

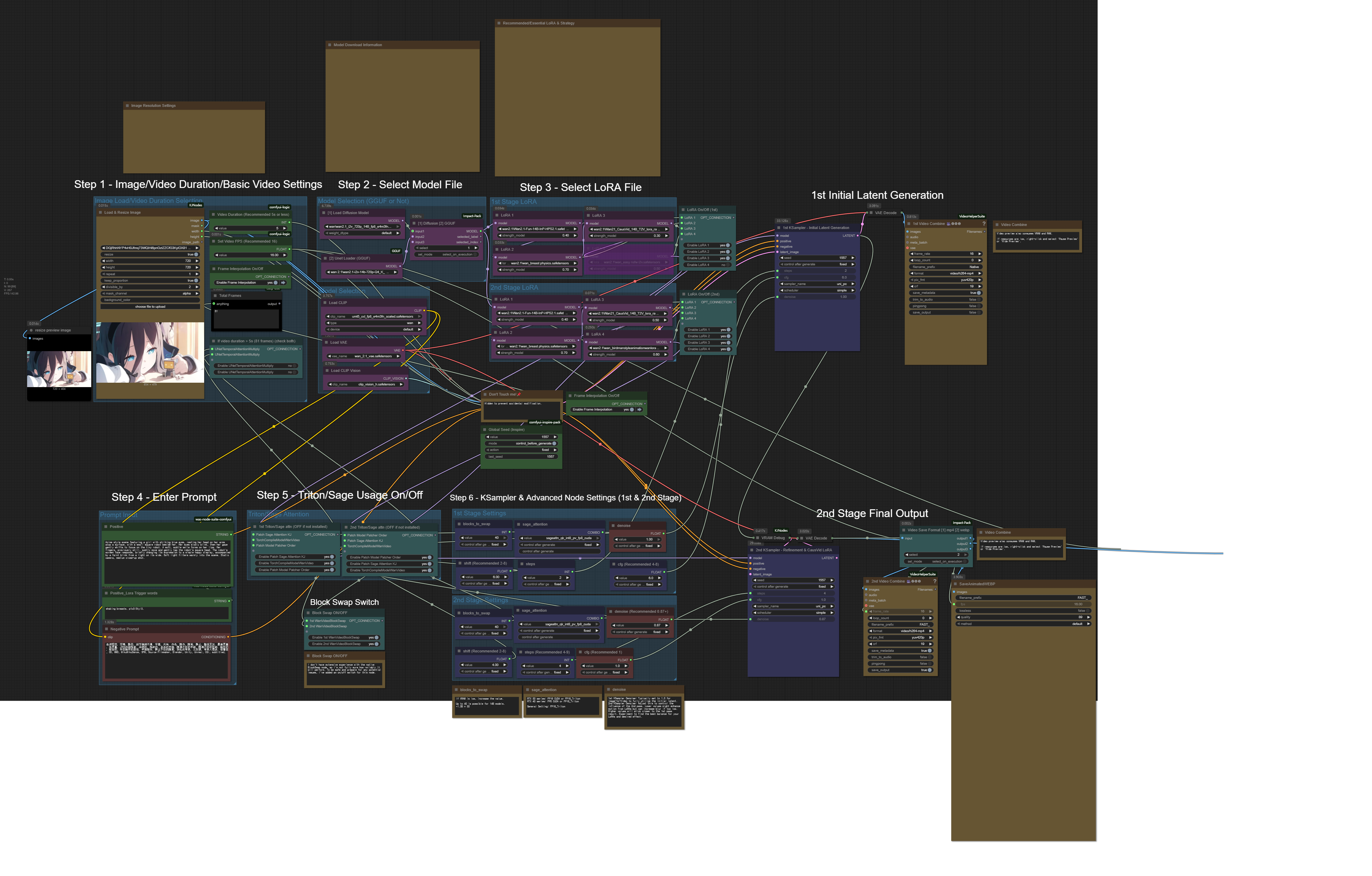
Sharing a ComfyUI workflow for image-to-video generation. This is an adapted and slightly modified version of a workflow originally created by an acquaintance.
It utilizes a two-pass KSampler system, focusing on LoRAs effective at low step counts, with a particular emphasis on CausVid for refinement.
Independent LoRA for Each Pass (User Customization):
Feature: You can apply separate sets of LoRAs to the 1st (initial generation) and 2nd (refinement) KSampler passes.
Advantage: This gives you granular control. For instance, use foundational LoRAs in the first pass and specialized motion/detail LoRAs (like CausVid) in the second, or experiment with completely different combinations as you see fit.
