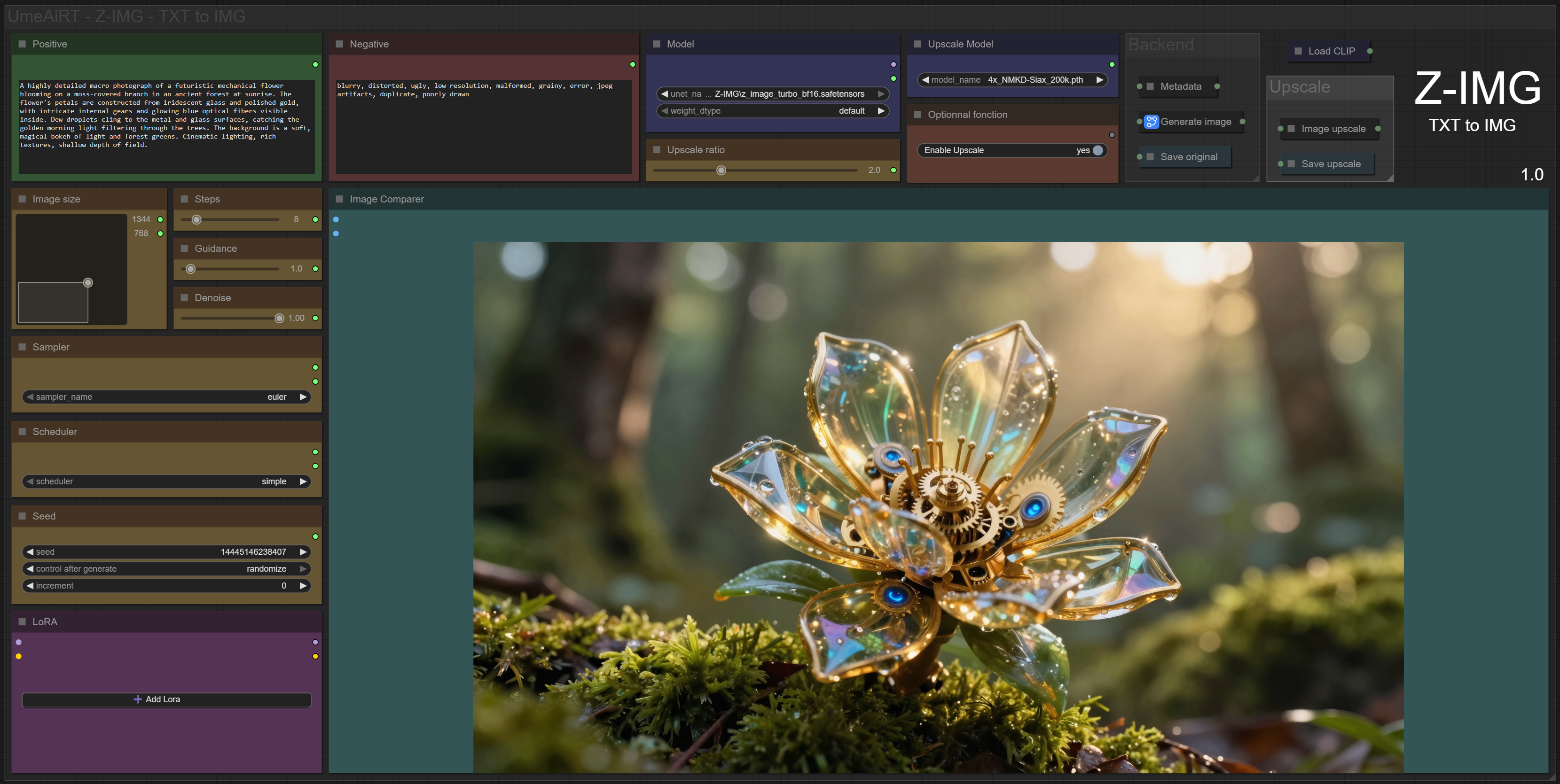

✨ Z-IMG — Text to Image — Simple Workflow
A clean, all-in-one Z-IMG text-to-image workflow built entirely with the UmeAiRT Toolkit for ComfyUI.
