
Please read our in-depth Guideline for prompting at Cagliostrolab Blog
Overview
Animagine XL 4.0, also stylized as Anim4gine, is the ultimate anime-themed finetuned SDXL model and the latest installment of Animagine XL series. Despite being a continuation, the model was retrained from Stable Diffusion XL 1.0 with a massive dataset of 8.4M diverse anime-style images from various sources with the knowledge cut-off of January 7th 2025 and finetuned for approximately 2650 GPU hours. Similar to the previous version, this model was trained using tag ordering method for the identity and style training.
With the release of Animagine XL 4.0 Opt (Optimized), the model has been further refined with an additional dataset, improving stability, anatomy accuracy, noise reduction, color saturation, and overall color accuracy. These enhancements make Animagine XL 4.0 Opt more consistent and visually appealing while maintaining the signature quality of the series.
Changelog
- 2025-02-13 – Added Animagine XL 4.0 Opt and Animagine XL 4.0 Zero
Better stability for more consistent outputs
Enhanced anatomy with more accurate proportions
Reduced noise and artifacts in generations
Fixed low saturation issues, resulting in richer colors
Improved color accuracy for more visually appealing results
- 2025-01-24 – Initial release
Model Details
Developed by: Cagliostro Research Lab
Model type: Diffusion-based text-to-image generative model
License: CreativeML Open RAIL++-M
Model Description: This is a model that can be used to generate and modify specifically anime-themed images based on text prompt
Fine-tuned from: Stable Diffusion XL 1.0
Usage Guidelines
The summary can be seen in the image for the prompt guideline.

1. Prompt Structure
The model was trained with tag-based captions and the tag-ordering method. Use this structured template:
1girl/1boy/1other, character name, from which series, rating, everything else in any order and end with quality enhancement
2. Quality Enhancement Tags
Add these tags at the end of your prompt:
masterpiece, high score, great score, absurdres
3. Recommended Negative Prompt
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
4. Optimal Settings
CFG Scale: 4-7 (5 Recommended)
Sampling Steps: 25-28 (28 Recommended)
Preferred Sampler: Euler Ancestral (Euler a)
5. Recommended Resolutions
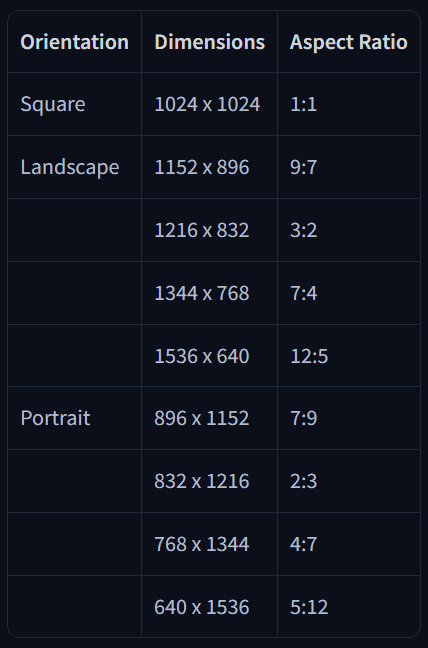
6. Final Prompt Structure Example
1girl, firefly \(honkai: star rail\), honkai \(series\), honkai: star rail, safe, casual, solo, looking at viewer, outdoors, smile, reaching towards viewer, night, masterpiece, high score, great score, absurdres
Special Tags
The model supports various special tags that can be used to control different aspects of the image generation process. These tags are carefully weighted and tested to provide consistent results across different prompts.