Addresses Common CausVid LoRA Challenges & Enhances Low-Step Performance:
Problem Solved: Directly tackles issues sometimes seen with CausVid LoRA (and other low-step focused LoRAs) where motion can be weak or artifacts appear when generating with very few steps in a single pass.
How it Improves:
The 1st pass quickly establishes a coherent base latent, even at minimal steps (e.g., 2-5).
The 2nd pass then leverages CausVid (and other LoRAs) on this pre-generated latent. This targeted refinement at low steps (e.g., 4-12, with CFG around 1.0) allows CausVid to perform optimally, enhancing motion and cleaning up potential issues more effectively than a single, rushed low-step generation.
Advantage: You get the speed benefits of low steps while mitigating common quality/motion degradation, leading to better, more consistent results with efficient LoRAs like CausVid.
This structured, two-stage process allows for more robust and refined outputs, especially when pushing for speed with very low step counts and relying on powerful efficiency LoRAs.
Custom Nodes
https://github.com/pythongosssss/ComfyUI-Custom-Scripts
https://github.com/ltdrdata/ComfyUI-Impact-Pack
https://github.com/yolain/ComfyUI-Easy-Use
https://github.com/WASasquatch/was-node-suite-comfyui
https://github.com/kijai/ComfyUI-KJNodes
https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite
https://github.com/Fannovel16/ComfyUI-Frame-Interpolation
https://github.com/ltdrdata/ComfyUI-Inspire-Pack
Description
Initial release.
Key features: Two-pass low-step KSampling, optimized for CausVid LoRA, flexible model (Standard/GGUF) and LoRA configurations. See description for full details.
FAQ
Comments (22)
Very detailed instruction in the workflow, greatly appreciated!
I tried the 2-pass method and the quality is definitely better than only using 1 pass with Causvid!
May I know how long does it take for you to generate one video with causvid lora? I use 4090, step setting is 1st stage 2step and 2nd stage 6step. For a 30-60 frame video, it takes me about 1 mins for a 480P and 4-5 min for a 720P. Just want to know if this is average speed and wonder if there is any further speed boost possible.
Thanks for the positive feedback, glad you're finding the 2-pass method effective.
Regarding speed, your times seem reasonable. For comparison, on my 4090, an 81-frame 720p video (14B fp8 model) is roughly 1.5-2 minutes total.
A few things that could potentially offer a slight boost, if you're not already set up this way:
1. Launch Arguments: Consider adding --fast fp16_accumulation --use-sage-attention to your ComfyUI startup if you have Sage Attention compatible nodes/models. (need triton/sage attn, cuda nightly version)
2. BlockSwap Usage: If using BlockSwap for VRAM, often enabling it in just one of the two stages (either Stage 1 or Stage 2, depending on VRAM pressure) can be more performant than using it in both, unless you're hitting severe OOM issues.
@PEERLESS 720p 81 frame in 2 mins are very fast! Seems I need some more adjustments on the workflow......
Does the fast fp16_accumulation command has any downside on quality or other stuff?
By the way, do you think is possible to get the 1st pass in 480p and then upscale it to 720p then send to 2nd pass? Like the hires fix workflow. 1st pass in 480p could further increase the efficiency when picking the ideal generation!
@LovelaceA That's an excellent thought! I'll definitely look into designing a workflow variation for that.
It's a very clever way to potentially speed up finding a good initial generation. However, a couple of things I'd want to test carefully:
1. Latent Upscaling: Directly upscaling the latent data can sometimes be a bit problematic and might introduce artifacts if not done right.
2. Model Swapping Time: If it involves switching from a 480p model to a 720p model between passes, the time to unload and load models could eat into the speed savings, especially for shorter clips.
So, I'll run some tests on that approach to see how it balances out. It's a great suggestion for making the initial stage(stage 1) more efficient.
--fast fp16_accumulation
Theoretically, a tiny bit of precision can be lost. For most uses, it's visually unnoticeable, and the speed gain is often worth it. It's usually safe to try.
@PEERLESS @PEERLESS Thanks for the reply.
1. For the upscale part, I would prefer pixel upscale with upscaler, which makes more sense. Also no need to apply the 2 pass workflow on the 480p one since it just wont take that much time with Causvid.
2. Yeah swapping time could be an issue. However maybe the 480P clip can be generated with the 720P model? In that case no need for switch anymore. It is basically hires fix.
3. Sageattention is always enabled for me and I have the fast command on now, still 3-4 mins for a 720p video, like 2min for stage 1 and another 2 for stage 2. Anyway, It is definitely not bad :) . Hope to see more speed up stuff introcued in the future.