Only 8 nodes. No spaghetti wires. Just load your model, write your prompt, and hit generate.
⚠️ IMPORTANT — Nodes 2.0 Required
This workflow is built for the Nodes 2.0 (Vue) interface of ComfyUI. If you don't enable it, the workflow may have display problems.
How to activate Nodes 2.0:
Open ComfyUI
Go to Settings (⚙️ icon, bottom-left)
Find "Use Nodes V2 (Vue)" and toggle it ON
Refresh the page
Load the workflow
If you prefer the classic interface, check out my Legacy version of this workflow instead (link).
🎯 Features
Text-to-Image generation
Automatic download of models in auto version
Lighning LoRA included
Detail Refiner sampler
Built-in SeedVR2 upscaler — high-quality tiled upscaling (toggleable on/off) Slower than a classic upscaler, but significantly better quality
Full metadata embedding — your images are saved with all generation parameters, ready for online publishing and remixing
3 LoRA slots — with individual on/off toggles and strength control and you can connect as many other lora modules to each other for as many LoRA as you want.
📦 Custom Node Required
Only one custom node to install:
Install via ComfyUI Manager (search "UmeAiRT") or use the UmeAiRT Auto-Installer.
The Toolkit packages everything internally — upscaler, face detailer, metadata saver. No other custom nodes needed.
📂 Files you need (in manual version)
📂for "base" version :
Model : z_image_turbo_bf16.safetensors
in ComfyUI\models\diffusion_models
CLIP : qwen_3_4b.safetensors
in ComfyUI\models\clip
📂for GGUF version :
Model : Q8, Q6, Q5, Q4, Q3
in ComfyUI\models\unet
CLIP : Q6
in ComfyUI\models\clip
📂Common
VAE : ae.safetensors
in ComfyUI\models\vae
Description
base version
FAQ
Comments (5)
Please excuse my incompetence, I'm a newbie in these matters, but why does this appear? : got prompt
Using pytorch attention in VAE
Using pytorch attention in VAE
VAE load device: cuda:0, offload device: cpu, dtype: torch.bfloat16
CLIP/text encoder model load device: cuda:0, offload device: cpu, current: cpu, dtype: torch.float16
Requested to load ZImageTEModel_
loaded completely; 9825.80 MB usable, 7672.25 MB loaded, full load: True
model weight dtype torch.bfloat16, manual cast: None
model_type FLOW
unet missing: ['norm_final.weight']
lora key not loaded: diffusion_model.layers.0.attention.to_k.lora_A.weight
lora key not loaded: diffusion_model.layers.0.attention.to_k.lora_B.weight
lora key not loaded: diffusion_model.layers.0.attention.to_out.0.lora_A.weight
lora key not loaded: diffusion_model.layers.0.attention.to_out.0.lora_B.weight
lora key not loaded: diffusion_model.layers.0.attention.to_q.lora_A.weight
lora key not loaded: diffusion_model.layers.0.attention.to_q.lora_B.weight
lora key not loaded: diffusion_model.layers.0.attention.to_v.lora_A.weight
lora key not loaded: diffusion_model.layers.0.attention.to_v.lora_B.weight
At the same time, LoRA seems to produce results.
This type of message is generally linked to the use of a LoRA of another model (like FLUX), which can create incompatibilities. Which LoRa did you try?
https://civitai.com/models/2143365/moebius-desert-b-style
https://civitai.com/models/1416327?modelVersionId=2483879
e.t.c. for each one it is written Base Model ZImageTurbo
But now I've discovered that this occurs with any ZIT LoRAs in Comfy version 0.3.75. In version 0.3.76, this is no longer the case and everything works correctly.
@Cali_Gulla So it was ComfyUI that wasn't fully compatible, but this seems to fix it.
@UmeAiRT 👍👍👍