Quality Tags
Quality tags are fundamental controls that directly influence the overall image quality and detail level. Available quality tags:
masterpiecebest qualitylow qualityworst quality
Score Tags
Score tags provide a more nuanced control over image quality compared to basic quality tags. They have a stronger impact on steering output quality in this model. Available score tags:
high scoregreat scoregood scoreaverage scorebad scorelow score
Temporal Tags
Temporal tags allow you to influence the artistic style based on specific time periods or years. This can be useful for generating images with era-specific artistic characteristics. Supported year tags:
year 2005year {n}year 2025
Rating Tags
Rating tags help control the content safety level of generated images. These tags should be used responsibly and in accordance with applicable laws and platform policies. Supported ratings:
safesensitivensfwexplicit
Training Information
The model was trained using state-of-the-art hardware and optimized hyperparameters to ensure the highest quality output. Below are the detailed technical specifications and parameters used during the training process:

Acknowledgement
This long-term project would not have been possible without the groundbreaking work, innovative contributions, and comprehensive documentation provided by Stability AI, Novel AI, and Waifu Diffusion Team. We are especially grateful for the kickstarter grant from Main that enabled us to progress beyond V2. For this iteration, we would like to express our sincere gratitude to everyone in the community for their continuous support, particularly:
Moescape AI: Our invaluable collaboration partner in model distribution and testing
Lesser Rabbit: For providing essential computing and research grants
Kohya SS: For developing the comprehensive open-source training framework
discus0434: For creating the industry-leading open-source Aesthetic Predictor 2.5
Early testers: For their dedication in providing critical feedback and thorough quality assurance
Contributors
We extend our heartfelt appreciation to our dedicated team members who have contributed significantly to this project, including but not limited to:
Model
Gradio
Relations, finance, and quality assurance
Data
Fundraising Are Now Open Again!
We're excited to introduce new fundraising methods through GitHub Sponsors to support training, research, and model development. Your support helps us push the boundaries of what's possible with AI.
You can help us with:
Donate: Contribute via ETH or USDT to the address below.
Share: Spread the word about our models and share your creations!
Feedback: Let us know how we can improve.
Donation Address:
ETH/USDT/USDC(e): 0xd8A1dA94BA7E6feCe8CfEacc1327f498fCcBFC0C
Github Sponsor: https://github.com/sponsors/cagliostrolab/
Why do we use Cryptocurrency?:
When we initially opened fundraising through Ko-fi and using PayPal as withdrawal methods, our PayPal account was flagged and eventually banned, despite our efforts to explain the purpose of our project. Unfortunately, this forced us to refund all donations and left us without a reliable way to receive support. To avoid such issues and ensure transparency, we have now switched to cryptocurrency as the way to raise the fund.
Want to Donate in Non-Crypto Currency?
Although we had a bad experience with Paypal, and you’d like to support us but prefer not to use cryptocurrency, feel free to contact us via Discord Server for alternative donation methods.
Join Our Discord Server
Feel free to join our discord server: https://discord.gg/cqh9tZgbGc
Limitations
Prompt Format: Limited to tag-based text prompts; natural language input may not be effective
Anatomy: May struggle with complex anatomical details, particularly hand poses and finger counting
Text Generation: Text rendering in images is currently not supported and not recommended
New Characters: Recent characters may have lower accuracy due to limited training data availability
Multiple Characters: Scenes with multiple characters may require careful prompt engineering
Resolution: Higher resolutions (e.g., 1536x1536) may show degradation as training used original SDXL resolution
Style Consistency: May require specific style tags as training focused more on identity preservation than style consistency
License
This model adopts the original CreativeML Open RAIL++-M License from Stability AI without any modifications or additional restrictions. The license terms remain exactly as specified in the original SDXL license, which includes:
✅ Permitted: Commercial use, modifications, distributions, private use
❌ Prohibited: Illegal activities, harmful content generation, discrimination, exploitation
⚠️ Requirements: Include license copy, state changes, preserve notices
📝 Warranty: Provided "AS IS" without warranties
Please refer to the original SDXL license for the complete and authoritative terms and conditions.
Description
Animagine XL 4.0 Zero serves as the pretrained base model, making it an ideal foundation for LoRA training and further finetuning.
FAQ
Comments (107)
Great to see that work is still being done on this model!
Thank you CagliostroLab for continuing to show the community how a model release should be done.
This release is very clear with no conflicting licenses which you would think would be the bare minimum but alas, no. There is also very good documentation of the model available at launch!
