✨ WAN2.1 — Image to video — Simple Workflow
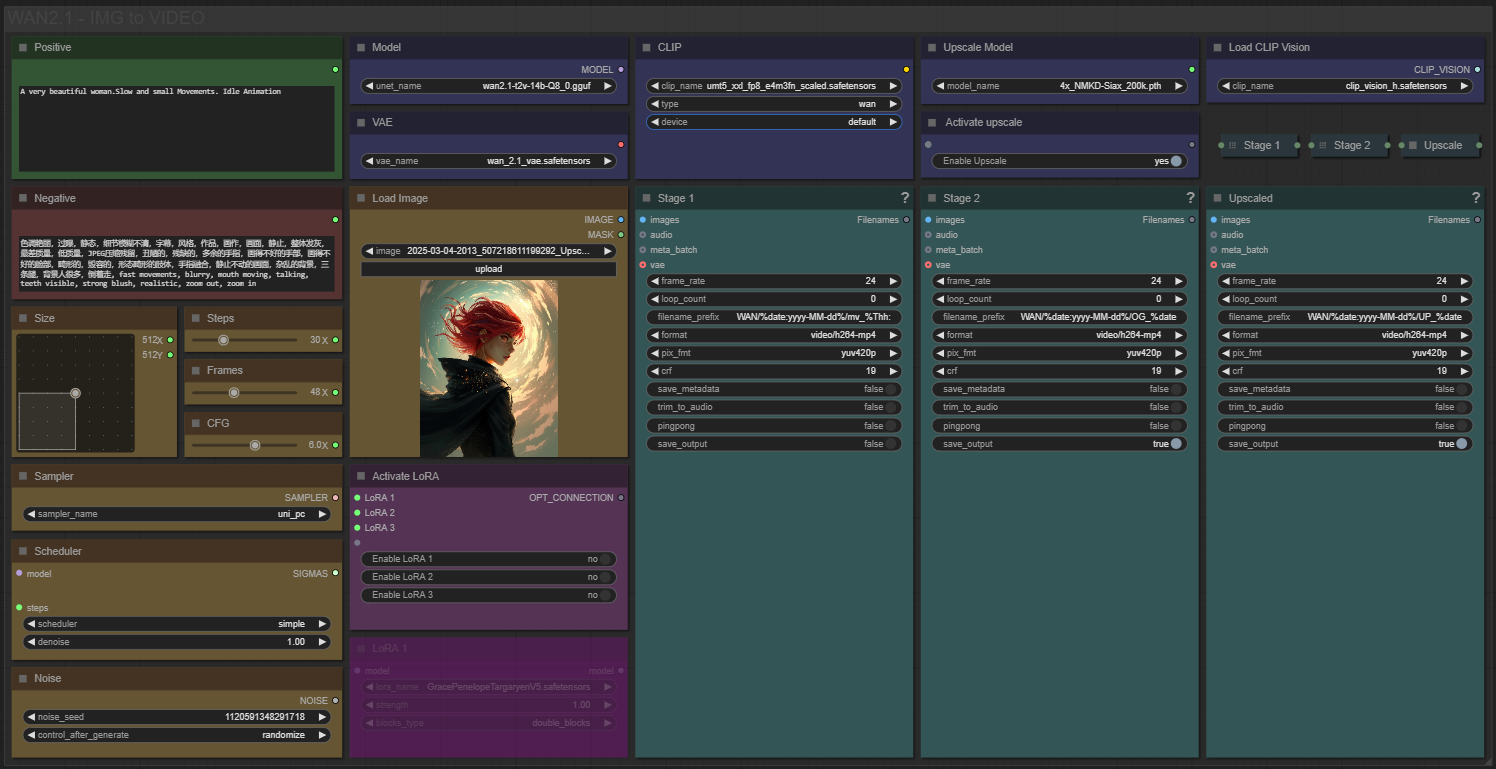
A clean, all-in-one WAN image-to-video workflow built entirely with the UmeAiRT Toolkit for ComfyUI.
