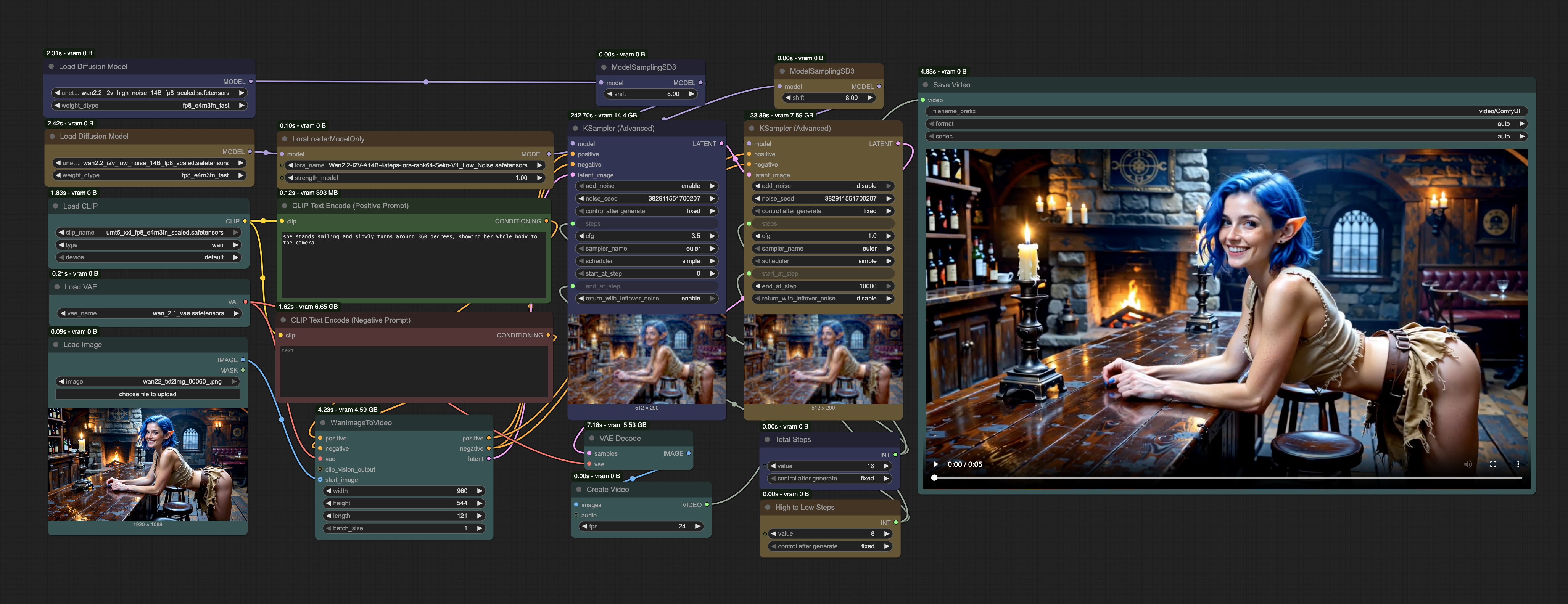

A super simple workflow for generating videos from images, with excellent prompt adherence and really solid quality!
The idea here is to keep it beginner-friendly, so no extra nodes are required.
How Wan 2.2 works:
High Noise: Handles the motion in the video. If your movement looks off, just increase the High Noise steps.
Low Noise: Takes care of the details (faces, hands, fine textures). If details look messy, increase the Low Noise steps.
In this example, I kept High Noise without a LoRA — it’s responsible for executing the core prompt. Adding a LoRA here often reduces prompt adherence, so it’s better to let it run slowly and keep things clean.
On the other hand, for Low Noise, I added a 4-step LoRA to speed up detail refinement. If you remove it, expect slower execution and the need for more steps to achieve good quality.
Downloads / Setup
LoRA: Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1_Low_Noise.safetensors
Wan 2.2 High Noise: wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors
Wan 2.2 Low Noise: wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors
Text Encoder: umt5_xxl_fp8_e4m3fn_scaled.safetensors
Previews
Workflow Screen: screenshot
Input Image: image
Sample Video: video
Description
FAQ
Comments (18)
Just saying this, in just this way..