I hope our community takes note of what Cagliostro is doing. Many other outfits in our community have tried various things in efforts to extract money while Cagliostro does the right thing and releases their model for free and under reasonable conditions. There's a ko-fi link on their profile and compute is not free. CagliostroLabs deserves to recoup their training costs so they can continue to use their compute to benefit us!!
This might sound like I'm affiliated. I'm really not. I'm just so frustrated with how other models have been released lately that this release is a breath of fresh air. Thank you.
still censored?
Never was.
Never was, in my tests it was just burned.
@Konoko imma stick with noob, it looks more ai than ai for me lol
@EBIX I can't negate that. Still noob is the best, but illust creators are getting crazy and changing their TOS and other things. Don't surprise if later they do something strange for limit or control the illust derivated models. Imo Ani4 comes in the best possible moment.
@sadicwin32300 For legal reasons, the only thing I can say is, we're trying to showcase what the model can do without making sponsors go away.
im gonna coooooom
when on site generation so i can do proper tests?
Civitai just allowed v4 Opt on the generator! But sadly we must lose v4.0 (legacy) on the generator.
@kayfahaarukku if V4 Opt is an upgrade then V4.0 legacy won't be a problem i guess
Oh, the heavenly model 🤲
I'm so happy you listened to the community when they had constructive criticism on the initial v4. This model is incredible. Thanks so much for your hard work!
The opt/zero version cannot get the sharpening or the colors of the 1st version, but is truthly better. Now it don't gets crazy with non portrait gens. Maybe I could prefer the zero version for make fine-tuning, but I have the question.
The zero version lacks in something? Like missing characters or styles? Thank you so much for your hard work!
i guess opt was finetuned on AI generated images to enhance the style, zero was finetuned on an additional better dataset.
v4 -> zero -> opt
Zero is for training. Opt is for inference, since it's been finetuned for better aesthetics. The knowledge of both models should be the same.
Thanks both
Hi, dev here.
Zero is an untuned version, this is the very "basic and straight forward" state of the model. We recommend this for training, either LoRAs or a new base model.
v4.0 and v4.0-Opt is a tuned version, like what @bubbletea03 said, it is recommended for inference.
It's much cleaner now. Definitely better for general use. Somehow I really miss the style of v4.0, although little bit messy, but very unique, colorful and artistic. No other model can do that.
A huge improvement in consistency and anatomy now. I really like this version! I can't say a lot on styles, I need to do more testing on those, but in characters database, it has a lot of new characters, which is awesome!
But I do notice that it lacks knowledge on old characters that NoobAI has, maybe it's because it also uses E621 in their database, so rarer cartoon or series are in the database if you prompt it correctly.
I did notice it tends to whitewash some black characters every now and then, not sure if it's because of the way I prompt it or I need to add "dark skin" every time. Either way, small gripe that can be fixed with more descriptive prompting.
Either way, I hope this keeps getting updated, I can definitely see this model surpassing NoobAI in knowledge of styles and characters. I just need to do more testing to know if it already surpassed it or not.
This model is so amazing and I am excited every day. However, I wonder if a list that was in 3.1 would allow for a wider range of expression, do you have plans to create a list? Sorry for being so busy.
Hi, we're not making a list this time. It's because it's hard to cover list of around 8.4M images.
If you're using A1111 Webui/reForge, there's an awesome extension called "booru tag autocomplete". It will mostly cover the tags available with the model.
https://github.com/DominikDoom/a1111-sd-webui-tagcomplete.git
@kayfahaarukku Thank you. This is just a great help. Keep up the good work.
The art style of this model is great, but I have a question in use, how to generate the art style of this model stably? Because sometimes/very rarely, there will be a very old style of painting, like printmaking, but the colors are very bright, like lasers. How can I avoid this?