Only 12 nodes. No spaghetti wires. Just load your model, write your prompt, and hit generate.
⚠️ IMPORTANT — Nodes 2.0 Required
This workflow is built for the Nodes 2.0 (Vue) interface of ComfyUI. If you don't enable it, the workflow may have display problems.
How to activate Nodes 2.0:
Open ComfyUI
Go to Settings (⚙️ icon, bottom-left)
Find "Use Nodes V2 (Vue)" and toggle it ON
Refresh the page
Load the workflow
If you prefer the classic interface, check out my Legacy version of this workflow instead (link).
🎯 Features
Text-to-video generation
Automatic download of models in auto version
Built-in SeedVR2 upscaler — high-quality tiled upscaling (toggleable on/off) Slower than a classic upscaler, but significantly better quality
Full metadata embedding — your images are saved with all generation parameters, ready for online publishing and remixing
3 LoRA slots — with individual on/off toggles and strength control and you can connect as many other lora modules to each other for as many LoRA as you want.
📦 Custom Node Required
Only one custom node to install:
Install via ComfyUI Manager (search "UmeAiRT") or use the UmeAiRT Auto-Installer.
The Toolkit packages everything internally — upscaler, face detailer, metadata saver. No other custom nodes needed.
📂 Files you need (in manual version)
For base version
I2V Model : 480p or 720p
In models/diffusion_models
For GGUF version
I2V Quant Model :
- 720p : Q8, Q5, Q3
- 480p : Q8, Q5, Q3
In models/unet
Common files :
CLIP: umt5_xxl_fp8_e4m3fn_scaled.safetensors
in models/clip
CLIP-VISION: clip_vision_h.safetensors
in models/clip_vision
VAE: wan_2.1_vae.safetensors
in models/vae
Speed LoRA: 480p, 720p
in models/loras
ANY upscale model:
Realistic : RealESRGAN_x4plus.pth
Anime : RealESRGAN_x4plus_anime_6B.pth
in models/upscale_models
Description
Add LoRA and Teacache support.
FAQ
Comments (16)
Finally one that looks simple but has all the things! Will try it out , is there a node type thing that could help , combining multiple short videos? i think i saw one around there
Missing Node Types
When loading the graph, the following node types were not found
workflowStage 2
workflowStage 1
I have this problem. And the positive and negative input text boxes are missing. I can probably figure that out, but I think I'll need a comment for the missing node type.
@croberts070268 You need to update ComfyUI and the additional nodes. Don't forget to close and reopen the workflow afterwards.
same, missing workflow stage 1, updated comfy and all nodes
@bitzupa Often this problem can be solved by uninstalling the custom nodes and reinstalling them, or directly by re-installing ComfyUI.
I forget to close and reopen, it works now
@UmeAiRT Thanks! I got everything working now. I was able to generate several high quality videos, but the motions go bonkers no matter which picture or lora used. Tried high and low CFG but no decent results yet. It's almost as if the lora isn't being used, and it is activated. I've tried most of the popular nsfw WAN loras with their example prompts. Any advice on what else I should tweak?
@croberts070268 Try
positive : Slow and small Movements. Idle Animation
negative : 色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走, fast movements, blurry, mouth moving, talking, teeth visible, strong blush, realistic, zoom out, zoom in
@croberts070268 I added a slider to version 1.3 to "shift" the model, the lower the value, the slower the animation will be
At step 2 it says INVALID ARGUMENT and stops generating
Decent workflow, not too cluttered, but for some reason it seems that Lora's don't apply as well. It sometimes altogether ignores them when in other workflows it would never.
I'm curious if this might have something to do with using the double blocks in the lora node or the fact that the second CFG (in the Stage 2 node) is set to 1. The first CFG in the mxtoolkit node is set to 6 though so I thought it wouldn't matter. What do you think?
@latemonde Have you try to set block_type to all? You can give me the lora for testing