Thank you! I often get just a little wiggle or a smeared bit and now I know what to tweak!
"High Noise: Handles the motion in the video. If your movement looks off, just increase the High Noise steps.
Low Noise: Takes care of the details (faces, hands, fine textures). If details look messy, increase the Low Noise steps."
On Blackwell, scaled fp8 models can cause a catastrophic collapse in quality. When ComfyUI boasted a massive performance boost on Blackwell recently, it was specifically referencing fp8 'optimisations'. But unless coders are skilled in numerical analysis (clue: the Comfy coders are not), pure fp8 accumulation can cause an unacceptable loss of precision as calculations accumulate.
I would advise Blackwell users to use GGUF models for main and LLM (clip). These seem to cause most of the maths to keep to fp16.
I would also point out the little know fact that pro-cards from Nvidia and AMD do proper maths accumulation with fp8/fp6/fp4, but the home GPUs do not.
"I would also point out the little know fact that pro-cards from Nvidia and AMD do proper maths accumulation with fp8/fp6/fp4, but the home GPUs do not."
Can you give us sources on where to find more info on this? First time ever hearing/reading this.
What about adding loras for doggystyle?
add sage attention ser
Hey friend, great workflow, but it took over an hour to generate. Is there a way to accelarate the generation?
Thanks! 🙌 Yeah, an hour is way too long — sounds like it’s running without GPU acceleration.
On my setup (RTX 5090) a full run takes just a few minutes.
Check if your ComfyUI is actually using the GPU (nvidia-smi while generating).
If it’s already on GPU, you can also speed it up by lowering the total steps and adding [SageAttention](https://github.com/thu-ml/SageAttention) which gives a nice boost. 🚀
Same here. The first(purple) KSampler (Advanced) node is taking horrendously long to go through on a 4090.
Hi, thanks for the workflow! Question - how to add Loras? Where should I put Lora nodes?
You see the LORA ONLY nodes come after the actual diffusion model nodes.
Clone that node type (lora/model only) and place them in series with the respective HI/LO lightspeed loras. Can post a screen cap if you need one.. I think lol..
@MollyAnne If you could post a screenshot, it would be much appreciated however from your explaination, I am assuming the loraLoaderModelOnly node is the one that needs to be cloned right? I would then go about putting a custom lora into that plug the previous lora node into it and plug the output from it into where the original was going.
If I want high range of motion, I'd clone for High noise, If I want low range of motion, i'd clone for low noise. Am I right????
@Artmagnet increasing passes on low noise cleans up the messes, generally, this is done by increasing total project passes on a 4 pass to 5, then changing the low passes to start at 2 and end at 5, for instance.
The lora placement is as simple as this, diffusion model/lora/everything else!
is this what you are asking?
@MollyAnne Not exactly no.... All I can see in the workflow are total steps. For high noice the value is set to 16 in its total step node. In its Ksampler it starts at step 0 but end step is greyed out. For Low noice its node is called High to low steps and the value is set at 8 by default. Its start step is grayed out but end step is at 10000. Where exactly do I change passes and how much time will higher passes require as compared to lower passes.
For the Lora it seems I am just supposed to copy paste lora nodes as I need.
@Artmagnet I made a couple screenshots but something is broken and I can't get them to upload right now..
Normally workflows cut the total passes 50/50, like 4 passes each for 8 pass total. High will start at 0 and go to 4, low at 4 and finish at 8..
If pass number is grey, double click the desktop in Comfy and select a copy of that sampler, input all the correct settings then connect to that sampler.. that might fix it?
Gabe, I have picked up many important tips from you. Thank you. You remember to describe the moments where you had epiphanies. That is the method of best teaching.
Thank you! The first workflow that made it possible to successfully run i2v on my PC.
I'm using your workflow and the model links. Using same values, the girl twirls 180 but then reverses back. Any idea why?
result is like plastic body, any tips?