Here is the parameter:
```
masterpiece, high score, great score, absurdres,
(nsfw:1.3),
(1girl:1.4),
higuchi madoka, idolmaster,
(light-blue theme:1.1) | white theme,
(cheongsam:1.2), side-tie panties | himopan,
pussy juice,
facing viewer, look at viewer, spread legs,
indoors, gaming chair,
navel, covered navel,
<lora:covered navel XL-v1:0.8>,
Negative prompt: lowres, bad anatomy, (bad hands:1.1), text, error,
missing finger, extra digits, fewer digits, (extra fingers:1.3),
cropped, worst quality, low quality, low score,
bad score, average score, signature, watermark,
username, blurry,
Steps: 25, Sampler: Euler a, Schedule type: Automatic, CFG scale: 6, Seed: 3985944291, Size: 832x1216, Model hash: 1d5b43ff75, Model: animagineXL40_v40, Clip skip: 2, ENSD: 31337, Lora hashes: "covered navel XL-v1: 980456a41be0", Discard penultimate sigma: True, Version: v1.10.1
```
Please, read our prompting guideline.
It's in the description for the short version, and at our blog for the in-depth version.
@kayfahaarukku Ok, maybe it's because my quality tag is misplaced, thanks for the reply
AnimaGen redemption arc is here? this model defintly blow v3 out of the water, and in my opinion way batter than illust, noob and all vpred models. finally there is new model to play with. hopefully we see good finetunes of it. espically a fine tune with batter hands becouse the hands is a little embarrassingly bad with this model.
can i now latest animagine 4.0 is running on epsilon prediction method or v prediction method?
can i use resolution of 1360x1024?? so far this resolution have working fine for me in any model
In general, yes. https://civitai.com/images/58087090
But it might break some generations.
So at this stage, can we call Animagine a standalone variation model like Illustrious and Pony?
It always has been since v1.0, we have never trained the model on top of other community models. We don’t like and have never liked the idea of having a different category because it is literally just a fine-tune of SDXL 1.0, nothing more. It would be a different case if we had modified the architecture but we don't. We want to respect Stability AI and the team that built SDXL 1.0 from scratch.
After some testing, I think I like the regular 4.0 more than the optimized version.
It requires a bit more inpainting to fix anatomy issues, but it seems to be a lot more creative in terms of composition.
Ive been testing 4.0Opt for some hours, and i like the level of creativity in term of compositions that can create. But in my personal experience so far it has severe problems in terms of anatomy, even using the proper prompt it seems to struggle a lot. I still like it and it has potential, but the anatomy its the biggest issue so far.
I recommend ppl to try adding it with a hand LoRa, and using these quality tags:
Positive Prompt (attach to end):
(best quality:0.7),
(highres:0.95), (anti-alias:0.6)
Negative prompt (Attach to end):
worst quality, bad score, low score,
bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits,
logo, text,
(blurry:0.05),
This way you get less of a erotic girl bias, and instead just get a sharp picture of whatever you are trying to prompt. If you don't trust me, try comparing best quality:0.7 to masterpiece alone.
I've had issues making Pony and Illustrous LoRas work with it well, but it does work without burning.
I like this model. It is pretty creative, while also sticking to my prompt. Some tags are less developed, but if ppl build on it then it should work fine.
which hand lora?
@PertaliteMeister I was about to ask the same.
@PertaliteMeister Sorry Civit makes it hard to see comments, I used this one https://civitai.com/models/278497/hand-fine-tuning
Is the a file that states which artist this model supports?
Just use everything from Danbooru from 2005 to starting 2025 I guess dont expect too much with artist with few pics but you can try anyway.
are 3.1 loras compatible with animaginexl 4.0?
They are, is not like Illustrious or Pony, the only difference is that this one was trained on top of SDXL instead of on top of 3.1
Overall maintains the unique Animagine 3 art style while reducing artifacts.
Opt improves on 4 with better coloring and less weirdness/asymmetry, but seems to suffer from a bit of catastrophic forgetting with skin tones and expressions. I had to crank up the strength of "tan" to make my dark elf look like a dark elf. Facial expressions also swing between extremes.
amazing model, on par with illust and noob imo
Found this on Dreamerland. Can this model be used for commercial purposes?
Hi, we've put the details about the license we're using at the very bottom of the model description and the summary of the license.
