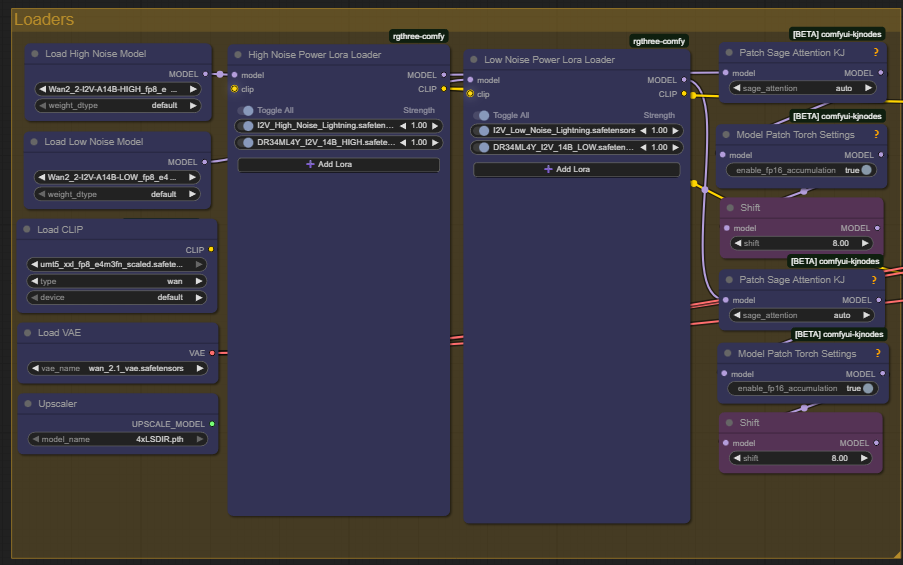
Wan 2.2 I2V workflows that allow longer video generation by passing the last frame of one video as the input into the next. It then combines the videos at the end.
Includes Lora loader node, SageAttn node, FP16 accumulation node in addition to the standard I2V nodes.
If you can run the default Wan workflow, you should be able to run this as well. I noticed minimal, if any, additional overhead using this method.
As with any extended video, context drift is possible. This workflow is best suited for actions where major changes to the scene aren't prompted.
Description
FAQ
Comments (8)
It Works!
Thank you for hooking the Sage attention and Torch nodes so I don’t have to lol. Do you have plans to expand this workflow, maybe with an optional interpolation section? 👍
Yes. I considered adding interpolation, but was worried about it being computationally heavy. I will add it in V2 as an option. :)
I've added the requested interpolation to V2 of the workflow!
@ChillDesire Thanks! I also love the new toggle that lets you switch between different durations in a single workflow
An excellent and quick workflow, with an interesting idea for key pictures. I would really like to see the workflow for a 1 minute video :) Thanx!
I would like to say thank you again for the wonderful workflow :) And, if the author doesn't mind, I would like to suggest a few improvements for the new version. Add the "Keep ratio and resize picture" node. And as well as the "prompt" node to each section. Then it will be possible to change the video as you go :)
Thank you for the feedback! I've added the seperate prompts in V2. Some user feedback suggests there may be an intermittent issue with it, so I'm planning a V2.1 to hopefully address that.
I'm not familiar with the node you mentioned, but I did add the option for resolution in the workflow so you don't have to change multiple nodes to match the resolution you need.