@LovelaceA Thanks for the detailed additional explanation. I'll refer to that to make improvements.
+If you're interested in 1-pass workflows(for only speed up) as well, you might want to check this workflow: https://i.imgur.com/W18ymLY.png
{kind=link}
@PEERLESS Thanks! Maybe I should further compare the quality difference between 1pass and 2pass, also need to check the effect of the HPS lora.
BTW, just wonder when you say 2 mins for a 720P video, do you mean 720x720 size video or 720x1280? I saw your sample image to be 1x1 and just realize in my case 16x9 of coz it can take longer
@LovelaceA 720x720(1:1)(5s, 81fps) = 1:40~2:10. XD
I've run some tests on your idea for improving the workflow by utilizing a 480p model.
To get straight to the results, unfortunately, I encountered some issues with this approach.
I tested several variations based on two main upscaling scenarios:
1. Upscaling the latent output from Stage 1 before it goes into Stage 2.
2. Upscaling the pixel image via VAE decode after Stage 2.
When upscaling the latent using a Latent upscale by (or similar direct latent upscaling) node:
-While this method can make the initial generation faster, the output quality was unfortunately poor. I observed significant blurring issues, making the results unusable.
When upscaling using a method that operates more like Latent upscale (on pixel space) or a similar pixel-based upscaling approach after VAE decode (or conceptually, upscaling the latent as if it were pixels):
-The output quality was noticeably better with this approach compared to direct latent upscaling.
However, the final quality wasn't superior to simply using a 720p model directly from the start for both stages. Crucially, the time required for this type of upscaling was excessively long, often negating much of the speed benefit gained from the 480p model
Sorry for the delayed reply; the testing took a considerable amount of time to explore these different paths thoroughly.
@PEERLESS Ah greatly appreaciated the efforts! Yeah after some experiments I have a feeling that video generation is different from image generation, and the hires fix concept is less applicable (or maybe there are other ways?). VAE decode encode in video generation is much more time consuming, plus the pixel upscale time. Together it should be around 1-2 mins.
I should test it myself. I dont think the hires fix should deliver a better result compared to 720p 1pass/2pass. The benefit should come from the shortened time to generate the first smaller video before 2nd pass, as it is more flexible to preview the clip before the 2nd pass. 720P 1pass 2pass will take 1-3 mins, if the 1st pass can be created within 1 mins, without much sacrifice on the final output quality, it may still worth some tries.
Anyway, thanks for the feedback!
Please export the workflow. What you released is a picture.
Just drag it into comfy
If you wish to test recreating the example video/image shown in the post, you can use the starting image provided within the zip file. The necessary prompt is already embedded in the workflow; simply load the workflow file into ComfyUI, and the prompt will be pre-filled in the appropriate text box. This is the actual prompt used for the example.
When I start the process, it goes smoothly all the way till the "1st Initial Latent Generation" then stops. I can't find a way to let the workflow continue to the 2nd stage final output
The issue might stem from blockswap or the updated Torch nodes (kjnodes).
As a test, please try using blockswap only in Stage 1, or revert to the v1.0 workflow (which uses older Torch nodes). I didn't observe this symptom during my tests, so these are potential areas to investigate.
I am seeing the same behavior as @Dbooya in the 1.1 file, no matter which blockswap settings are used. But the 1.0 file is working for me. I'm very interested in the concept, but haven't played with it much yet. Thanks for sharing this!
Just wanted to say that I'm also having these issues. But 1.0 is smooth! Just wanted an integrated upscale into 1.0 and I'm satisfied. Thanks for the great work!
All my widgets were closed and I couldn't use this workflow. It might be related to the version of comfyui.
I tried manually reopening the widgets and reconnecting the nodes but it didn't work.
Is there anything I can do?
This is the first time I've heard of this issue. Usually, if ComfyUI itself has a problem, running update_comfyui_and_python_dependencies.bat located in ComfyUI_windows_portable\update often resolves it.
I am experiencing the same issue, which was caused by not installing comfyui on the C drive of my local PC. Loading the workflow from the C drive resolved the issue. I hope this helps.
what's the NSFW lora you used that's loaded on the lora loaders?
https://civitai.com/models/1407357/easy-nsfw-wan21-i2v-480p?modelVersionId=1590896
However, personally, I highly recommend this LoRA. Although this LoRA appears to be specialized for furry, it's actually quite versatile.
https://civitai.com/models/1501763/furry-nsfw-wan-21-14b-img2vid-and-nsfw-motion-in-general