As far as I'm aware, you can use the model for commercial purposes. But if you're unsure, you can read the license by yourself.
animaging我的超人!最喜欢的低模没有之一!!!
Any new character list?
When do I use which version? Zero for training with kohya_ss and opt for generation with sd?
I am really impressed, first coment after more than a year around here, my congratulations, keep like this guys, my first tips for you <3
can i use illustrious and pony loras with this?
much better!
Love this model !!! Creative, Polished, Detailed, Glossy finish, !!!_______________________________________
As much as i like your aproach and skills to training, i dont think v4opt can match v3.1 tbh, yes it is an improvement but you need to reckon v3.1 is just topnotch !!!
Thank you for the Prompt Guide, it really makes a difference !!! prompt sections can be used as a template and you only change the main tags, cool approach !!! Thank you again !!!
cameras angles are awesome !!!
awesome
Any idea about parameters such as noise offset in LoRA training on v4 zero?
0.0357 from my tests
@Madafada1991 Thanks, I'll try it!
What parameters & upscaler do you recommend me to use for HiResFix?
-- Hiresfix steps = total steps divided by two (for example,if there are 40 steps for generating original image, then it's 20 steps for hiresfix)
-- denoise strength - 0.4
--upscaler - remacri or superscale
or
-- Hiresfix steps = total steps divided by two (for example,if there are 40 steps for generating original image, then it's 20 steps for hiresfix)
denoise 0.65
upscaler: latent (antialiased)
animagine is always the best model for me!
Does this model support the following syntax?
prompt1 | prompt2 | prompt3,
[prompt1 | prompt2 | prompt3],
should we set clip to 2?
Clip skip wasn't relevant to SDXL since the beginning. If anything, usually generations are the same as clip skip 2.
@munchkin thanks for info!
very nice model but hope v5 can fix the bad anatomy...
does the model compaible with XL controlnets?
great model
I have created a realistic version of this model, if you like it you can add it to your page and I can delete my upload. You get 100% credit for the original amazing model! https://civitai.com/models/1378329
Strong in the relationship between people and the background!
what hires setting did you use?
like upscaler model, denoising strength, steps, and upscale by value.
also did this model model support danbooru artist name tag as a prompt?
After fine-tuning Animagine 4 Zero on a quality dataset, hands come out disfigured about 15 out of 25 times. As much as I respect the work on Animagine 3.1, NoobAI is still king for decent anatomy.
Skill issue. Did the same thing. 2 out of 15 are disfigured. https://civitai.com/posts/15031023
@kayfahaarukku skill issue? wdym?
@wktra If you set the training setting correctly and the dataset you use are really "quality", Then you will have no issue that you mentioned since I did the same thing with my personal model, UrangDiffusion 3.0. https://civitai.com/models/537384?modelVersionId=1542009
@kayfahaarukku My dataset is of superb quality because I handdrew and colored all 400 images myself. I;ve fintuned several checkpoints and Noobai gives the best results. If you want to share your settings for Onetrainer, be my guest.
@wktra I'm not using OneTrainer. I'm using kohya-ss. The settings used is similar to what the dev use.
Not trying to brag, but please look at the contributor list.
@kayfahaarukku okay, so you're going to make me go search for the dev settings to a training program that I don't use. I don't even know which devs you're talking about. The kohya devs?
Buddy, I'll tell you what part you played in the making of Animagine 4.0: pushing away a potential convert.
Maybe instead of blaming my incompetence, you should have just volunteered settings or training suggestions or even just asking about what training program I use.
Your approach will ASSURE Animagine gets buried. Congrats.
@wktra Sorry, after reviewing my words, I did sound rude. I deeply apologize. I have some problems happening IRL, it might have been interfere with my mood a lot.
For the training settings, any tool will work, if you follow the training configuration used listed on the description.
For LoRAs, you need 10 times the learning rate used, if you use more than 1 batch size, you have to use (Full training LR x 10 x batch size used.
I really sorry. I should go offline and clear my mind some days ago.
