


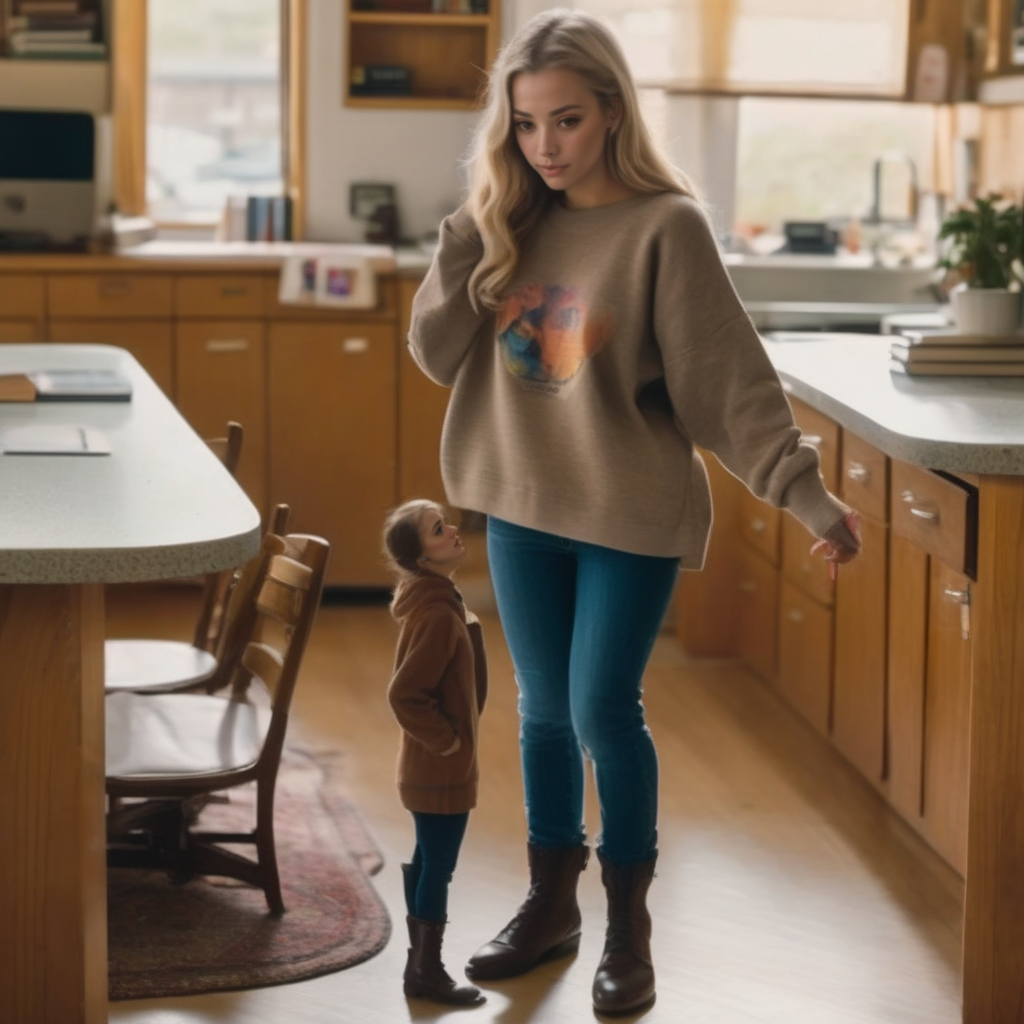








A Lycoris concept that attempts to skew perspective and prompt tiny people, show size difference and sense of scale. For PDXL best around ~0.75 strength, for realistic up to ~1.5 may be required for complex prompts. Best while using ADetailer to restore tiny faces.
Pony XL / SDXL V2:
See version details.
Better faces, re-trained with new trigger words.
More pose/couple focused, more flexible.
'tiny' -> top trigger word. WD14 also tagged things like 'minigirl' 'miniguy' so those may help assist.
'size difference' -> more likely to prompt a 2nd subject for comparison.
standing/sitting/laying on <object/surface> is more likely to prompt a shrunk perspective/scale, e.g.: 'standing on counter'
V1:
See version details
Still fairly unpredictable but output needs less img2img fixing
A Lora Locon that attempts to skew perspective and create shrunken people. Trained on 155 images, it works okay SD is pretty bad at faraway(small) people as subjects. Still, it worked out okay so here it is. Recommend generating then dropping the strength to ~0.3 for img2img cleanup and using ADetailer to fix faces. Also try putting the subject on a non-floor surface, like a table/counter/bed/chair.
Description
Trained using Kohya_ss
76 image dataset
5e-5 LR, 16 batch, 4 GA
FAQ
Comments (10)
is this suitable for realistic only?
It should work...at least as well as it does work, on checkpoints that are trained on/merged with SDXL. I posted some examples using Counterfeit XL for reference. I had to use Adetailer/img2img to restore the second subject.
I have used it with ZavyYumeXL, it works great for Cartoon style with that.
Try putting "2D" in you prompt and "3D" in you negative.
1.5 please, XL takes WAY to much time to make an image.
I'll give it a try as a Loha.
But it looks so much better. I much prefer to move on to new technology, so I appreciate the XL version. Thank you OP!
16 seconds with fooocus
At least with the way the dataset is auto-tagged currently, 1.5 training didn't pan out so well, I'll keep you posted. I'd have to echo the above that I really like where SDXL is headed and it has more details. You can always use img2img to inpaint 1.5 Loras/model styles.
I have slowdowns using SXDL (7s iteration in 1.5 and 12s in SDXL). It is however paid off by better images. The only problem is RAM consumation (16GB is not enough, I cannot load model into VRAM. I have 4GB.)