Version 1
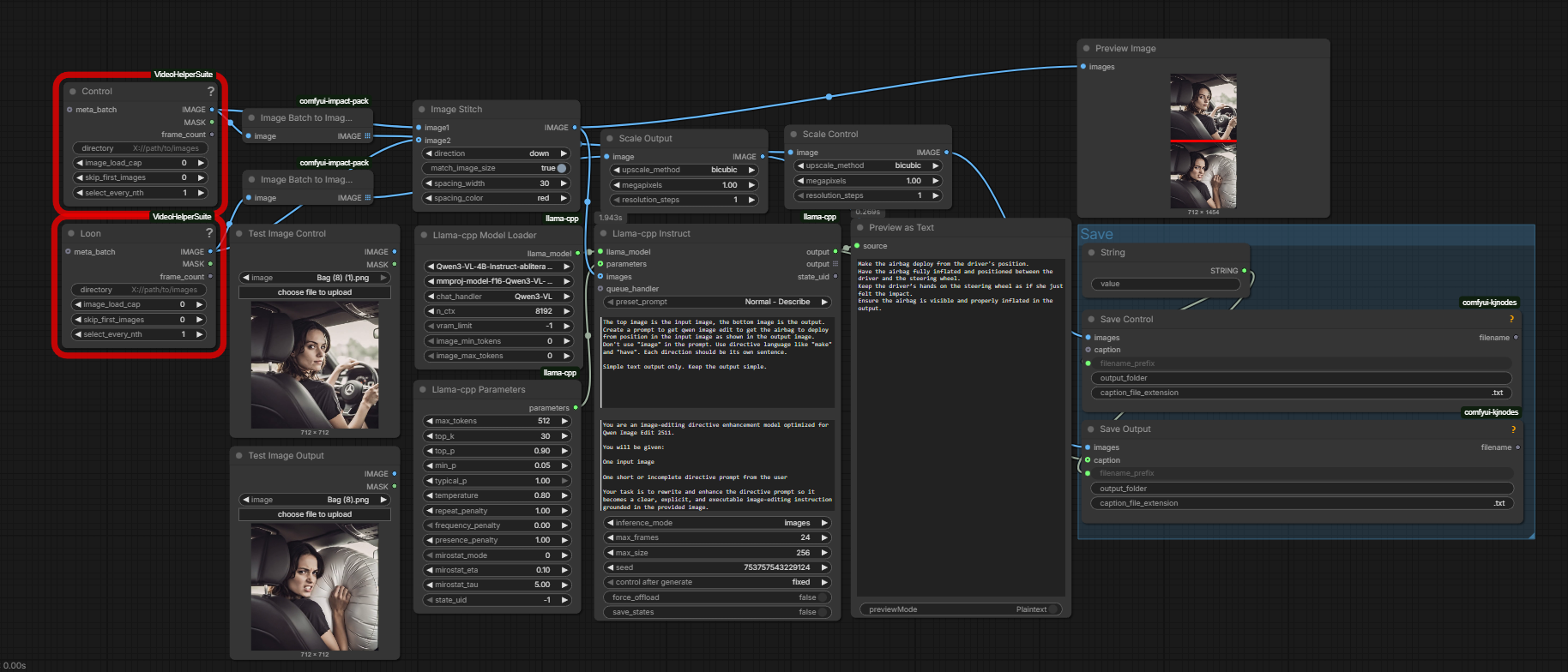
Pretty straight forward if you've ever done lora training before. You do want to prep your dataset ahead of time. It's a tad inefficient that it will save your control and training images again. Saving the control images again is probably not necessary but I did it anyway to be safe.
What it does is stitch your control and training images together. The Llama-CPP prompt is calibrated so that it will recognize the top stitched image as the control. You'll want to adjust the following section to your needs:
Create a prompt to get qwen image edit to get {Subject of} the input Image to preform the {action} with the {Object} as shown in the output image. Don't use "image" in the prompt.You can pretty mage change that to whatever you feel you need, though still does work as is.
You will need LLama CPP to make this work