Hands down this is the best anime focused model. It even works pretty damn good for furry content.
This honestly is a solid competitor for NoobAI/illustrious.
More Loras should be trained for this model so people can see how incredibly versatile it can truly be
Does it have built-in artist styles?
@BlueberryTrain yes, it has. However, it isn't as extensive as NoobAI but artist tags work well with it
Incredible for textures
我不知道我的lora用什么大模型好,能不能帮帮我
帮帮他,施瓦罗先生!
great checkpoint!
is there a list of supported artist tags other than ciloranko used in prompting guide somewhere?
Any artist from danbooru that existed before january 2025 should work. Obviously the artists with more images will have a stronger/more accurate effect.
This is a very solid checkpoint, however the only reason i am not using it as much is because having to keep quality tags near the end is a pain if you like experimenting. Hopefully this is changed in a future version.
如果使用COMFYUI,你可以用來自COMFY-CORE的Concatenate節點幫你完成這件事
I still don't understand the "BILD" thing, but I'm happy that this model is available to the public.
The bid you mean?
The bidding system is simple, you put yellow buzz on the checkpoint, if at the end of the week the checkpoint is in the 200 highest bidder, the checkpoint is put on the site for generation for one week. If it's under you get your buzz back.
The bigger checkpoints usually make enough yellow buzz to sustain themselves on top. If you have the means you can put a bit of buzz on your favourite smaller checkpoint to help keep the lights on.
thank you for this explanation ..
... so it will be unusable again !!! 😭😭
Yep, unless some goof put 10k buzz on the checkpoint again this week. 😅
when I gave the buzz, it seems to me that it was rather around the 1000th ... very far from the top ... !!!!.
we'll try to take maximum of it while it's working.
Among all the best models aimed at anime/gaming, this is by far, the best database. Not only it has the details for characters be them from gacha games (ala Genshin, ZZZ, or WuWa), but it's also beautiful, and plays well with detailed prompts.
My only wish is that Cagliostro keeps improving on it, or other models increase their databases to match Animagine XL 4.0.
BEST DATABASE OUT THERE!
This was my 1st experience with LoRa and Models ~
This is truly an incredible model! I enjoy using the latest version.
It's genuinely one of the best I've seen for anime art, and the way it handles textures and the relationship between characters and backgrounds is truly amazing.
The database feels very strong, especially for gacha game-style characters.
My only constructive feedback would be to continue improving on the anatomy, particularly the hands. I hope a future version can address this and wish the creator art inspiration.
Thank you so much for your amazing work. This is a solid contender for one of the top anime models out there! 💖
hello i like your model are you going to do an illustrous version ?
There's a lora called "Animagine-like style for Pony Diffusion", you can ask TeamYellGrunt or someone else to make an Illustrious based LoRA which emulates the style of this Checkpoint model.
I'm new in the generative things. I'm trying things with fooocus. Why i keep having rainbow colors and abstract images with this checkpoint?
try using different sampler and scheduler
I used this model to train a LoRA using the same parameters as NoobAI, but the results are disappointing. The learned style doesn't look much like the training set. Is there anything specific I should look out for? I'm not sure where I went wrong
any rumours on v4.1? or animaestro 2B?
I like it! Ty ^^
🔥🔥🔥 damn, i've tried at least 40 sd, pony, ill, sdxl models
this is by far the BEST model when it comes to poses, very dynamic and varied it's INSANE!!!
every other model has the issue of the characters look as if they're posing for the camera, portrait basically, and prompting them for more dynamic poses would make them cycle between few and very similar fighting poses, they can't even do non action poses
it's also SFW by default, it won't generate NSFW content unless it is prompted to with 99% successes rate, again the only model that i've ever tested with this feature.
the only negative this model has is hands, the anatomy sometimes act funny but that's fine if you want this level of dynamic poses, but the hands kinda ruin it
i know this is an old model, but i really hope for an update that fixes the hands issue without messing with anything else since other than fingers this model is perfect
(maybe a bit of backgrounds too but that's not remotely necessary)