received_type(INT) mismatch input_type(STRING) LTX2PromptArchitect: - Value not in list: max_tokens: 'Busy city st night. cinematic ' not in ['256 - Short & Tight', '512 - Standard Detail', '800 - High Density', '1024 - Maximum Narrative Detail']
This looks great, love the prompt builder. I have a 5090 and 128G RAM, I have all the models, and nodes, but I get this issue:
!!! Exception during processing !!! Error(s) in loading state_dict for TAEHV:
size mismatch for encoder.0.weight: copying a param with shape torch.Size([64, 48, 3, 3]) from checkpoint, the shape in current model is torch.Size([64, 3, 3, 3]).
... it continues for a while after that... then
RuntimeError: Error(s) in loading state_dict for TAEHV:
size mismatch for encoder.0.weight: copying a param with shape torch.Size([64, 48, 3, 3]) from checkpoint, the shape in current model is torch.Size([64, 3, 3, 3]).
Any idea what I could change to make this work?
AINT NO WAY IN HELL YOU THE OWL MAN FROM sd REDDIT xD
I`m getting this error ValueError: [GetNode] ✗ Variable 'Preview' not found!
Available: frames, vae, width, vae_audio, height, upscale_model
Tip: Make sure SetNode runs BEFORE GetNode in the graph.
This is perfect, that mute lora loader is genius, that was causing all kinds of issues for me before, this fixes a lot of issues with LTX. ty!
Error : SamplerCustomAdvanced 'Linear' object has no attribute 'weight' Need help please
dont wok